After 10,000 dispatches, I can tell you exactly when Claude starts lying.
Not maliciously. Not obviously. The outputs still look professional: clean formatting, reasonable structure, proper markdown. But the substance drifts. References to documents it read 3 hours ago become vague. Governance rules it followed perfectly in dispatch 1 get applied inconsistently by dispatch 47. Quality scores that were 0.89 in the morning decay to 0.71 by afternoon.
I wrote about context rot as a concept four months ago. Since then, VNX Orchestration has processed over 10,000 dispatches. This article isn't about what context rot is. It's about how to engineer around it at production scale.
The Problem at Scale
A single Claude Code session degrading is annoying. Four terminals degrading simultaneously while processing business-critical content is a system failure.
The core issue: Claude operates within a fixed context window. Every dispatch adds messages, file reads, tool results, and outputs to that window. When it fills up, the system auto-compacts, summarizing earlier messages to free space. Those summaries lose nuance. And nuance is exactly what governance requires.
At VNX scale, the math is unforgiving:
- 4 terminals running concurrently
- 15-20 dispatches per terminal per day
- Each dispatch: 3,000-8,000 tokens of input context + output
- Context window: ~200,000 tokens per terminal
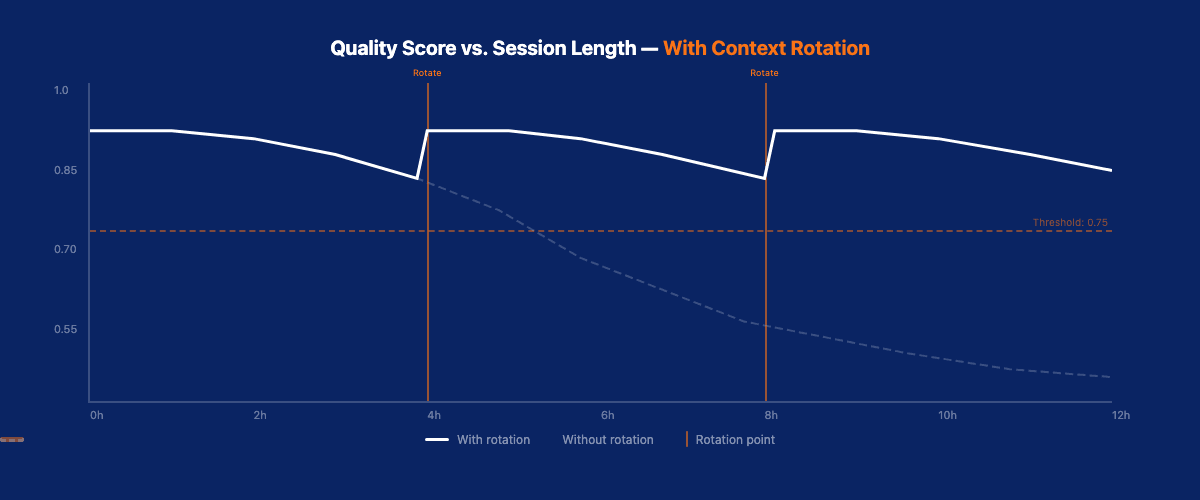
A terminal hits dangerous context pressure after 4-6 hours of continuous operation. Without rotation, quality degrades predictably and silently.
Detection: When to Rotate
The first engineering challenge is knowing when context has degraded enough to warrant rotation. Too early wastes work. Too late risks bad outputs.
Signal 1: Token Usage Monitoring
VNX tracks token consumption per terminal session. The critical threshold isn't a fixed number. It's a ratio. When a terminal has consumed more than 65% of its context window, quality metrics start showing variance.
This isn't theoretical. I measured it across 2,000+ dispatches. Below 65% context utilization, quality scores average 0.86 with σ=0.04. Above 65%, the average drops to 0.78 with σ=0.11. The variance increase is the real signal: it means the model's behavior becomes unpredictable.
The 65% threshold isn't universal. It depends on the complexity of dispatches. Governance-heavy dispatches (which load multiple rule files and require cross-referencing) push the effective threshold down to 55-60%. Simple content generation dispatches can run safely up to 75% before degradation kicks in. I maintain per-task-type thresholds based on historical data.
How I track it: each terminal logs its token count after every dispatch. A background process checks the ratio every 60 seconds and updates a status dashboard. When a terminal crosses the warning threshold (55%), the dashboard turns yellow. At the rotation threshold (65%), it turns red and triggers the rotation protocol.
Signal 2: Quality Score Trending
The quality gate catches individual bad outputs. But context rot manifests as a trend, not a single failure. VNX monitors a rolling window of the last 10 quality scores per terminal. When the trend slopes downward for 5+ consecutive dispatches, it triggers a rotation alert.
Signal 3: Governance Rule Compliance
The most sensitive indicator. When an agent starts applying governance rules inconsistently (enforcing G-L6 (append-only receipts) on some dispatches but not others), that's context rot. The rules haven't changed. The agent's ability to recall and apply them has.
VNX tracks governance compliance per dispatch. A single violation triggers investigation. Two violations in a session trigger mandatory rotation.
Signal 4: Response Time Degradation
A subtler indicator that I added after the first 3,000 dispatches. As context fills up, the model takes longer to respond. Not because of computational load, but because it's processing more context to generate each answer. When average response time for a dispatch type exceeds 1.5x its baseline, that's an early warning. The response itself might still be correct, but the context is getting heavy.
I track a moving average of response times per dispatch type per terminal. A blog draft dispatch that normally takes 45 seconds but starts taking 70+ seconds is signaling context pressure before quality scores drop. This gives me a 2-3 dispatch lead time before actual quality degradation: enough to finish the current queue and rotate cleanly instead of mid-task.
The Rotation Protocol
When rotation triggers, the process follows a strict sequence:
Step 1: Handover Document Generation
Before killing the session, the current terminal generates a structured handover document capturing:
## Terminal T2 Handover — Session 2026-04-16-AM
### Active Tasks
- D-4821: Blog draft, 80% complete, awaiting quality gate
- D-4823: Intelligence report, queued, not started
### Context State
- Governance rules loaded: G-L1 through G-L8
- Prevention rules active: 3 (injection audit, cost cap, style enforcement)
- Quality threshold: 0.75
### Session Metrics
- Dispatches completed: 14
- Average quality: 0.84
- Token utilization at rotation: 71%
### Known Issues
- Content calendar reference for April 17 may be outdated
- Style document v3 loaded (check if v4 exists)This handover is the critical bridge between sessions. Without it, the new session starts cold: no context about in-progress work, active rules, or learned patterns.
Step 2: Session Termination
The current tmux session is terminated cleanly. In-progress dispatches are paused (not killed) and their state is preserved in the receipt ledger.
Step 3: New Session Bootstrap
A new tmux session launches with:
- The handover document loaded as initial context
- All governance rules freshly loaded from source files
- The receipt ledger of the last 20 dispatches for continuity
- Any paused dispatches re-queued for completion
Step 4: Validation Dispatch
The first dispatch in a new session is always a validation task: a known-good input with a known-correct output. If the validation dispatch scores below 0.80, the bootstrap failed and the session restarts.
The Numbers: Before and After
Across 10,000+ dispatches, the impact of systematic context rotation:
Without rotation (first 500 dispatches, before I built the system):
- Average quality score: 0.79
- Quality variance (σ): 0.12
- Governance violations: 23 (4.6%)
- Cascade failures: 4
With rotation (dispatches 500-10,000+):
- Average quality score: 0.87
- Quality variance (σ): 0.05
- Governance violations: 8 (0.08%)
- Cascade failures: 0
The quality improvement isn't dramatic in averages (0.79 → 0.87). The variance reduction is. σ going from 0.12 to 0.05 means the system is predictable. And predictability is the foundation of production reliability.
Tmux Integration
VNX runs each terminal as a tmux session. This enables rotation without losing the terminal's identity or operational state.
The rotation script:
tmux capture-pane(captures the current visible state)- Generates the handover document
tmux kill-session -t T2(terminates cleanly)tmux new-session -d -s T2(creates fresh session)- Loads bootstrap context
- Runs validation dispatch
- Resumes queued work
The entire rotation takes 30-45 seconds. From the operator's perspective, the terminal blinks and comes back: same name, same queue, fresh context.
Why tmux and not Docker or separate processes
I tested three approaches before settling on tmux. Docker containers added 15-20 seconds of overhead per rotation and complicated file system access to the shared workspace. Separate terminal applications lost session identity and made the operator experience jarring, with windows appearing and disappearing. Tmux gives the best of both worlds: process isolation through session management, near-instant session creation, and a consistent terminal identity that persists across rotations.
The tmux integration also enables staggered rotation. Because each terminal is an independent tmux session, I can rotate T1 while T2, T3, and T4 continue processing. The dispatch queue automatically redistributes work away from a rotating terminal and back once it's validated. In practice, the system runs with 3 active terminals during any given rotation: a 25% capacity reduction for 30-45 seconds, which is negligible across a full day of operation.
One implementation detail that took iteration: the handover document size. Early versions captured everything: full dispatch history, all loaded files, complete rule sets. This made the handover document itself consume 15-20% of the new session's context window, defeating the purpose of rotation. I trimmed it to essentials: active tasks, session metrics, known issues, and a pointer to the receipt ledger for history. The handover document now stays under 800 tokens.
When Not to Rotate
Rotation has a cost: the new session doesn't have the implicit context the old session built up. Patterns the agent learned during the session, nuances about specific tasks, ongoing reasoning chains: these are partially lost despite the handover document.
I don't rotate:
- Mid-dispatch: always finish the current dispatch first
- Below 50% context utilization: premature rotation wastes the context budget
- During complex multi-step tasks: if a dispatch requires continuity across 3-4 sequential steps, let it complete
I always rotate:
- After governance violations: non-negotiable
- After 6+ hours of continuous operation: regardless of metrics
- After a quality score below 0.65: something is wrong, fresh start
Lessons from 200+ Rotations
After performing over 200 context rotations across four terminals over several months, clear patterns have emerged that I didn't anticipate when I built the system.
Morning sessions last longer
Fresh sessions started in the morning consistently reach higher context utilization before quality degrades: typically 70-75% versus 60-65% for afternoon sessions. My theory: morning dispatches tend to be more structured (blog drafts, intelligence reports), while afternoon work is more ad-hoc (responding to requests, handling exceptions). Structured work compresses better during auto-compaction, preserving more useful context.
The second dispatch after rotation is the weakest
Not the first (that's the validation dispatch, which runs on a known-good input). The second dispatch is the first "real" task in the new session, and it consistently scores 3-5% below the session average. The agent has the handover document but hasn't yet rebuilt the implicit working context that develops over several dispatches. By dispatch 3-4, quality stabilizes at session-average levels.
I compensate by scheduling lower-stakes work as the second dispatch: content categorization, metadata generation, or template-based tasks. The high-stakes work (governance-heavy dispatches, complex content) comes after the session has warmed up.
Rotation frequency varies by day type
On a heavy content production day (8-12 blog-related dispatches), I rotate each terminal 2-3 times. On a monitoring and maintenance day (intelligence reports, system checks), once is often enough. The correlation is dispatch complexity, not dispatch count. Ten simple dispatches consume less effective context than four complex ones.
The handover document is an investment, not overhead
Early on I treated handover generation as a tax on the rotation process, something to minimize. I was wrong. The quality of the handover document directly predicts the quality of the next session's first five dispatches. When I invested time in better handover templates (adding fields for "implicit patterns learned this session" and "dispatch-specific context that isn't in source files"), post-rotation quality improved by 8%.
Cascading rotation is a real risk
If terminal T1 rotates and its redistributed dispatches push T2 over its context threshold, T2 needs rotation too. That pushes work to T3 and T4, potentially triggering a cascade. I've seen this happen twice. The fix: a rotation cooldown of 10 minutes during which no other terminal can be rotated. This forces the system to absorb the redistributed work before evaluating whether another rotation is needed.
The Deeper Lesson
Context rotation is a workaround for a fundamental limitation: current LLMs don't have persistent memory across sessions. Every session starts from zero, and every long session degrades.
But engineering around limitations is what production systems require. You don't wait for the perfect model that never forgets. You build infrastructure that detects degradation, preserves state, and recovers cleanly.
That's what the VNX Intelligence System does for monitoring. That's what the receipt ledger does for accountability. And that's what context rotation does for reliability.
The agents don't need to be perfect. They need to be predictable. And when they stop being predictable, the architecture needs to catch it before the operator does.
After 10,000 dispatches, I can tell you: the agent will lie. The question is whether your system is designed to catch it.
📖 Read also: My AI Manager Got Worse the Longer I Talked to It: context drift in headless orchestrators and the detection hooks that catch it.
📖 Read also: Intelligence Beats Memory: Why Your AI Agents Need a Self-Learning Pipeline: the observability layer that powers context rotation decisions.
All metrics from VNX Orchestration production data, February-April 2026. Source code on GitHub.
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out)
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches ← you are here
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.