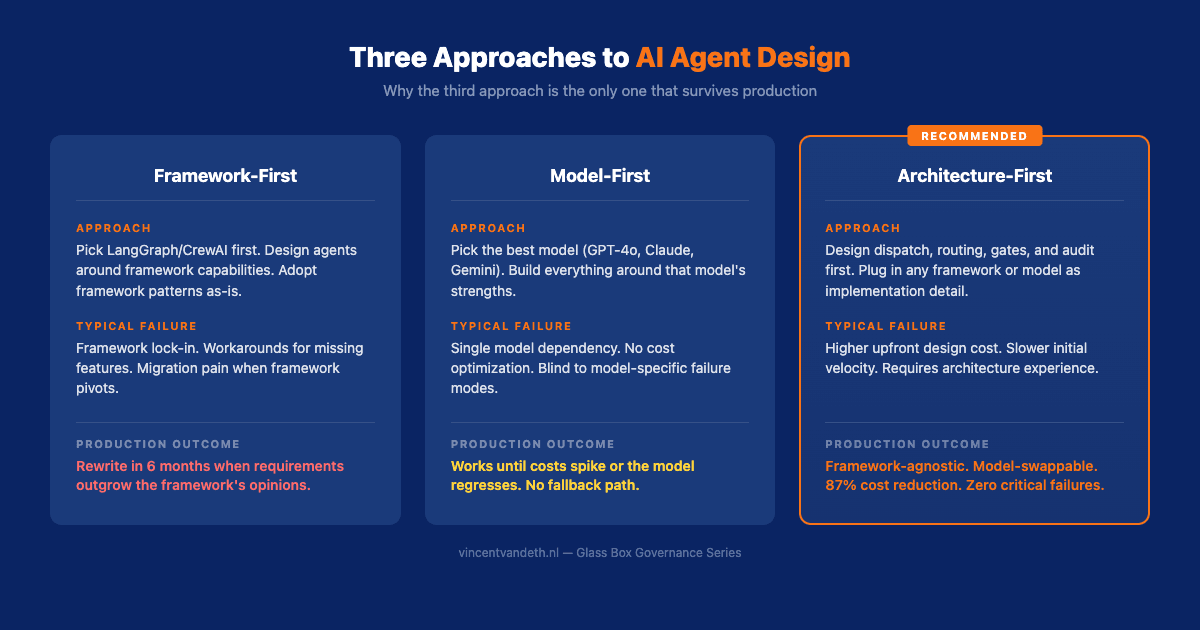
The AI engineering community has a framework addiction. Every week a new contender. Every month a new "definitive comparison." LangGraph vs CrewAI vs Anthropic Agent SDK vs OpenAI Agents SDK vs Google ADK: pick your poison.
I've watched this debate from the inside of a system that has processed over 2,400 production dispatches across four parallel agent terminals. My conclusion after six months of daily multi-agent orchestration: the ai agent architecture you design matters infinitely more than the framework you pick.
This isn't a contrarian take for engagement. It's an observation from building VNX Orchestration, a system that achieved 87% token reduction in dispatch, zero critical failures, and runs 11 agents in production. None of that came from choosing the right framework. All of it came from getting the architecture right.
The full VNX Orchestration system is open source on GitHub, MIT licensed. Every architectural decision described in this post is visible in the commit history.
The Framework Explosion of 2026
Let me acknowledge the landscape. As of March 2026, I count at least seven production-grade multi-agent frameworks:
- LangGraph: graph-based orchestration, hit 1.0 GA in October 2025, now at v1.0.10
- CrewAI: role-based agent crews, 44,600+ GitHub stars, native MCP and A2A support since v1.10
- Anthropic Agent SDK: Claude-native, lightweight, v0.1.48
- OpenAI Agents SDK: supports 100+ non-OpenAI models as of v0.10.2
- Google ADK: v1.26.0, deeply integrated with Vertex AI
- AG2 (formerly AutoGen): Microsoft's multi-agent conversation framework
- Amazon Bedrock Agents: managed service with built-in guardrails
Every one of these has trade-offs. Every one has vocal advocates. And the industry has converged on a pattern: graph-based orchestration. LangGraph pioneered it. CrewAI, AutoGen v0.4, and others adopted it.
The convergence is telling. When every framework starts looking the same architecturally, the framework itself stops being the differentiator.
What 2400+ Dispatches Taught Me
I run four parallel terminals daily. Terminal T0 orchestrates. T1 and T2 execute code tasks. T3 runs tests and validation. Every dispatch, every task routed from orchestrator to worker, generates a structured NDJSON receipt with model, cost, tokens, duration, and outcome.
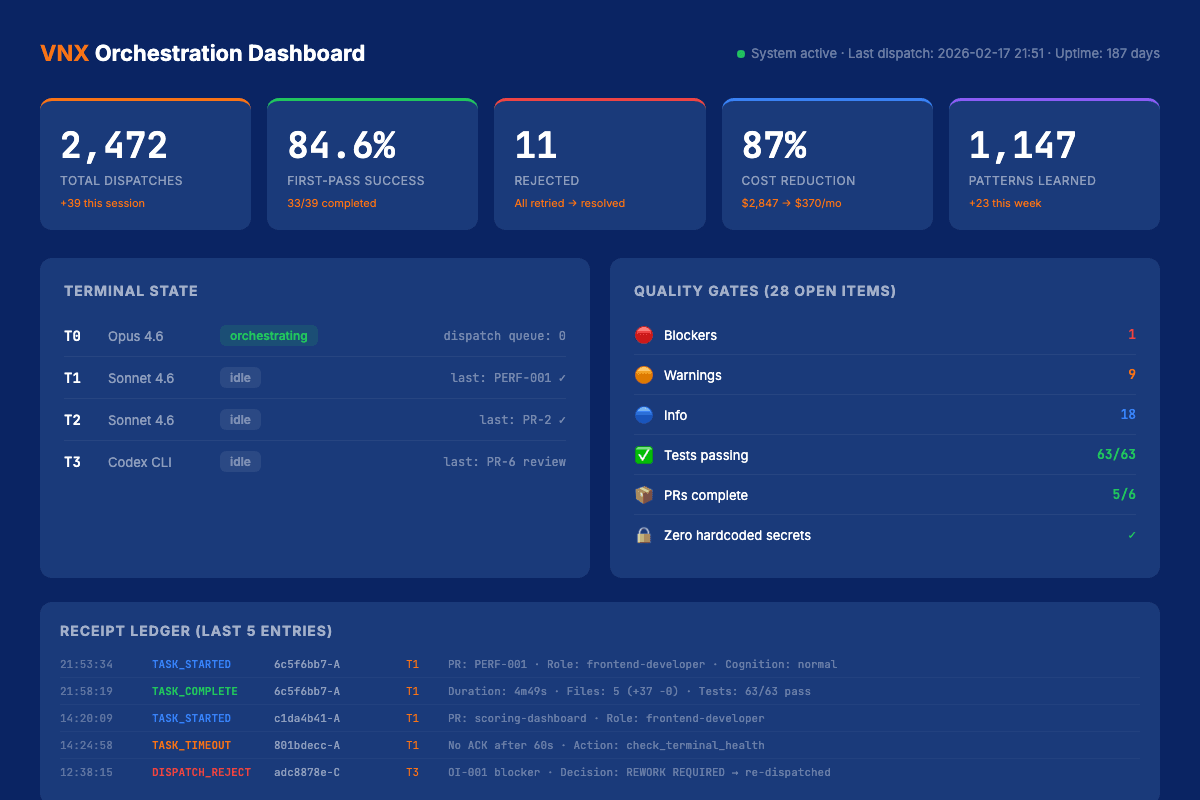
After 2,400+ of these dispatches, patterns emerged that no framework comparison article covers:
1. Failure modes are architectural, not framework-specific.
The cascading hallucination that rewrites three files at 2am? That's not a LangGraph bug or a CrewAI limitation. That's a missing quality gate. I wrote about this specific incident in the Glass Box Governance series opener, an agent chain that looked clean in git but had no audit trail connecting decision to action.
No framework prevents this. Architecture does.
2. Cost scales with orchestration design, not model choice.
My system routes tasks to different models based on complexity. Haiku for classification. Sonnet for code generation. Opus for architectural decisions. The 87% token reduction in dispatch came from this routing logic, not from switching frameworks, not from negotiating API pricing.
Intelligent routing saved more money than any single model improvement could.
3. Observability is a first-class architectural concern.
When something breaks in a multi-model orchestration setup, you need to trace the full dispatch chain. Which agent decided? What context did it have? What quality gate did it pass or fail?
Frameworks give you logging. Architecture gives you audit trails.
Three Architecture Patterns That Actually Matter
After iterating through dozens of configurations, three patterns proved essential for production multi-agent orchestration. These are framework-agnostic: they work whether you're on LangGraph, CrewAI, or bare API calls.
Here's what this looks like in practice, four terminals running in parallel, each with a dedicated role:
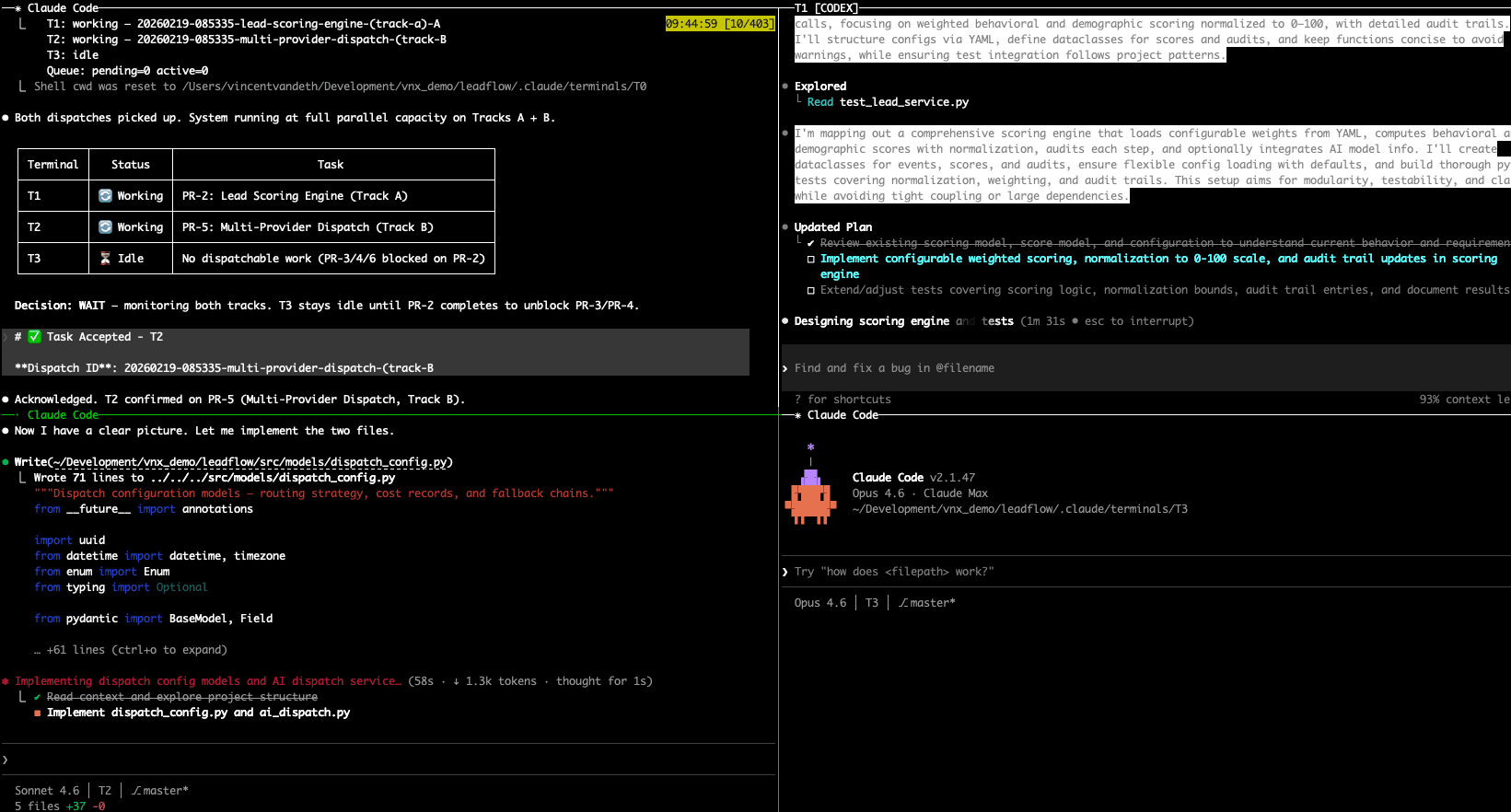
Pattern 1: Dispatch-Receipt Ledger
Every agent action generates an immutable receipt before execution begins. Not a log entry after the fact, a structured record that captures intent, context, and expected outcome before the agent runs.
This is the foundation of the Glass Box Governance approach. The receipt ledger means I can audit any dispatch chain, replay failures, and prove exactly what happened. In 2,400+ dispatches, this pattern caught 23 potential cascading failures before they executed.
Each receipt is provider-aware: it records the provider and model that ran the dispatch next to the token count and dollar cost, so the ledger doubles as the cost-governance data my routing table depends on. The lifecycle that produces it is uniform across lanes now, PREPARE assembles the instruction, GOVERN produces a contract report, RECEIPT writes the hash-chained entry, and a receipt is guaranteed for every dispatch even when a lane has to synthesize one from git facts.
Pattern 2: Async Quality Gates
Agents don't get to decide when they're done. The system does.
Every dispatch passes through async quality gates, automated checks that verify deliverables against predefined criteria before marking a task complete. Tests must pass. Type checks must clear. Output must match the expected schema.
This pattern eliminated the "looks good but isn't" failure mode that plagues every multi-agent setup I've seen. The agent says "done." The gate says "prove it."
Pattern 3: Model-Task Routing
Not every task needs your most powerful model. Classification tasks? Haiku handles them in 200ms at $0.001. Code generation? Sonnet at 3-5 seconds. Architectural decisions that affect the full codebase? That's where Opus earns its cost.
The routing table in VNX maps task types to models based on three factors: required reasoning depth, acceptable latency, and cost ceiling. This single pattern accounts for most of the 87% token reduction in dispatch.
Routing is one half of the model story. Design is the other. When I plan a feature now I do not ask one model for the plan, I run a four-architect panel, codex, kimi, deepseek, and opus, each writing an independent plan that I synthesize. The models are interchangeable. The architecture around them, independent plans plus a deliberate synthesis step, is what catches the edge case a single model misses. That is the whole thesis compressed into one workflow: more models do not help unless the architecture between them does.

Why Most Framework Comparisons Miss the Point
Open any "LangGraph vs CrewAI" article. You'll find feature matrices comparing graph types, agent communication protocols, and supported LLM providers. These comparisons are technically accurate and practically useless.
Here's what they don't compare:
- Failure recovery: what happens when agent 3 in a 5-agent chain hallucinates? How does the system detect it? How does it roll back? No framework handles this out of the box. Your architecture must.
- Cost governance: who decides which model handles which task? Most frameworks default to "use the same model everywhere." That's a 5x cost multiplier hiding in your architecture.
- Audit continuity: can you trace a production incident back to the specific dispatch that caused it, including the full context the agent had at decision time? Chat logs don't count. They expire, they're unstructured, they're not queryable.
The Reddit community is catching on. As one commenter put it: "The biggest headache isn't the framework choice." The headache is everything the framework doesn't handle, and that's the architecture layer.
The Architecture Checklist
If you're building production AI agents, here's the checklist I wish I'd had six months ago. Framework-agnostic, battle-tested across 2,400+ dispatches:
Observability
- [ ] Every dispatch generates a structured receipt (not just a log line)
- [ ] Receipts are immutable and queryable
- [ ] Full dispatch chains are traceable from trigger to outcome
Quality Control
- [ ] No agent self-certifies completion, external gates verify
- [ ] Quality criteria are defined before execution, not after
- [ ] Failed gates trigger structured retry, not blind re-execution
Cost Governance
- [ ] Model routing is explicit and configurable per task type
- [ ] Token usage is tracked per dispatch, per agent, per model
- [ ] Cost ceilings exist per dispatch and per session
Failure Handling
- [ ] Cascading failures are detectable within 1 dispatch
- [ ] Rollback paths exist for every agent action
- [ ] Human escalation triggers are defined and tested
This checklist works regardless of whether you're on LangGraph, CrewAI, Anthropic's SDK, or raw API calls. The answers to these questions determine your production reliability, not your framework choice.
The framework debate will keep raging. New contenders will launch monthly. But the teams that ship reliable multi-agent systems won't be the ones who picked the "right" framework. They'll be the ones who designed the right architecture around whatever framework they chose.
The code is open source on GitHub. For how I design this architecture for clients, see AI architecture & agents.
Update: June 2026
The thesis held up under a change that would have broken a framework-coupled system. Anthropic's June 15 billing move pushed headless claude -p onto paid API credits, so I swapped the default Claude worker to an ephemeral tmux-spawn lane, a fresh interactive window per dispatch: the model did not change, the framework did not change, only the delivery lane did, and the governance contract PREPARE, GOVERN, RECEIPT carried straight across because it never depended on the lane. VNX has since reached 1.0 code-freeze, and the one bug that bit me came from the lane, not the architecture: the first task through the new window sat idle because the instruction was pasted but never submitted, and my readiness check still watched for a "Welcome to Claude" banner that Claude Code v2.1.159 no longer prints. I found it by dogfooding, which is the only honest way to trust your own default lane.
This post is part of the Glass Box Governance series.
Previous: Claude Agent Teams vs. Building Your Own: Anthropic shipped native multi-agent coordination. So why would you still build your own? Next: Async Quality Gates: What happens when you let agents decide they're done? Spoiler: incomplete work ships.
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out)
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports ← you are here
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches ← you are here
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.