Every morning I open a terminal and start four AI agents. One is Claude Opus, the strategist. Two are Claude Sonnet, the builders. The fourth is Codex CLI, the specialist. None of them know the others exist. None of them need to.
From a single dashboard, I assign work, track progress, and review results across all four. When one finishes, I redirect its capacity to whatever needs attention next. When one produces something questionable, a quality gate catches it before I even look. The agents work in parallel, with separate context windows, and an orchestration layer connects them without any of them being aware of it.
This is how I've been building software for the past eight months. Not with one AI assistant, but with a coordinated team of them: different models, different providers, different strengths, all managed through an architecture I call VNX. The AI architecture principles behind this approach are rooted in the same transparency philosophy I apply to client work.
This post is the introduction to a series about what I've learned. Not just how to make agents work together, but how to make them work together safely. Because orchestration is the easy part. The hard part is everything that follows.

The setup: four terminals, three models, one brain
My daily development environment looks like this:
┌──────────────────────┬──────────────────────┐
│ T0 - ORCHESTRATOR │ T1 - WORKER │
│ Claude Opus │ Codex CLI / Sonnet │
│ Read-Only │ Full R/W │
│ Plans, dispatches, │ Any task assigned │
│ quality review │ by T0 │
├──────────────────────┼──────────────────────┤
│ T2 - WORKER │ T3 - WORKER │
│ Claude Sonnet │ Claude Opus │
│ Full R/W │ Full R/W │
│ Any task assigned │ Any task assigned │
│ by T0 │ by T0 │
└──────────────────────┴──────────────────────┘Terminal T0 is the brain. It sees everything but touches nothing; it's restricted to read-only operations. It can plan, analyze, and create dispatch instructions, but it physically cannot modify code. That constraint is deliberate. The orchestrator's job is to think, not to act.
Terminals T1, T2, and T3 are the workers. They're track-agnostic: any worker can handle any type of task. T1 might work on crawler code in the morning and storage optimization in the afternoon. T2 might switch from API development to test writing between dispatches. There are no fixed assignments.
This wasn't always the case. Early on, I ran a track-based system: T1 was "Track A" (crawler), T2 was "Track B" (storage), T3 was "Track C" (investigations). It seemed logical. It was also a bottleneck. If Track A had three urgent tasks and Track B had nothing, I couldn't redistribute work. T2 would sit idle while T1 was overloaded, and I was waiting for specific terminals to finish before dispatching the next task.
The shift to track-agnostic routing changed everything. Now T0 looks at which worker is available and dispatches the next task there, regardless of what that worker handled previously. The model matters more than the terminal: Opus for deep reasoning, Sonnet for fast implementation, Codex for specific code generation. The terminal itself is just a container. Any worker, any task.
How work flows through the system
Here's what a typical task lifecycle looks like:
Step 1: T0 creates a dispatch. The orchestrator analyzes the current state (what's in progress, what's blocked, what needs attention) and drafts a task. This becomes a structured dispatch with a priority level, role (architect, backend-developer, test-engineer), and specific instructions.
Step 2: A human reviews it. Every dispatch enters a staging queue. Nothing executes until I explicitly approve it. A popup appears with the dispatch details (what role, what scope, what files are involved). I review it, and either approve, modify, or reject it.
Step 3: The dispatch routes to an available terminal. Once approved, the dispatcher finds the next available worker, whichever terminal is idle. It resolves which provider is running there and adapts the dispatch format accordingly. The worker receives the task through its native interface.
Step 4: The worker does the job. The agent executes the task in its own context window, completely unaware of the orchestration layer. It reads files, writes code, runs tests, whatever the dispatch asks for. When it's done, it produces a structured report.
Step 5: Evidence is captured. An external watcher monitors the terminal output, extracts the report, and generates a receipt: a structured JSON record that links the task to the git commit, the model that performed it, and the time it took.
Step 6: Quality gates evaluate. Before anyone accepts the work, an automated quality advisory runs. It checks file sizes, function lengths, dead code, and test coverage. The result: approve, approve with follow-up, or hold.
Step 7: T0 reviews and closes. The orchestrator receives the receipt and quality verdict. Only T0 can declare work "done." The agent's self-assessment is input, not verdict. And the cycle repeats; that worker is now available for the next dispatch in the queue.

The agents don't coordinate. The system does.
This is the architectural choice that surprises people most. In my system, the agents never talk to each other. T1 doesn't know T2 exists. T3 has no idea what T1 is working on. There's no shared context, no inter-agent messaging, no collaborative reasoning between workers.
All coordination happens through the orchestrator (T0) and the file-based message bus. Dispatches flow down. Reports flow up. Receipts record everything. The agents are deliberately isolated.
Why? Because agent-to-agent communication is where cascades start.
If Agent A can trigger Agent B, and Agent B can trigger Agent C, you get compound errors. One hallucination becomes three rewrites, each building on the previous mistake. I learned this the hard way: at 2am, three agents collaboratively created a dependency that should never have existed. I tell that story in The Cascade of Doom.
Isolation prevents cascades. Each agent works in a sandbox. Its output goes through async quality gates before it affects anything else. If T1 hallucinates, the damage is contained. T2 and T3 are unaffected. The system catches the problem at the boundary, not after it's propagated. And when an agent's context window fills up, context rotation at scale preserves task state across session boundaries, so isolation doesn't come at the cost of continuity.
┌──── T1 (isolated) ────┐
│ Own context window │
│ Current task only │ Quality
│ No knowledge of T2/T3 │ ──► Gate ──► T0 reviews
└────────────────────────┘
┌──── T2 (isolated) ────┐
│ Own context window │
│ Current task only │ Quality
│ No knowledge of T1/T3 │ ──► Gate ──► T0 reviews
└────────────────────────┘
┌──── T3 (isolated) ────┐
│ Own context window │
│ Current task only │ Quality
│ No knowledge of T1/T2 │ ──► Gate ──► T0 reviews
└────────────────────────┘
Multi-model, not multi-vendor
Here's the practical reality of AI development in 2026: no single model is best at everything. Claude Opus reasons deeply but costs more and is slower. Claude Sonnet is fast and reliable for implementation. Codex CLI has strengths in specific code generation patterns. Gemini brings different perspectives to review tasks.
My system treats models as interchangeable components. The orchestrator doesn't care which model runs in which terminal; it cares about the output. The provider configuration lives in a single file:
{
"T0": { "provider": "claude_code", "model": "opus" },
"T1": { "provider": "codex_cli", "model": "codex" },
"T2": { "provider": "claude_code", "model": "sonnet" },
"T3": { "provider": "claude_code", "model": "opus" }
}Swapping T1 from Codex to Gemini means changing one field. The dispatch system adapts automatically; different providers have different skill invocation formats (/skill for Claude, $skill for Codex, @skill for Gemini), and the dispatcher handles the translation. The quality gates, receipt system, and orchestration logic stay identical.
This isn't theoretical flexibility. Last month I swapped T1 between Claude Sonnet and Codex CLI three times in a single week, depending on which type of work needed doing. The governance pipeline (receipts, quality gates, evidence tracking) didn't change at all. The receipts just recorded a different model in the session field.
Combined with track-agnostic routing, this means I have true flexibility on two axes: which modelruns where, andwhich task goes where. The orchestrator optimizes both: sending complex work to Opus terminals, fast implementation to Sonnet terminals, and keeping all workers busy regardless of what domain the task belongs to.
What keeps it honest: the receipt ledger
Every action across all four terminals writes a receipt to a single append-only file. One line of JSON per action. No exceptions.
{
"event_type": "task_complete",
"timestamp": "2026-03-01T14:22:08Z",
"terminal": "T2",
"status": "success",
"session": { "model": "sonnet", "provider": "claude_code" },
"provenance": { "git_ref": "a8f3e21", "branch": "main" },
"quality_advisory": { "decision": "approve", "risk_score": 0 }
}This receipt connects the AI's work to the git commit, the model that did it, and the quality assessment. When something goes wrong (and in eight months of daily use, things have gone wrong), I can reconstruct exactly what happened, which agent did it, and what the quality gate said about it.
The ledger is the system's memory. Not the chat logs (those expire). Not the git history (that shows what changed, not why). The receipt ledger shows the complete chain: dispatch, agent, action, evidence, verdict.
After 2,400+ dispatches, this file is my single most valuable debugging tool. I cover the format and design decisions in depth in Part 4: Why I Use a Plain Text File as My AI Audit Trail.
📖 Read also: Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail: the receipt format, Unix tooling, and why databases fail for append-only governance logs
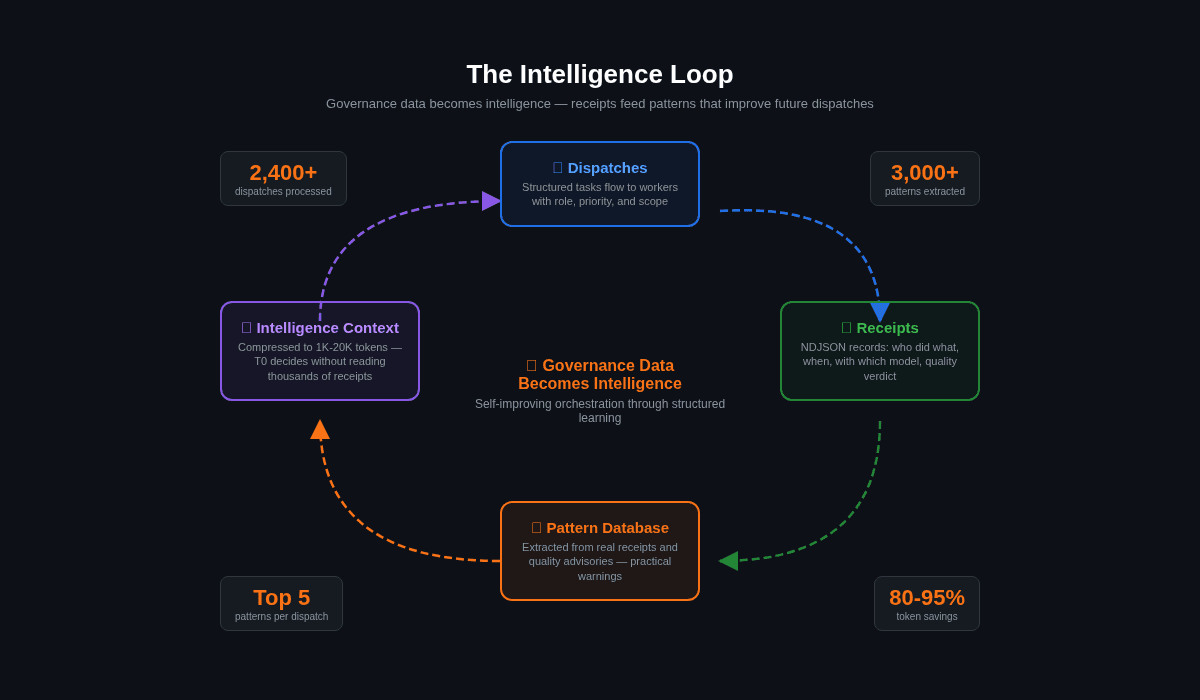
The intelligence layer: learning from 3,000+ patterns
The system doesn't just record; it learns. Over eight months, the receipt ledger and quality advisories have fed a pattern database of 3,000+ entries. Every time a dispatch goes out, the system queries the top 5 relevant patterns and injects them as context.
"Last time a task like this was dispatched, the agent produced an 847-line file that triggered a quality hold. Suggest splitting into two modules before starting."
This isn't AI learning in the machine learning sense. It's structured pattern matching on governance data. The patterns are extracted from real receipts and real quality advisories. They surface practical warnings: which types of tasks tend to produce oversized files, which dispatch descriptions correlate with scope drift, which roles have higher failure rates.
The intelligence aggregator compresses this into progressive context levels, from 1K tokens (quick glance) to 20K+ tokens (full analysis), so T0 can make decisions without reading thousands of receipts. Token savings: 80-95% compared to raw data.
What this looks like in practice
A typical morning session:
-
I run
vnx start. Four terminals open. The supervisor starts monitoring process health every 10 seconds. -
T0 loads its intelligence brief: a 2KB snapshot of system state. Queue depth, terminal availability, open items, recent patterns.
-
I tell T0 what needs to happen today. It drafts dispatches for each piece of work. Three popups appear in my queue.
-
I review each dispatch. One looks too broad; I narrow the scope before approving. The other two are fine.
-
Two dispatches go to whichever workers are available. T1 and T2 start in parallel. T3 gets a deep investigation task 20 minutes later.
-
T1 finishes first. It's immediately available for the next task in the queue, with no need to wait for "its track" to have work. The watcher captures its report. The quality advisory runs: approve. Receipt logged.
-
T2 finishes with a warning: a function exceeds the 70-line threshold. Quality verdict: approve with follow-up. T0 creates a follow-up dispatch. That dispatch could go to any available worker, including T2 itself or the now-idle T1.
-
T3's investigation reveals an architectural concern. It produces a detailed analysis. I read it, discuss next steps with T0, and plan the response as new dispatches, distributed across whichever workers are free.
All of this happens with me as the decision-maker at every gate. The system proposes, evaluates, and tracks. I decide.
📖 Read also: The External Watcher Pattern: how I observe agent behavior from outside the agent's context, without trusting its self-reports
Why I'm sharing this
I built VNX because I needed it. Running multiple AI agents without governance felt like driving without a dashboard: technically possible, dangerously uninformed. After the 2am incident where agents rewrote my codebase while I slept, I knew the missing piece wasn't better orchestration. It was accountability.
Each post in the Glass Box Governance series stands alone, but together they form the architecture behind what makes multi-agent workflows auditable, trustworthy, and production-safe.
If you're running one AI agent, you probably don't need any of this. If you're running two or more, especially from different providers, the governance gap will find you eventually. Better to build the dashboard before you need it than to reconstruct what happened from git logs at 3am.
This post is part of the Glass Box Governance series. The VNX architecture and prototype are available on GitHub.
Previous: Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail Next: Claude Agent Teams vs. Building Your Own
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other ← you are here
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out)
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.