The AI community is fixated on benchmarks. Opus 4.7 scores 64.3% on SWE-bench Pro, up from 53.4%. It beats GPT-5.4's 57.7%. It resolves three times more production tasks on Rakuten's benchmark. On GPQA Diamond, it ties with GPT-5.4 Pro and Gemini 3.1 Pro at ~94%.
None of this is what matters.
What matters is a set of behavioral changes that barely made the announcement blog but fundamentally shift what's possible when you use a frontier model as the brain of an agent system. I've been running multi-agent production systems for over a year: 3,000+ hours in Claude Code, 11 agents in production, governance-first architecture from day one. Here's what I actually care about in Opus 4.7, and what it signals about where this field is heading.
The three changes that matter for production
1. File-based memory as default behavior
Opus 4.7 reads and writes scratchpad files as standard operating procedure. Between sessions, between tasks, between agent runs, the model maintains its own notes on the filesystem.
This sounds like a convenience feature. It's not. It's an architectural primitive.
My VNX Orchestration system (open source, governance-first runtime) is built entirely on filesystem-based communication. No database. Append-only NDJSON ledger. Decision receipts per dispatch. Context flows through files, not through API state or session memory.
When I designed this 12 months ago, the reasoning was straightforward: files are universal, versionable, inspectable, and vendor-agnostic. Any agent can read them. Any developer can audit them. Git gives you free versioning. grep gives you free search.
The fact that Anthropic's most capable model now natively adopts this pattern isn't a coincidence. It's convergent evolution. When you optimize for reliability over performance, filesystem-based state management keeps emerging as the answer.
What this enables at scale: Agent teams that maintain shared context without a centralized state server. Each agent reads the files it needs, writes its outputs, and the filesystem becomes the integration layer. No message queue. No event bus. No vendor lock-in. Just files.
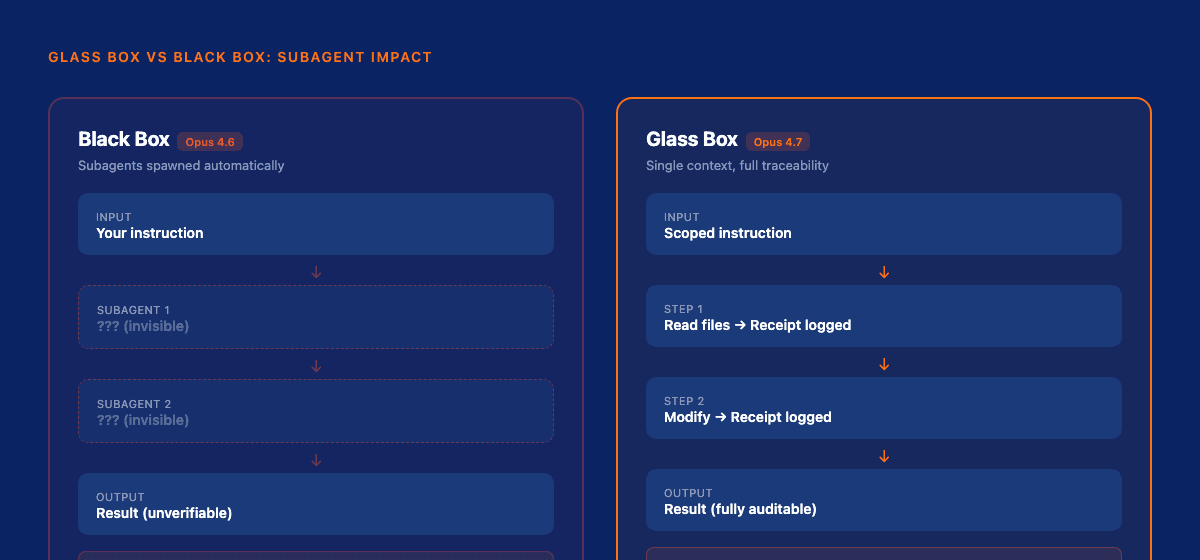
2. Reduced subagent spawning
Previous Opus versions had an aggressive tendency to decompose tasks into subtasks and delegate to subagents. You'd give it one instruction, and behind the scenes it would spawn three or four sub-processes: invisible, unauditable, uncontrollable.
Opus 4.7 does this less. Significantly less.
This is the single most important behavioral change for anyone running agents in production, and here's why: subagents are the antithesis of governance.
When a model spawns a subagent:
- You lose traceability. The decision chain breaks.
- Your quality gates get bypassed. The subagent doesn't know about your checkpoints.
- Token costs multiply unpredictably. One task becomes four or five.
- Error surfaces expand. A failure in a subagent cascades with no clear stack trace.
I've written extensively about the distinction between glass box and black box governance. Black box AI gives you input and output with nothing in between. Glass box AI gives you every decision, every intermediate step, every justification: auditable, traceable, correctable.
Subagent spawning turns a glass box system into a black box. The model takes autonomous action without your knowledge, creates processes you can't inspect, and returns results you can't fully verify.
Opus 4.7's reduced subagent behavior is a direct step toward glass box compatibility. The model tries harder to complete tasks within its own context, maintaining the traceability chain that governance requires.
3. Literal instruction adherence
Anthropic's announcement mentions this almost in passing: "pays precise attention to instructions." In their release notes, they even warn that older prompts may need re-tuning because the model now follows them more literally than intended.
Read that again. The model follows instructions so precisely that prompts designed for looser interpretation break.
For production agent systems, this is the shift from "good enough" to "reliable."
In my dispatch architecture, every agent receives a scoped instruction set:
- Which files to modify (and which to leave alone)
- What output format to produce
- What constraints to respect
- What quality thresholds to meet
With Opus 4.6, these instructions functioned as strong suggestions. The model usually followed them. Usually. But "usually" isn't a word you want in your production vocabulary.
With 4.7, instructions function as boundaries. "Edit only this file" means the model edits only that file. "Output in this format" means you get that format. "Do not modify files outside this directory" means those files are untouched.
Instruction adherence let me make capability scoping explicit instead of hopeful. I dropped --dangerously-skip-permissions in favor of an allowedTools allowlist per dispatch, with ambient MCP off, so a worker is handed only the tools its task needs. A year ago that allowlist would have leaked, the model would have routed around it. Now the boundary holds because the model treats it as one.
This is the foundation that makes everything else work. Guardrails only function if the model respects them. Governance scoring only means something if the model operates within its assigned trust level. Quality gates only hold if the model doesn't bypass them with creative interpretation.
The case for governance engineering
Here's the thesis: we're witnessing the emergence of governance engineering as a distinct discipline.
Not prompt engineering, which crafts the perfect instruction for a single interaction. Not even context engineering: building the right information environment for a model. Governance engineering: designing the constraints, boundaries, audit mechanisms, and trust frameworks that allow AI systems to operate reliably at scale.
The shift is driven by two converging forces:
1. Models are getting better at following instructions. This isn't incremental. Opus 4.7's instruction adherence means guardrails actually work. When you define a boundary, the model respects it. When you set a constraint, it holds. This makes governance enforceable, not aspirational.
2. Agent systems are moving from demos to production. Gartner reports a 1,445% increase in multi-agent system inquiries from Q1 2024 to Q2 2025. Gartner predicts 40% of enterprise applications will embed task-specific agents by end of 2026. Microsoft released an open-source Agent Governance Toolkit addressing all 10 OWASP agentic AI risks.
The infrastructure is materializing because the need is undeniable. You can't deploy autonomous agents without governance. And governance requires models that follow instructions.
Opus 4.7 is the first frontier model where governance engineering becomes viable. Not because Anthropic designed it for this purpose, but because its behavioral properties align with what governance requires.
What governance engineering looks like in practice
This isn't theoretical. I've been building this for a year. Here's what the architecture looks like:
Layer 1: Instruction scope Every agent gets a bounded instruction set. Files it can touch. Tools it can use. Output formats it must follow. With Opus 4.7, these boundaries hold. This is the PREPARE step in my current dispatch lifecycle: one instruction assembled from the skill body, a permission preamble, the task intelligence, and a report-contract directive, handed to the worker as a single scoped brief. The same PREPARE, GOVERN, RECEIPT lifecycle now runs identically across every worker lane, and the receipt it ends on is provider-aware and hash-chained, guaranteed even when a lane has to synthesize it from git facts.
Layer 2: Decision receipts Every agent decision produces an NDJSON receipt: what it decided, why, what inputs it used, what outputs it produced. Append-only. Immutable. Auditable.
Layer 3: Quality gates Between every phase, an async quality gate verifies the output meets defined criteria before the next agent picks up. No gate pass, no progress.
Layer 4: Governance scoring Each agent earns a trust score based on its track record. Higher trust = more autonomy. Failed quality gates reduce trust. The system learns which agents are reliable for which tasks.
Layer 5: Context rotation To prevent context degradation over time, automatic context rotation refreshes agent state while preserving essential knowledge through the file-based memory layer.
This architecture was possible before Opus 4.7. But it required constant compensating behavior: extra validation, defensive prompting, retry loops for instruction drift. With 4.7's behavioral improvements, the compensating layers can be thinner. The model does more of the work that governance frameworks had to enforce externally.

The critical perspective
It's not all upside. Three things to watch:
Tokenizer inflation. Opus 4.7 uses a new tokenizer that can map the same input text to 1.0-1.35x more tokens. Same price per token, more tokens per document. For high-volume production systems, this is a meaningful cost increase that Anthropic underemphasizes.
Instruction literalism cuts both ways. Stricter instruction following means less creative problem-solving when your instructions are underspecified. If your prompt says "fix this function" without specifying how, 4.6 might try three approaches. 4.7 might try one: the most literal interpretation. For agent systems with well-defined scopes, this is a feature. For exploratory coding, it can be a limitation.
Reduced cyber capabilities. Anthropic deliberately scaled back certain cybersecurity capabilities. For legitimate security researchers and penetration testers, this creates friction. The Cyber Verification Program exists, but it's another gate. This is responsible, but it signals that capability-gating per domain is Anthropic's strategy, and other domains may follow.
What this signals about the future
The trajectory is clear:
Models will continue to improve at instruction adherence. This is not a benchmark that plateaus. Every increment makes governance more viable, makes agent systems more reliable, makes production deployment less risky.
Governance becomes a competitive advantage, not compliance overhead. Organizations with mature governance frameworks report nearly 6x higher production success rates for AI projects. Governance isn't the tax on innovation. It's the accelerant.
The orchestrator model matters more than the worker models. In a multi-agent architecture, the brain (the model making dispatch decisions, enforcing scope, verifying output) determines system reliability. Worker agents can be cheaper models (Haiku, Sonnet). The orchestrator needs to be the most instruction-adherent, most reliable model available. Today, that's Opus 4.7.
File-based state will become a standard pattern. Not because it's the most sophisticated approach, but because it's the most auditable. When regulators ask "what did your AI system decide, and why?" the answer should be a directory of receipts, not a database query against ephemeral state.
The bottom line
Opus 4.7 isn't a breakthrough because of its benchmark scores. It's a breakthrough because it's the first frontier model whose behavioral properties (instruction adherence, reduced autonomous delegation, native file-based memory) align with what production governance requires.
The AI industry is shifting from building agents to operating them reliably. That shift demands governance engineering: the discipline of designing systems where AI operates within defined boundaries, every decision is traceable, and trust is earned through track record.
We're not in the era of smarter models anymore. We're in the era of more controllable ones. And controllability is what production demands.
Update: June 2026
Governance engineering stopped being a thesis and became the daily constraint. VNX reached 1.0 code-freeze, and the orchestrator-versus-worker split this post describes now has a hard cost driver behind it: Anthropic's June 15 billing move pushes headless claude -p onto paid API credits while interactive Claude Code stays on subscription, so the default worker lane is an ephemeral tmux-spawn window per dispatch. Feature design moved to a four-architect panel, codex, kimi, deepseek, and opus writing independent plans I synthesize, while the orchestrator brain stays a single instruction-adherent model, exactly the asymmetry I argued for here. The most governance-relevant lesson came from dogfooding that new lane: the worker sat idle because the instruction was pasted but never submitted, and my readiness check still watched for a "Welcome to Claude" banner that Claude Code v2.1.159 no longer prints, the kind of boundary failure you only catch by running your own default.
Read also: Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions: The architectural foundation that makes Opus 4.7's improvements actionable
For the Dutch perspective on how these changes affect day-to-day agent orchestration, see Opus 4.7 als orchestrator.
Sources: Anthropic: Introducing Claude Opus 4.7, The Decoder: Opus 4.7 coding and cyber capabilities, Microsoft: Agent Governance Toolkit, Gartner: Enterprise AI Agent Predictions, Lovelytics: State of AI Agents 2026, CIO: Agentic AI Reshaping Engineering
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.