Your AI agent can follow instructions. Can it make decisions?
That question sounds philosophical. It isn't. It's architectural. And the answer determines whether your multi-agent system is a productivity tool or a liability waiting to surface.
Most agent frameworks treat this distinction as irrelevant. CrewAI gives agents "roles" and lets them collaborate. AutoGen lets agents have "conversations" that converge on solutions. LangGraph chains agents in directed graphs. All of them conflate two fundamentally different operations: executing a task and making a decision about what to do.
In VNX Orchestration, these are architecturally separated. And that separation is the single most important design decision in the entire system.
The Problem: Agents That Decide Without Authority
Here's what happens in most multi-agent systems when an agent encounters ambiguity:
- Agent receives a task: "Write a blog post about AI governance"
- Agent decides the angle, the structure, the tone, the length
- Agent decides which sources to cite
- Agent decides when it's done
- Agent delivers the result
That's five decisions disguised as one task. The framework treats them all as execution. But decisions 2 through 4 are judgment calls that directly affect output quality, brand consistency, and factual accuracy.
When the output is wrong (and it will be) you can't trace which decision caused the failure. Was it the angle? The sources? The self-assessment of completion? You don't know. The agent made all those decisions internally, with no governance, no constraints, and no receipts.
This is not a prompt engineering problem. It's an architecture problem.
Task Execution vs. Decision Making
Let me define the distinction clearly:
Task execution is deterministic work within defined constraints. "Write 1500 words about X, using sources A, B, and C, in the style defined by document Y." The agent has no decisions to make, only work to do.
Decision making is choosing between alternatives when the outcome matters. "Should this blog target developers or business owners?" "Should I cite this source or find a better one?" "Is this output good enough to ship?"
In most frameworks, agents do both simultaneously. In VNX, they don't.
The VNX Decision Architecture
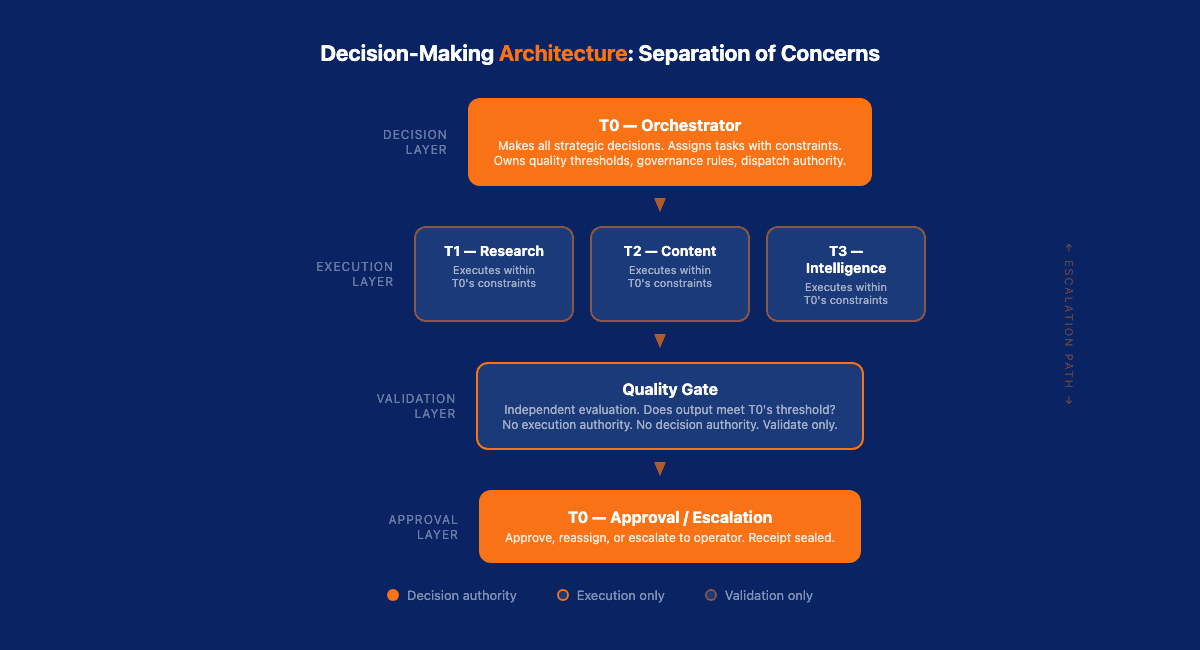
VNX Orchestration uses a tiered terminal model where decision authority is explicitly separated from task execution:
T0 (Orchestrator): Makes all strategic decisions. What gets dispatched, to which terminal, with what constraints, and what quality threshold applies. T0 is the only entity with decision authority.
T1-T3 (Execution Terminals): Execute tasks within the constraints set by T0. They don't decide what to work on. They don't decide when they're done. They don't decide if their output is good enough.
Quality Gates: Independently evaluate outputs against the criteria T0 specified. The quality gate doesn't execute tasks or make strategic decisions. It answers one question: does this output meet the threshold?
This creates a clean separation:
T0 decides → Terminal executes → Quality gate validates → T0 approvesNo entity in this chain does more than one job. The terminal can't approve its own work. The quality gate can't reassign tasks. T0 can't skip validation. Each role is constrained by architecture, not by prompts.
Why This Matters in Production
In a toy demo, agent self-governance works fine. The stakes are low. The worst that happens is a mediocre output.
In production, the stakes compound. I run 11 agents across four terminals, producing real content, real intelligence reports, and real business decisions. When an agent makes a bad decision, the downstream effects are concrete:
- A blog post with a wrong statistic gets published
- A content calendar entry targets the wrong audience
- An intelligence summary misses a critical signal
- A cost allocation receipt records the wrong amount
Each of these is a governance failure, not a model failure. The model did exactly what it was asked to do. The problem is that nobody asked the right question, or nobody checked the answer.
How Other Frameworks Handle (or Don't Handle) This
CrewAI: Role-Based, No Decision Governance
CrewAI assigns agents "roles" with descriptions and goals. A "Research Analyst" agent knows it should research. A "Content Writer" agent knows it should write. They collaborate by passing outputs between roles.
Here's a typical CrewAI setup:
researcher = Agent(
role="Research Analyst",
goal="Find comprehensive data on {topic}",
backstory="You are a senior research analyst...",
allow_delegation=True
)
writer = Agent(
role="Content Writer",
goal="Write engaging content based on research",
backstory="You are a skilled content writer..."
)
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential
)The problem is visible in the code: every agent makes its own decisions about quality, completeness, and approach. The goal is a suggestion, not a constraint. There's no independent validation step between research_task and writing_task. Agent A decides its research is sufficient. Agent B decides its writing is good enough. Nobody checks either decision. You can add human_input=True to a task, but that's a manual gate, not architectural governance.
AutoGen: Conversation as Decision-Making
AutoGen uses multi-agent conversations where agents discuss and converge on solutions. This is elegant for brainstorming. It's dangerous for production decisions.
A typical AutoGen pattern looks like this:
assistant = AssistantAgent("assistant", llm_config=llm_config)
critic = AssistantAgent("critic", llm_config=llm_config,
system_message="Review the assistant's work for accuracy...")
groupchat = GroupChat(
agents=[assistant, critic, user_proxy],
messages=[],
max_round=10
)The critic agent appears to provide validation. But it's using the same model with the same training data and the same biases. When the assistant produces a plausible-sounding but factually wrong analysis, the critic, running on the same LLM, tends to agree. Conversations create the illusion of validation without the substance. Two yes-votes from similar models aren't independent validation. In VNX, the quality gate uses explicitly defined criteria, not another agent's opinion.
When I do want several models in the loop, I make them genuinely independent. Feature design now runs through a four-architect panel, codex, kimi, deepseek, and opus, each writing its own plan in isolation before I synthesize them. Four models with different training and different blind spots catch what one model, or one model critiquing itself, never will. That is the structural point: independence has to be designed into the architecture, it does not emerge from a conversation.
LangGraph: Graph-Based, Decision-Agnostic
LangGraph lets you build directed graphs of agent interactions. You control the flow. But the graph defines sequence, not authority. Node A runs before Node B, but who decided Node A's output was good enough to pass to Node B?
graph = StateGraph(AgentState)
graph.add_node("research", research_agent)
graph.add_node("write", write_agent)
graph.add_edge("research", "write")This graph guarantees execution order. It does not guarantee decision quality. You can add conditional edges that check output quality, but LangGraph doesn't provide this by default: you have to build it yourself. And most teams don't, because the framework's mental model is about flow, not governance. Unless you explicitly build decision nodes with independent validation into your graph, LangGraph gives you execution order without decision governance.
The Dispatch Model: Decisions as First-Class Events
In VNX, every decision T0 makes is a traceable event. The dispatch record captures not just what was decided, but why:
{
"dispatch_id": "D-4835",
"decision": {
"type": "assignment",
"target_terminal": "T2",
"rationale": "content_task_type_match",
"constraints": {
"quality_threshold": 0.75,
"governance_rules": ["G-L6", "G-L7"],
"max_iterations": 3,
"style_document": "tone-of-voice.md"
}
}
}The terminal receives this dispatch with all constraints pre-defined. It doesn't decide the quality threshold. It doesn't decide which governance rules apply. It executes within the box T0 drew.
If the output fails the quality gate, it doesn't go back to the terminal for self-correction. It goes back to T0 for a new decision: adjust constraints, reassign to a different terminal, or escalate to the operator.
This is routing as architecture, not as afterthought. Every decision in the system has an owner, a record, and a validation path.
The Escalation Pattern
The most important decision an agent can make is deciding not to decide.
In VNX, terminals have an explicit escalation mechanism. When a terminal encounters ambiguity (a task that doesn't match its constraints, an output that feels uncertain, a conflict between instructions) it doesn't guess. It escalates.
Escalation creates a new dispatch event:
{
"type": "escalation",
"source_terminal": "T2",
"reason": "ambiguous_instructions",
"detail": "Task references governance rule G-L9 which does not exist in current ruleset",
"suggested_action": "clarify_rules_or_reassign"
}This is the opposite of what most frameworks do. Most frameworks encourage agents to be resourceful: to figure it out, to try harder, to be creative. That's exactly the behavior that causes production failures.
An agent that escalates appropriately is more valuable than an agent that guesses confidently. Confidence without authority is how cascading failures start.
Building Decision Architecture Into Your System
If you're designing a multi-agent system, here are the architectural principles that make decision governance possible:
1. Separate who decides from who executes. No entity should do both. If your agent decides what to do and then does it, you have no governance. Split the roles.
2. Make decisions traceable. Every decision should produce a record: who decided, what was decided, why, and what constraints applied. This is the receipt pattern.
3. Validate independently. The entity that validates output should be different from the entity that produced it. Self-assessment is not validation. Use async quality gates that evaluate against explicit criteria.
4. Design for escalation. Give your agents a clear path to say "I don't know" or "this doesn't match my constraints." Make escalation a first-class event, not a failure mode.
5. Constrain before execution. Don't let agents discover their constraints during execution. Define quality thresholds, style guidelines, governance rules, and output formats before the task starts. The dispatch carries the constraints. Capability is a constraint too: I dropped --dangerously-skip-permissions in favor of an explicit allowedTools allowlist per dispatch, with ambient MCP off, so a worker can only touch the tools its task actually needs. The architecture decides what the agent may do before the agent decides anything.
The Cost of No Decision Governance
Theory is useful. A production incident is more convincing.
In February, I was reviewing a content pipeline for a client who was using a multi-agent setup without decision separation. Their system had two agents: a research agent and a writing agent. The research agent gathered sources, the writing agent produced blog posts. No independent quality gate. No decision traceability. The writing agent decided when it was done.
For three weeks, this system produced content that looked fine on the surface. Then a reader flagged a blog post that cited a study with fabricated statistics. The research agent had hallucinated a source (a common failure mode) and the writing agent had no mechanism to verify citations independently. It incorporated the fake source because that was its job: write based on what research provides.
The real cost wasn't the single bad article. It was the investigation afterward. Without decision traceability, the client couldn't determine how many other articles might contain hallucinated sources. They had to manually review every piece of content the system had produced: 47 blog posts over six weeks. That review took 30+ hours of human time.
With decision governance, this failure would have been caught in two ways: an independent quality gate that cross-references cited sources, and a traceability chain that would have let them query "show me all articles where the research agent cited sources not in the approved source list." Instead, they got a manual review, a loss of reader trust, and a system they no longer felt confident running unattended.
The cost of no decision governance isn't measured in the failure itself. It's measured in the trust you lose, both in the system and from the people who depend on its output.
The Counter-Argument: Isn't This Too Rigid?
Yes, if your system is a chatbot that answers customer questions. No, if your system runs autonomously and produces outputs that affect your business.
The level of governance should match the level of autonomy. An agent that waits for human input on every step needs minimal decision governance. An agent that runs at 3 AM and publishes content needs maximum governance.
I've written about this spectrum in the context of human-on-the-loop graduation. New agents start with tight constraints and earn autonomy through demonstrated reliability. The governance doesn't loosen because I want it to. It loosens because the evidence supports it.
Decisions Deserve Architecture
Instructions tell an agent what to do. Architecture tells it what it's allowed to decide.
The systems being built today (autonomous pipelines, multi-agent workflows, AI-powered business processes) need both. And the frameworks that treat decision-making as an implicit part of task execution are building on a foundation that can't support production loads.
Every decision in your system should have an owner, a record, and a validation path. Not because governance is a nice-to-have. Because decisions without governance are risks without receipts. For how I build governed AI systems for clients, see AI architecture & agents.
Update: June 2026
VNX reached 1.0 code-freeze since I wrote this, and the decide/execute split held under a billing change. Anthropic's June 15 move pushes headless claude -p onto paid API credits, so the default Claude worker is now an ephemeral tmux-spawn lane, a fresh interactive window per dispatch, and the dispatch lifecycle is uniform across every lane: PREPARE sets the constraints, GOVERN validates the contract report, RECEIPT writes a hash-chained, provider-aware entry, guaranteed even when a lane synthesizes one from git facts. The clearest decision-governance lesson of the quarter came from dogfooding that new lane: the first task sat idle because the instruction was pasted but never submitted, and my readiness check still watched for a "Welcome to Claude" banner that Claude Code v2.1.159 no longer prints. The worker did not guess its way past the ambiguity, it surfaced as a stalled, visible dispatch, which is exactly the behavior this post argues for.
Read also: Routing Is Not Orchestration: Why OpenClaw's Architecture Misses the Point: the distinction between moving tasks and governing workflows.
Read also: Async Quality Gates: Why Every AI Agent Output Needs Independent Validation: the validation layer that makes decision governance enforceable.
Sources: CrewAI Documentation, AutoGen Documentation, LangGraph Documentation
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out)
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions ← you are here
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.