Everyone is talking about multi-agent AI orchestration. How to make Claude, Codex, and Gemini work together. How to split tasks across terminals. How to scale from one agent to four.
Nobody is talking about what happens when it goes wrong.
I've been running multi-agent AI workflows daily for six months on my local system. Four parallel terminals. Claude Code and Codex CLI side by side. 2,472 dispatches processed. And the single biggest lesson I learned has nothing to do with orchestration. It's about governance.
The moment I lost trust
I started with multi-agent workflows in August 2025: basic terminal orchestration, Claude Code doing the heavy lifting. In those early months, I ran the system with auto-accept enabled: dispatches flowed from orchestrator to workers without manual confirmation. Three months in, I had what felt like a smooth-running setup. Terminal T0 orchestrating, T1 and T2 writing code, T3 running tests. One morning I woke up to find that an agent had refactored a module at 2am, triggered by a cascading chain of dispatches that started with a single hallucinated dependency. By the time I caught it, three files had been rewritten, tests had been "fixed" to match the new (wrong) behavior, and the git history showed clean commits with reasonable messages.
Everything looked fine. But I couldn't answer the most basic engineering question: which agent decided to do this, and why?
The chat logs were gone. Sessions had expired. Git showed what changed but not what prompted the change. There was no audit trail connecting the AI's decision to the action. No point where a gate could have caught the hallucination before it cascaded.
That incident ended the auto-accept era. I switched to mandatory human confirmation for every dispatch: a popup queue where nothing executes until I explicitly approve it. That has been the standard ever since. But switching to manual approval exposed a second problem: without structured receipts and quality gates, I was approving dispatches blind. I could say "yes" or "no," but I had no systematic way to assess whether the proposed work was safe.
That realization triggered three months of building governance infrastructure, first as ad-hoc scripts, then as a structured architecture. That architecture became VNX, and the remaining months of daily use (and the 2,472 dispatches it processed) shaped it into something I now trust enough to build real software with.
The governance gap nobody addresses
I evaluated every major multi-agent framework. LangGraph gives you excellent graph-based orchestration with checkpointing. CrewAI offers role-based agent teams with task guardrails. AutoGen provides flexible multi-agent conversations. Claude Agent Teams adds native lead-agent coordination. OpenAI Swarm delivers lightweight agent handoffs.
They all solve the orchestration problem well. What I couldn't find was a framework that treated governance (audit trails, quality gates, explicit human approval gates) as a first-class architectural concern rather than something you bolt on later.
This isn't a criticism of these tools. They're excellent at what they do. But orchestration without governance creates risk you can't measure. Industry surveys paint a similar picture: according to Camunda's 2026 State of Agentic Orchestration and Automation and its launch announcement, a large majority of organizations report a significant gap between their agentic AI vision and production reality. The primary blocker isn't technology. It's governance, auditability, and trust.
What I built: Glass Box Governance
I built VNX, not as a product, but as an architecture I needed to trust my own workflow. I call the approach "Glass Box Governance" because the core principle is: if you can't see inside it, you can't trust it at scale. This governance model is critical for production AI systems, and I've documented the full AI architecture and design patterns that support it.
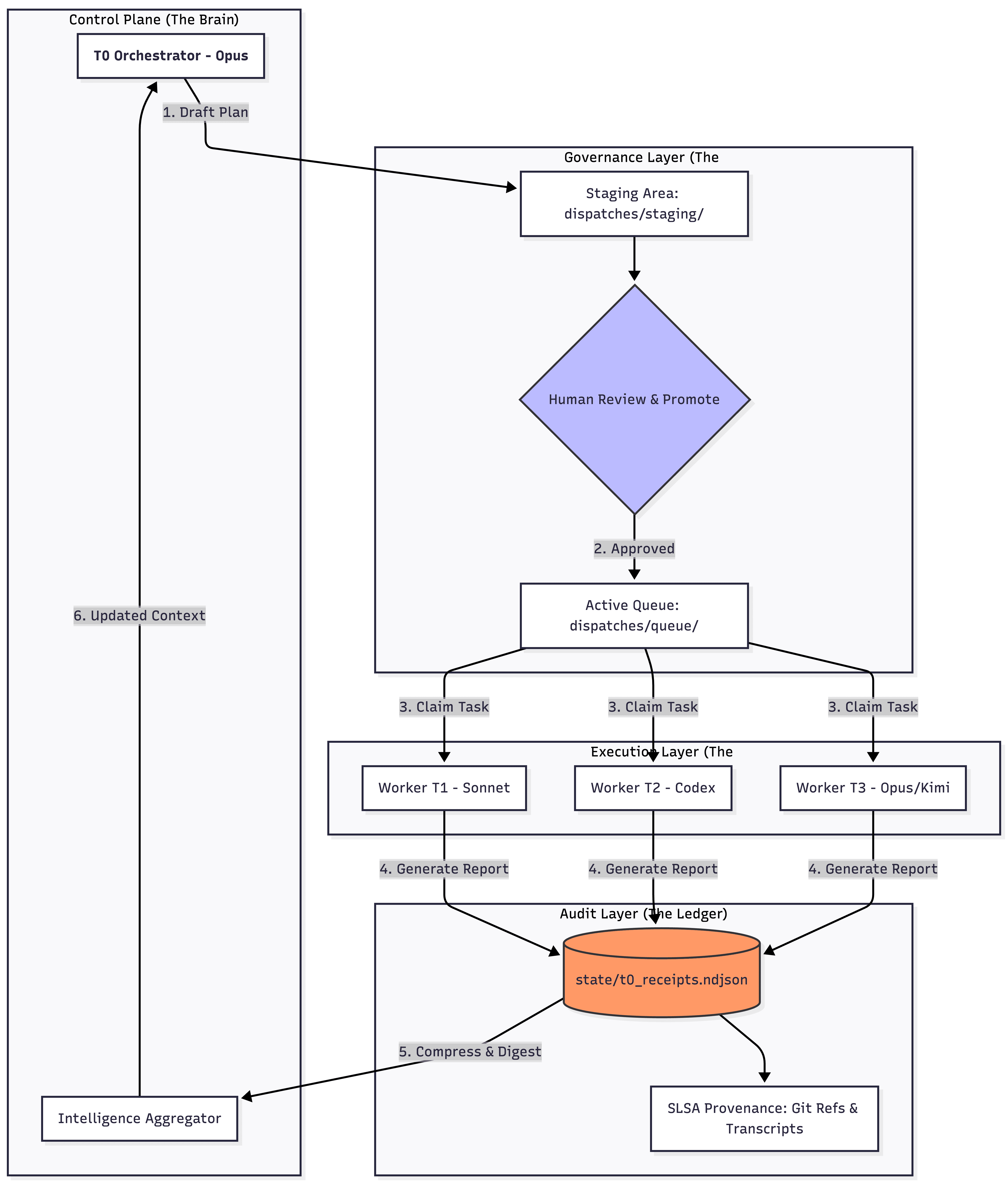
It rests on four pillars.
1. Receipts, not chat logs
Every agent action (task start, completion, failure, acknowledgment) writes a structured receipt to an append-only NDJSON ledger. Each receipt links the agent's decision to the concrete action: which terminal, which git commit, how long it took, what it cost.
Why NDJSON and not a database? Because simplicity is a governance property. NDJSON is crash-resilient (partial writes don't corrupt previous entries), streamable (tail -f works), and unix-native (grep, jq, awk all work out of the box). No database server to keep running. No migrations to manage. No schema versioning headaches. The ledger alone can reconstruct the system's complete history.
When something breaks during a long session, I replay the ledger. I don't read chat transcripts. I can grep for every action a specific terminal performed, filter by cost, or trace a dispatch from proposal to completion, all with standard unix tools.
The schema has grown since I started. Each receipt is now provider-aware: it carries which provider and model ran the dispatch alongside the token count and dollar cost, so I can slice the ledger by model and answer "what did Codex cost me this week" without leaving the terminal. The ledger is hash-chained and append-only, and a receipt is guaranteed for every dispatch. If a worker session ends without writing one, the lane synthesizes a receipt from git facts rather than losing the record. A session is never silently dropped.
Receipt (from t0_receipts.ndjson):
{"ts":"2026-02-14T09:12:44Z","terminal":"T1","dispatch":"PR-006","action":"complete","task":"Remove v4 compat layer","commit":"f476620","duration_s":1840,"cost_usd":0.34,"status":"ok"}Matching git commit:
$ git log -1 f476620
commit f476620
Author: T1 Worker <t1@vnx>
Date: Fri Feb 14 09:12:41 2026
refactor: Remove all Strapi v4 backward compatibility code2. Staging gates between "propose" and "execute"
This is the pattern that would have prevented my 2am cascade. VNX enforces human approval on every dispatch, but through two distinct paths.
For structured feature work, the orchestrator (T0) drafts a multi-track dispatch plan. A human reviews the scope: which files, what complexity, what risk. Only after explicit approval does the plan move to the active queue. Worker terminals claim their tracks and emit acknowledgment receipts.
For ad-hoc operational work (quick fixes, one-off commands) T0 can propose a dispatch directly, but every ad-hoc dispatch triggers a confirmation popup. There is no silent dispatch path.
A critical design detail: T0 cannot write files directly. It operates through hooks that restrict write actions, limiting it to coordination, planning, and dispatch creation. All code changes happen in worker terminals under the governance layer's oversight. This separation of concerns means the orchestrator physically cannot bypass its own gates.
I call the failure mode this prevents the "Cascade of Doom": one hallucinated output triggers downstream agent actions, each compounding the error, all looking reasonable in isolation. The two-path governance model breaks the chain at the first link.

3. Provider-neutral observation
Here's a problem most frameworks ignore: if your observability depends on provider-specific hooks, you're locked in. And hooks fail. They have latency. They don't exist for every provider.
VNX uses what I call the External Watcher Pattern, a dual-input bridge:
If a provider supports hooks, they can emit receipts directly. But for providers without hooks (or when hooks fail), VNX watches the filesystem for agent output reports and generates receipts from those. The watcher doesn't care if the output came from Claude, Codex, Gemini, or a shell script.
It physically cannot care, because every worker is a plain CLI subprocess and there is no vendor SDK anywhere in the codebase. The watcher reads output files, not provider APIs, so adding a model means adding a subprocess command and nothing in the orchestration layer changes.
This means I can use Claude for architecture work, Codex for implementation, Gemini for review, and swap models per-task without touching the orchestration logic. For production systems, understanding the top MCP protocols and their tradeoffs helps ensure you're using the right tool connectors. The next experiment on my list is adding Kimi 2.5 to further stress-test the watcher pattern across provider ecosystems. Hooks are optional enrichments, never dependencies.
4. Evidence-based closure
Every dispatch creates an open item: a registered expectation of what should be delivered. When a worker terminal completes a task, it must produce evidence: a structured report with specific metadata (terminal, timestamp, task ID, what changed, what was tested).
But VNX doesn't just check that evidence arrived. It checks what the evidence contains. Every completion receipt automatically triggers a quality advisory: file size analysis, function length checks, dead code detection (via vulture), and test coverage hygiene. The system generates a risk score and a deterministic decision (approve, approve with follow-up, or hold) and delivers that verdict to the orchestrator alongside the completion receipt.
T0 tracks these open items. A dispatch is only marked complete when matching evidence arrives and the quality advisory clears. No evidence, no closure. Evidence with blocking issues, no closure. The item stays open, visible in the queue, demanding attention.
This inverts the default assumption of most agent workflows. In a typical setup, a task is "done" when the agent says it's done. In VNX, a task is done when the system can verify the agent produced the expected deliverables to an acceptable standard. The agent's self-assessment is input, not verdict.
One critical aspect of long-running multi-agent workflows is managing context degradation. When agents run for hours without interruption, context rot silently kills performance: the agent's working memory degrades as the context window fills. VNX's receipt ledger makes this visible and traceable.
📖 Read also: My AI manager got worse the longer I talked to it: How context drift manifests in production orchestrators
How this compares to what exists
I'm not building in a vacuum. Several frameworks address parts of this problem. Aurauses append-only JSONL events with approval policies and multi-model support via Agno.SafeClawimplements deny-by-default gating with a SHA-256 hash chain for tamper detection.Camunda brings enterprise-grade BPMN/DMN gateways to agent orchestration.
But each solves a different slice. Aura is a self-contained agent framework, not middleware you add to existing tools. SafeClaw focuses on security gating for its own agent ecosystem. Camunda requires BPMN expertise and isn't designed for the agent-native developer workflow.
The gap I found: no existing system combines an append-only receipt ledger, explicit staging/promote governance gates, provider-neutral external observation, and evidence-based closure as a unified governance layer that works with whatever orchestration framework you already use.
VNX is designed as governance middleware. It sits between your agents and your codebase, regardless of which framework or model powers those agents. You could theoretically add VNX's governance patterns to a LangGraph pipeline, a CrewAI team, or a bare tmux setup. The receipt schema and governance lifecycle are the contracts. The implementation is secondary.
What I am (and what I'm not)
I should be transparent: I'm not a traditional systems engineer. I'm a product architect who saw the potential of AI agents and was frustrated by their lack of discipline. I didn't build VNX with AI to avoid coding. I built it for AI, to enforce engineering discipline on AI.
The prototype is Python and Bash. It runs on tmux. It's file-based and local-first. It has known limitations: tested with 4 terminals on a local system, T0 (the orchestrator) has only been tested with Claude Opus via Claude Code, which powers about 80% of my workflow. Other models may work as orchestrator, but that's untested. Gemini integration is validated but less battle-tested than Claude/Codex, and the public git history starts at the point where I separated VNX from the private product repository it grew out of.
I used AI to build the guardrails I needed for AI. And I believe the architecture, not the implementation language, is the contribution worth sharing.
Where this is going
After 2,472 dispatches, I see three shifts coming that most teams aren't preparing for.
Governance becomes the bottleneck, not orchestration.Everyone is racing to add more agents, more models, more parallelism. The orchestration tooling is keeping up. The governance isn't. Every additional agent multiplies the audit surface: more receipts, more decision chains, more potential cascades. Projects like ClawBot and OpenClaw are already showing that security and token governance at scale is brutally hard. The teams that figure out governance first will be the ones who can actually scale. This is especially critical forsmaller organizations adopting AI: they have fewer resources to recover from agent errors. The rest will hit a wall they didn't see coming.
Receipts become training data, not just audit trails. Right now, my ledger records what happened. But there's a more powerful use: feeding governance data back into the system. Pattern recognition across thousands of receipts: which dispatch types fail most often, which agents drift in scope, which context injections reduce hallucinations. VNX already does a version of this: 1,100+ learned patterns that automatically shape how dispatches are constructed and how context is injected. The next step is systematic: ML pipelines on governance ledgers (think BigQuery or Vortex) that surface insights no human reviewer would catch by reading receipts one at a time. The governance layer doesn't just record history. It learns from it.
Agents get more autonomous, governance must get proportionally smarter. The industry is pushing toward fully autonomous agents. I believe that's the wrong frame. The question isn't "how do we remove the human?" but "how do we make the human's oversight more effective as agent autonomy increases?" A human reviewing 10 dispatches per day can read each one carefully. A human reviewing 200 dispatches per day needs the system to surface the ones that matter. That's where intelligent governance comes in: risk scoring, anomaly detection, pattern-based flagging, all feeding into a human decision, never replacing it.
The common thread: whoever owns the governance data owns the intelligence. Receipts aren't bureaucratic overhead. They're the dataset that makes everything else smarter. The teams that treat governance as a first-class data asset, not a compliance checkbox, will have a structural advantage that compounds over time.
Update: June 2026
VNX has since reached 1.0 code-freeze: still a governance-first control-plane, not a product, and not yet on PyPI. The biggest shift is the worker lane. Anthropic's June 15 billing change moves headless claude -p to paid API credits while interactive Claude Code stays on subscription, so the default Claude worker is now an ephemeral tmux-spawn lane, a fresh interactive window per dispatch instead of a fixed pane. I learned to trust that lane only by dogfooding it: the first real task sat idle because the instruction was pasted into the prompt but never submitted, and my readiness check still watched for a "Welcome to Claude" banner that Claude Code v2.1.159 no longer prints. The receipt guarantee held through all of it, every dispatch still produces a hash-chained, provider-aware NDJSON receipt, even when the lane has to synthesize one from git facts.
The question I'm asking
After six months and 2,472 dispatches, I've come to believe that the multi-agent AI space has an infrastructure gap. We have excellent orchestration tools. We have powerful models. What we lack is the governance middleware to make agent workflows auditable, trustworthy, and production-safe.
So I'm putting the architecture and code out there (MIT-licensed, warts and all) because I think this conversation matters more than polish.
How are you handling governance for multi-agent workflows? Do you trust provider logs? Do you maintain your own flight recorder? Have you hit the cascade-of-doom yet: the point where orchestration works but you can't explain what happened?
If you're a systems architect or engineer who's experienced multi-agent chaos, I want to hear your approach. If you're interested in governance tooling for AI workflows, the architecture, schemas, and working prototype are open for discussion.
Because if you can't audit it, you can't scale it.
This post is part of the Glass Box Governance series.
Next: The Cascade of Doom: When AI Agents Hallucinate in Chains: What happens when one agent's hallucination triggers three more agents to "fix" it?
📖 Read also: Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail: The architectural case for log-shaped state in AI systems
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance ← you are here
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out)
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.