Seventy-nine percent of organizations surveyed by PwC have deployed AI agents. Most of them cannot trace a failure through a multi-step workflow. According to PwC's 2025 Agent Survey, the gap between deploying an agent and understanding its production behavior is now one of the most critical infrastructure problems in AI.
I spent six months staring at that exact problem. My system had 31 patterns in its database, every single one with a used_count of zero. Zero adoption. Zero learning. The intelligence layer existed in schema only: a feedback loop that was never closed.
This is the story of how I fixed it, and what Toyota, Netflix, and banking taught me along the way.
The Before: An Open-Circuited Feedback Loop
Here's what my intelligence database looked like in December 2025:
pattern_usage: 31 rows — used_count=0, ignored_count=0, confidence=1.0 (ALL rows)
session_analytics: 0 rows
t0_recommendations: {"total_recommendations": 0}
prevention_rules: 0 rowsThe schema was there. The tables existed. The code to read patterns existed. But nothing in the system ever called record_pattern_offer() or record_pattern_adoption(). The feedback loop was open-circuited: data went in, but nothing came back.
My worker agents (T1-T3) had no intelligence injection hook at all. They dispatched blind, with no context about what had worked or failed before. The kind of blindness that leads to cascading hallucinations: one agent's bad output becoming the next agent's input.
The root cause was embarrassingly simple: I built the infrastructure before closing the loop. The database, the tables, the queries: all there. The two function calls that would have connected them: missing.
The Architecture: 22 Scripts, One Feedback Loop
The fix wasn't one script. It was 22: 15 Python modules and 7 shell scripts, plus a 12-phase nightly pipeline that ties them together. All part of VNX Orchestration, the open source system that runs my production agents. Every script exists because a specific failure mode demanded it.
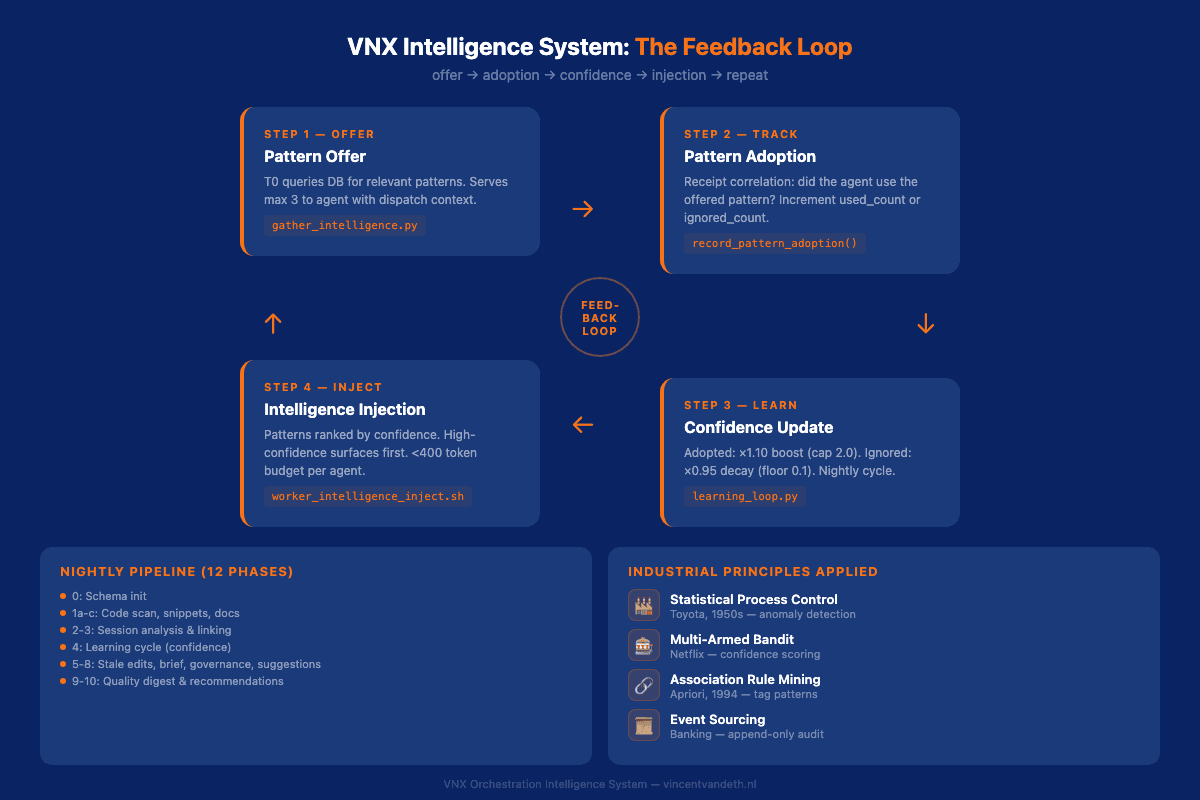
Here's the core loop:
-
Pattern Offer: When T0 creates a dispatch,
gather_intelligence.pyqueries the database for relevant patterns and serves them to the agent. Every offer is logged tointelligence_usage.ndjson. -
Pattern Adoption: After the agent completes its work, the system correlates receipt file changes with recently-offered patterns. If the agent actually used a pattern,
used_countincrements. If not, it's flagged as ignored. -
Confidence Update: The nightly learning cycle adjusts confidence scores. Adopted patterns get a 10% boost. Ignored patterns decay by 5%. The math is simple but effective: a consistently adopted pattern reaches maximum confidence in about 7 days. A consistently ignored pattern hits the floor after 44 days.
-
Intelligence Injection: The next time an agent gets a dispatch, patterns are ranked by confidence. High-confidence patterns surface first. Low-confidence patterns fade. The system learns what works by watching what agents actually use.
This is not machine learning. There are no model weights, no gradient descent, no training runs. It's a feedback loop with arithmetic, and it works because the arithmetic is grounded in decades of proven industrial practice.
Four Industrial Principles I Didn't Invent
Every component in this system maps to a discipline that predates AI by decades. I didn't invent any of them. I combined them.
Statistical Process Control (Toyota, 1950s)
Toyota has used Statistical Process Control for over 50 years to detect manufacturing defects before they compound. The principle is straightforward: define a control limit, measure every output, flag anything that falls outside the expected range.
I applied the same approach to agent governance metrics. My system tracks first-pass yield, rework rates, gate velocity, and composite quality scores per dispatch. When a metric deviates beyond 3 standard deviations (the classic X-bar chart), it generates an SPC alert.
A 2025 study on AI-enhanced SPC in semiconductor manufacturing found that combining AI with SPC improved yield by 1.7%, reduced false alarms by over 40%, and shortened mean time to detection by 30%. A 2025 arXiv review paper proposes transforming statistical process monitoring into "Smart Process Control," where corrective actions are autonomously implemented. That's exactly what the VNX governance layer does: detect, flag, and queue corrective actions for operator review.
Multi-Armed Bandits (Netflix, 2010s)
Netflix doesn't show you the same artwork for every show. It uses a multi-armed bandit framework to balance exploration (showing you new options to gather data) with exploitation (showing what it knows you'll click).
My confidence scoring works on the same principle. Each pattern starts at confidence 1.0. Every adoption boosts it by 10% (capped at 2.0). Every ignore decays it by 5% (floored at 0.1). The system naturally exploits high-confidence patterns while letting low-confidence ones fade, without me ever manually adjusting weights.
Adopted pattern trajectory: 1.0 → 1.10 → 1.21 → 1.33 → ... → 2.0 (~7 days)
Ignored pattern trajectory: 1.0 → 0.95 → 0.90 → 0.86 → ... → 0.1 (~44 days)This is a simplified bandit with deterministic decay. It lacks the stochastic exploration of Thompson Sampling, but for a system with 3,000+ patterns and daily feedback cycles, the simplicity is a feature. Every confidence change is logged to an append-only NDJSON file with source attribution (adoption_boost or ignore_decay), so I can audit exactly why any pattern ranked where it did.
Association Rule Mining (Agrawal & Srikant, 1994)
The Apriori algorithm has been the foundation of association rule mining for over 30 years. It finds frequent itemsets in transaction data: "customers who bought X also bought Y."
I had a tag problem. Every dispatch generates 8-12 tags: the phase, the component, the terminal, the error type, the agent. Stored as full n-tuples, these were nearly unique. No two dispatches shared the same 12-element combination, so the system could never find patterns.
The fix was Apriori-style subset decomposition. Instead of storing ["implementation", "sse-streaming", "api", "testing", "T1", "backend", "error-handling", "refactor"] as one tuple, I decompose it into all possible pairs and triples:
Pairs: ("api", "error-handling"), ("implementation", "testing"), ...
Triples: ("api", "testing", "backend"), ("implementation", "error-handling", "T1"), ...Pairs repeat 100x more than full tuples. Suddenly the system could see: "every time api + error-handling appear together, the dispatch fails 40% of the time." That's a prevention rule candidate.
The matching is hierarchical: pair → triple → rule. If a pair matches a known pattern, the system checks whether any triple containing those tags has an even more specific rule. Progressive specificity: the same principle behind Apriori's level-wise candidate generation.
Event Sourcing (Banking, Always)
Banks don't update account balances in place. They append transactions. The balance is a derived value: the sum of all events. This is event sourcing, and it's the reason you can audit any financial system back to the first transaction.
Every piece of intelligence data in VNX is append-only. Quality digests, confidence changes, pattern offers, pattern adoptions: all written to NDJSON files in append mode. I wrote about why I chose NDJSON over Postgres for audit trails in an earlier post. The short version: append-only files are simpler, faster, and impossible to accidentally mutate. The current state is always derivable from the event history.
This isn't just good practice. With the EU AI Act taking effect in August 2026, append-only audit trails for AI systems are becoming a compliance requirement. Galileo AI recommends "bulletproof audit trails with immutable logging" for production agents. I've had this since day one, not because of regulation, but because I couldn't debug production issues without it.
The Nightly Pipeline: 12 Phases of Self-Improvement
Every night at 18:00, a consolidated pipeline runs 12 phases:
| Phase | Script | What It Does |
|---|---|---|
| 0 | quality_db_init.py | Schema migrations |
| 1a-c | Scanner + extractors | Code quality scan, snippet extraction, documentation mining |
| 2 | conversation_analyzer.py | Parse session JSONL, extract analytics |
| 3 | link_sessions_dispatches.py | Correlate sessions with dispatches |
| 4 | learning_loop.py | Confidence updates, failure analysis, rule generation |
| 5 | tag_intelligence.py | Mark stale pending edits (>7 days) |
| 6 | generate_t0_session_brief.py | Model performance summary |
| 7 | governance_aggregator.py | SPC metrics, control limits |
| 8 | generate_suggested_edits.py | Config recommendations |
| 9 | build_t0_quality_digest.py | 3-section quality digest |
| 10 | generate_t0_recommendations.py | 24-hour recommendation engine |
Each phase runs independently. A failure in phase 2 doesn't block phase 4. The pipeline logs every phase to nightly_pipeline.ndjson, so I can see exactly what ran, what failed, and how long each phase took.
The quality digest (phase 9) produces a three-section summary: Operational Defects(code hotspots, critical issues),Prompt/Config Tuning(prevention rules, pending edits), andGovernance Health (SPC alerts, compliance metrics). Top 5 items per section, 24-hour lookback window.
Read also: Why Architecture Beats Models: Lessons from 2,400+ Dispatches: the dispatch architecture that feeds this intelligence system
Eight Governance Rules That Prevent Self-Destruction
A self-learning system can optimize itself into a corner. If you let it auto-activate rules, auto-archive patterns, or auto-block based on confidence, you'll eventually get a system that's confidently wrong.
Every governance rule is enforced in code, not convention:
| Rule | What It Prevents | How It's Enforced |
|---|---|---|
| G-L1 | Auto-activation of rules | Rules write to pending_rules.json, never directly to DB |
| G-L2 | Unsupported recommendations | add_recommendation() requires evidence_ids parameter |
| G-L3 | Confidence as gate | Confidence ranks, never blocks (informational only) |
| G-L4 | Silent pattern deletion | Archival candidates go to pending_archival.json |
| G-L5 | Unreviewed LLM rules | All generated rules queue for operator approval |
| G-L6 | Data mutation | NDJSON files opened in append mode only |
| G-L7 | Invisible decisions | Every offer and adoption logged to audit trail |
| G-L8 | Recommendation spam | Max 5 pending; lowest-confidence superseded |
The key principle: the system proposes, the operator disposes. Intelligence is advisory. It surfaces patterns, ranks them, and suggests actions. It never acts autonomously on its own recommendations. That's not a limitation. It's the architecture.
These rules work in concert with the async quality gates that govern every dispatch. 131 tests across 7 test files verify these rules hold. You can read them on GitHub. Tests like test_update_terminal_constraints_writes_pending_rules_json (G-L1) and test_add_recommendation_requires_evidence (G-L2) aren't testing features. They're testing governance constraints.
Read also: Glass Box Governance: What 2,472 Dispatches Taught Me: the governance framework that these rules implement
What Current Observability Tools Miss
Tools like LangSmith, Arize, and Helicone solve real problems. They trace requests, measure latency, track token usage, and visualize agent workflows. For most teams, that's the right starting point.
But none of them learn.
Current observability tools show you what happened. They don't adjust their recommendations based on what agents actually adopted. They don't decay unused suggestions. They don't generate prevention rules from recurring failure patterns or rank intelligence by confidence scores derived from production behavior.
The difference is the feedback loop. Observability is a mirror. Intelligence is a mirror that remembers what you looked at and adjusts what it shows you next time.
That said: if you're running agents in production and you don't have basic tracing yet, start there. A simple structured log that captures dispatch ID, input, output, duration, and error status covers 80% of debugging needs. Self-learning intelligence is for the other 20%: the patterns you can't see by reading individual traces.
When This Is Overkill
I built this for a system with 11 agents executing thousands of dispatches across 4 terminals. The complexity is justified by the scale.
If you're running a single agent doing one type of task (summarization, classification, extraction) you probably don't need 22 scripts. A confidence score on a few hundred patterns is enough when you can review the full output set manually.
The threshold, in my experience: when you can no longer review every agent output yourself, you need intelligence. When agents start making decisions based on other agents' outputs, you need governance.I wrote about this graduation path inFrom Human-in-the-Loop to Human-on-the-Loop.
Below that threshold, structured logging and a dashboard will serve you well.
The Results
Six months after closing the feedback loop:
- 3,000+ learned patterns with active confidence tracking
- 12-phase nightly pipeline running autonomously since January 2026
- <400 token budget per intelligence injection, context-efficient by design
- 8 governance rules enforced in code with 131 tests
- 3-section quality digest generated every 24 hours
- Zero auto-activated rules: every action requires operator confirmation
The system doesn't replace my judgment. It multiplies it. Instead of reviewing every dispatch output, I review a quality digest. Instead of manually tracking which patterns work, confidence scores handle that. Instead of guessing where failures cluster, SPC alerts tell me.
Toyota, Netflix, and banking figured this out decades ago. I just applied their principles to AI agents.
If you want to see how this kind of governance-first architecture applies to your own AI setup, read more on my AI architecture page.
The entire intelligence system is open source on GitHub. You can read every script, every test, every governance rule. That's not generosity. That's the architecture: if you can't inspect it, you can't trust it.
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.