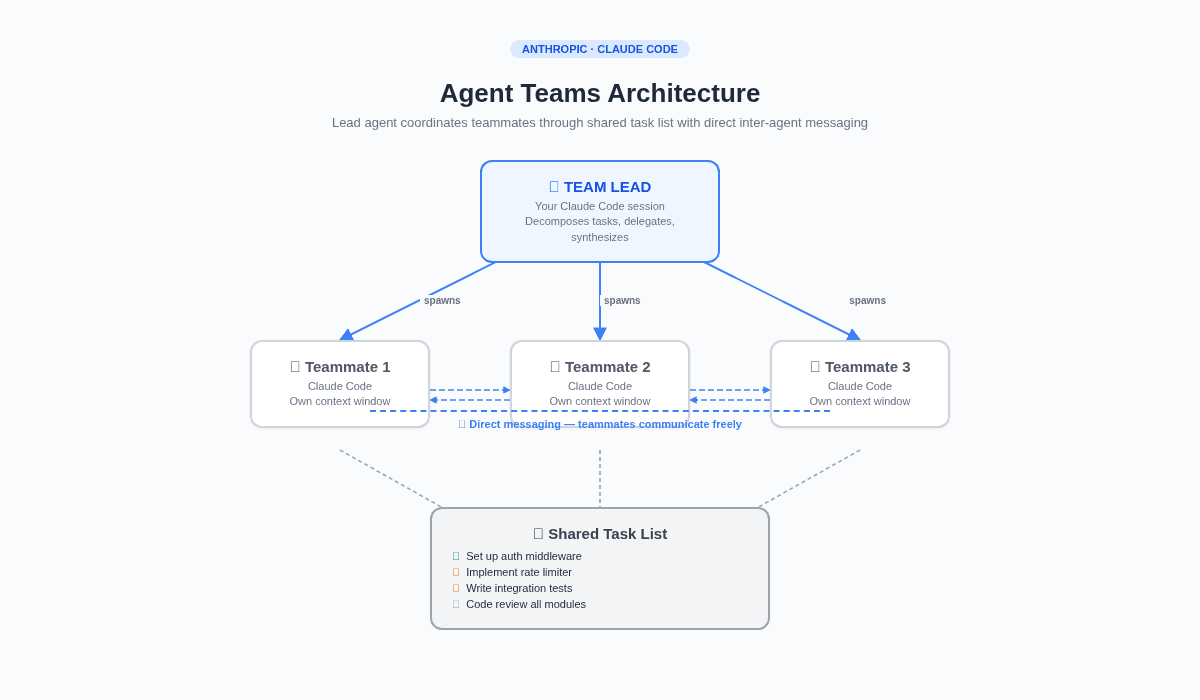
In February 2026, Anthropic shipped Agent Teams, a native multi-agent coordination feature for Claude Code. A lead agent decomposes tasks, spawns teammates, and coordinates work through a shared task list. Teammates communicate directly with each other and with you. It's built into the product, it's elegant, and it works.
I watched the announcement with a very specific feeling: the feeling of someone who spent eight months building their own version of something the platform just made native.
But after weeks of comparing both systems, running Agent Teams on side projects while VNX handles my production work, I've come to a conclusion that surprised me. Agent Teams and VNX aren't competitors. They solve different problems. And the gap between them is exactly the gap I've been writing about in this series: governance.
What Anthropic built
Agent Teams coordinates multiple Claude Code instances working together. Here's the architecture:
A lead agent(your main Claude Code session) acts as the team coordinator. It understands the overall task, breaks it into subtasks, and delegates work toteammates: separate Claude Code instances, each with their own context window.
Teammates share a task list, a common work queue where tasks have states (pending, in progress, completed) and dependencies. A teammate finishes a task, picks up the next available one. If tasks depend on each other, blocked tasks wait automatically.
Teammates also have a mailbox, a direct messaging system. They can talk to each other, challenge findings, share discoveries. The lead doesn't need to relay every message. In split-pane mode (tmux or iTerm2), you can see all teammates working simultaneously and click into any pane to interact directly.
┌─────────────────┐
│ TEAM LEAD │
│ (your session) │
└───────┬─────────┘
│ spawns & coordinates
┌─────────────┼─────────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Teammate 1│ │ Teammate 2│ │ Teammate 3│
│ (Claude) │ │ (Claude) │ │ (Claude) │
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└──── direct messaging ─────┘
│
┌───────┴───────┐
│ Shared Task │
│ List │
└───────────────┘It's genuinely impressive. The team can parallelize code reviews, investigate bugs from competing angles, and build new features with each teammate owning a separate module. Anthropic's own stress test, 16 agents writing a Rust C compiler across nearly 2,000 sessions, demonstrated the scale it can handle.
What I built
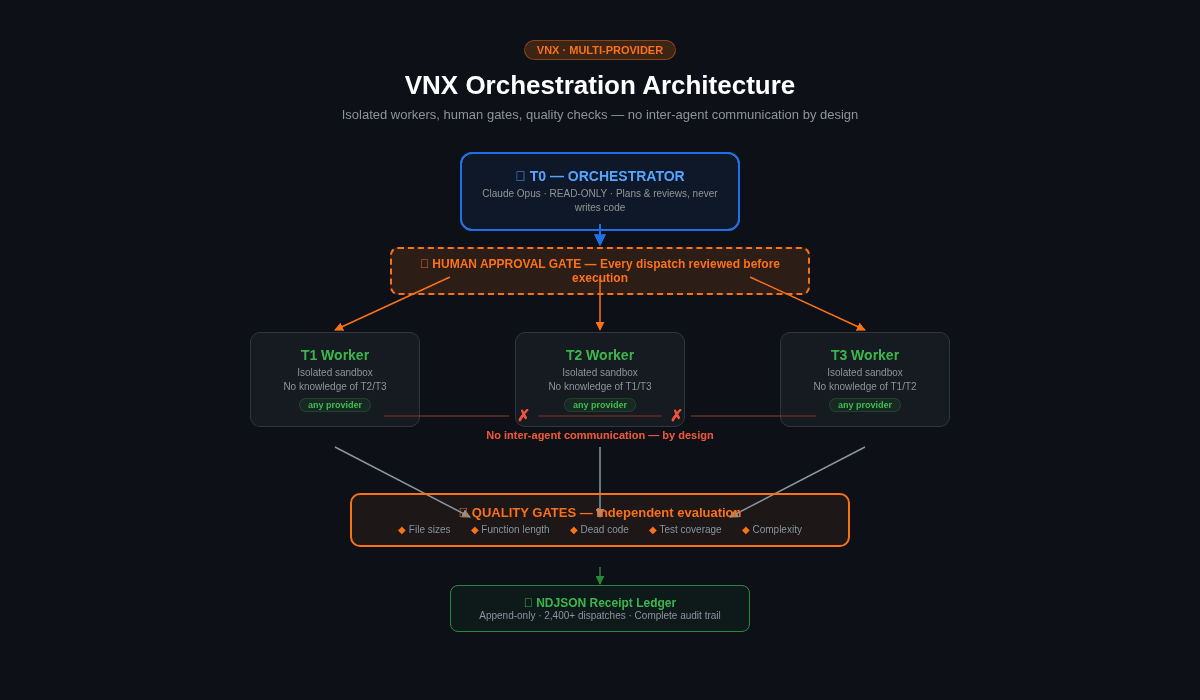
VNX, the system I've been running for eight months and documenting in this series, looks different. Here's the same view:
┌─────────────────┐
│ T0 ORCHESTRATOR│
│ (Claude Opus) │
│ READ-ONLY │
└───────┬─────────┘
│ dispatches (human-approved)
┌─────────────┼─────────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ T1 Worker │ │ T2 Worker │ │ T3 Worker │
│ (any │ │ (any │ │ (any │
│ provider)│ │ provider)│ │ provider)│
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────┐
│ Quality Gates + Receipt Ledger │
│ (external, agent-independent) │
└──────────────────┬──────────────────┘
│
┌──────┴──────┐
│ T0 reviews │
│ evidence │
└─────────────┘Notice what's missing: there are no arrows between workers. T1, T2, and T3 never communicate. There's no shared task list between them. There's no mailbox. Each worker operates in complete isolation.
All coordination goes through T0, and T0 itself can't write code. It can only read, plan, and dispatch. Every dispatch requires human approval. Every completion requires evidence. Every evidence goes through quality gates before T0 can accept it.
Where they overlap
The similarities are real and worth acknowledging:
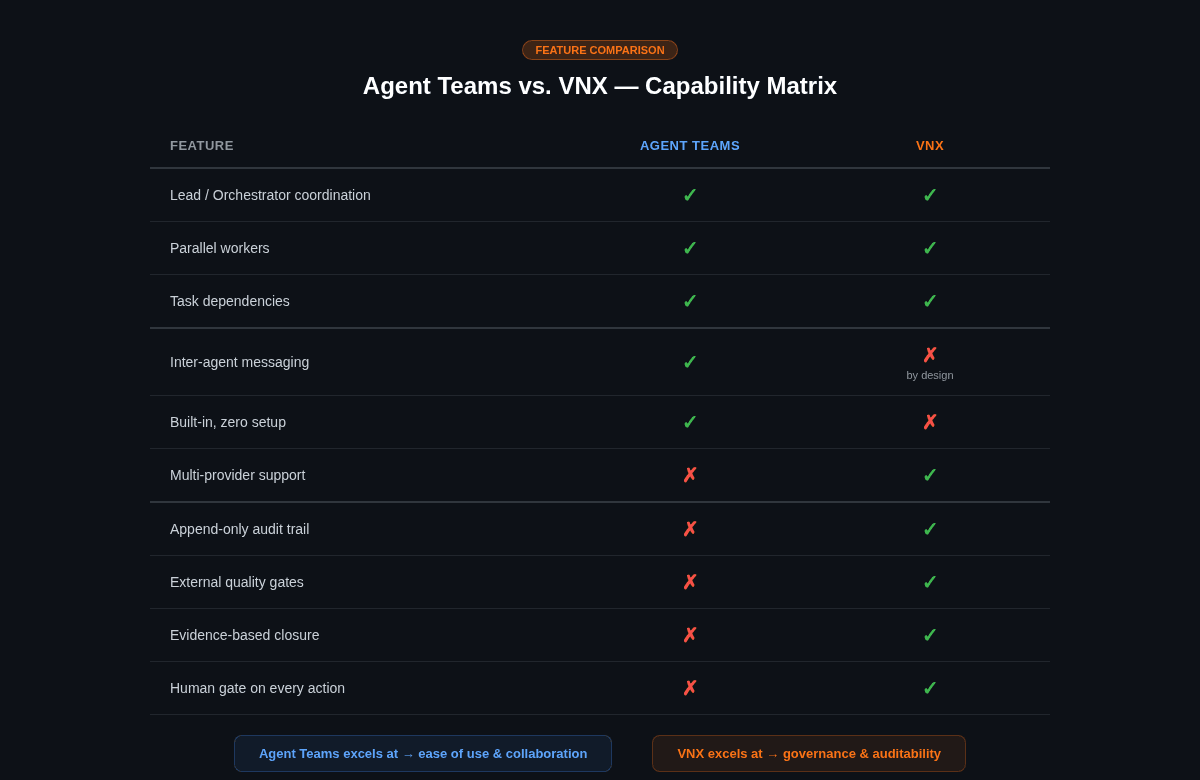
Lead-agent coordination. Both systems use a central coordinator. Agent Teams has the lead; VNX has T0. Both decompose tasks, assign work, and synthesize results. The pattern is the same: one agent thinks, others execute.
Parallel workstreams. Both run multiple agents simultaneously on separate aspects of a problem. Agent Teams uses teammates claiming tasks from a shared list. VNX uses track-agnostic workers that can handle any type of task. The parallelism model is fundamentally similar.
Task dependencies. Both handle ordered work. Agent Teams blocks tasks with unresolved dependencies. VNX's staging queue prevents dispatches from promoting until prerequisite PRs are complete. Different mechanisms, same principle.
Shared project context. Both give workers access to the same codebase. Teammates load CLAUDE.md and project files. VNX workers operate in the same repository with their own CLAUDE.md configurations. The agents see the same code.
Plan-before-implement.Agent Teams can require teammates to plan before executing; the lead reviews and approves the plan. VNX's staging queue serves the same function: the orchestrator reviews the dispatch scope before the worker begins. This is one of the coreGlass Box Governance principles: no action without approval.
These overlaps aren't coincidental. Both systems converged on the same patterns because those patterns work. Decompose, delegate, coordinate, synthesize. It's the multi-agent playbook.
Where they diverge
The differences tell a more interesting story. They reveal fundamentally different assumptions about trust, risk, and who should be in control.
1. Inter-agent communication
Agent Teams: Teammates message each other directly. They can share findings, challenge hypotheses, and coordinate without the lead relaying every message. This is powerful for research and review tasks where cross-pollination of ideas adds value.
VNX: Workers never communicate. All information flows through T0 and the governance layer. Workers don't know about each other's existence. This isolation also means each worker authenticates independently through the CLI subprocess pattern.
Why this matters: Direct inter-agent communication is the mechanism that enables the Cascade of Doom. When Agent A can influence Agent B's decisions without a checkpoint in between, one hallucination can propagate across the entire system. My 2am incident, where one agent hallucinated a dependency and another helpfully created it, happened precisely because agents could react to each other's output without an independent check.
Agent Teams mitigates this partially through the lead's oversight, but the lead is itself an AI agent. It makes autonomous decisions about whether teammate plans are good enough to approve. In VNX, that decision is always human.
2. Provider lock-in
Agent Teams: All teammates are Claude Code instances. You can choose different Claude models (Opus, Sonnet) per teammate, but you can't mix providers. No Codex teammate. No Gemini teammate.
VNX: Each worker can run any provider. T1 can be Codex CLI while T2 runs Claude Sonnet and T3 runs Gemini. The dispatch system adapts per provider. The governance pipeline is provider-neutral; it observes terminal output, not API calls.
Why this matters: Model diversity isn't just about having options. Different models catch different types of errors. When I run a Claude Opus investigation on any task against code that Claude Sonnet wrote on any task, I'm getting a second opinion from a fundamentally different model configuration. If T1 is running Codex, its code generation patterns are different enough that it won't reproduce the same hallucination patterns as Claude. Provider diversity is a governance property, not just a convenience.
A concrete example: for nontrivial feature design, I now run a 4-architect panel -- Codex, Kimi, DeepSeek, and Opus each writing independent design plans, which I then synthesize. They catch different things. Codex spots implementation gaps Kimi misses. DeepSeek finds architectural risks Opus overlooks. A single Claude lead, no matter how capable, can't reproduce four independent reasoning paths from four different model families.
3. The governance layer
This is the big one.
Agent Teams: The lead decides when work is done. Teammates mark tasks as complete. The lead synthesizes results. There are hooks (TeammateIdle and TaskCompleted) that can enforce rules, and you can require plan approval before implementation. But the audit trail is the conversation history, which doesn't persist across sessions. There's no receipt ledger, no external quality gate, no evidence-based closure system.
VNX: Completion is never self-reported. Every action writes a receipt to an append-only ledger. Every completion triggers an independent quality advisory (file sizes, function lengths, dead code, test hygiene). Only T0, after reviewing the evidence and the quality verdict, can declare work done. The agent's "I'm done" is input, not verdict.
Why this matters: In any system where agents can declare their own work complete, you're trusting the agent's self-assessment. An agent that reports "confidence 0.97" may have written an 847-line file that violates every quality standard. The confidence score reflects the model's internal state, not external reality. Independent verification -- by a process the agent can't influence -- is what makes governance trustworthy.
Since this post, the governance layer has converged on a uniform dispatch lifecycle across all provider lanes. Every dispatch goes PREPARE (one instruction: skill body + permission preamble + intelligence + report-contract directive) to GOVERN (the worker authors a structured report, validated in shadow mode -- never a placeholder) to RECEIPT (an append-only, hash-chained NDJSON receipt is guaranteed, carrying provider, model, and token/cost data). The quality gate sits between GOVERN and RECEIPT. The agent's self-report is input to GOVERN, not the verdict.
4. Who makes the final call
Agent Teams: The lead agent decides autonomously. You can influence its judgment through prompts ("only approve plans that include test coverage"), but the approval decision is the lead's to make. You can also interact with teammates directly, but the system is designed for the lead to run the show.
VNX: Every dispatch requires explicit human approval before execution. A popup appears, you review the scope, and you press Accept or Reject. There is no autonomous dispatch path. T0 proposes; you decide. This was a deliberate choice after the Cascade of Doom incident; I permanently disabled auto-accept.
This is not a criticism of Agent Teams' approach. For research tasks, code reviews, and exploration work, having the lead coordinate autonomously is exactly right. The overhead of human approval on every task would destroy the productivity benefit.
But for production code, the kind where a wrong decision at 2am results in three files being rewritten and tests being "fixed" to match the wrong behavior, I want a human in the loop. Every time.
📖 Read also: Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail: the receipt ledger design that turns "the agent says it's done" into verifiable evidence
The cascade of doom test
Here's the thought experiment I use to evaluate any multi-agent system:
It's 2am. An agent hallucinated a dependency. Another agent sees the failing tests and "fixes" them by creating the hallucinated dependency. A third agent notices the new module and refactors surrounding code to use it. By morning, three files are rewritten, all tests pass, and the git history looks clean.
Can your system prevent this?
In Agent Teams: the lead would need to catch the hallucination before approving the teammate's plan. If the lead misses it (and the lead is an AI agent operating without human oversight at that point), the cascade proceeds. The TaskCompleted hook could catch it, but only if you've written the right validation logic. There's no built-in quality gate that checks file sizes, function complexity, or dead code.
In VNX: the cascade can't start. The first agent's completion would trigger a quality advisory. Even if the quality gate didn't catch the specific hallucination, the human approval gate would. The dispatch to "fix the failing tests" would appear as a popup. A human would see that the proposed fix is "create a module that didn't exist before" and ask: why?
The governance gap isn't about which system is better. It's about which failure modes are acceptable for your use case.
When to use which
After running both systems, here's my honest recommendation:
Use Agent Teams when:
- You're exploring, researching, or reviewing (not writing production code)
- Tasks benefit from inter-agent discussion and cross-pollination
- You want parallel work without building infrastructure
- Speed of setup matters more than auditability
- You're comfortable with AI-mediated approval (the lead decides)
Use VNX (or something like it) when:
- You're writing production code that ships to users
- You need an audit trail that survives session expiry
- You use multiple providers (Claude + Codex + Gemini)
- You want human approval on every action that touches code
- You need to reconstruct "what happened and why" after the fact
- You've already experienced your first cascade and sworn never again
Use both when:
- Agent Teams for research spikes and code reviews
- VNX for the implementation pipeline with receipts and gates
They're not mutually exclusive. I've started using Agent Teams for investigation work, spinning up three teammates to explore different hypotheses about a bug, and then funneling the findings into VNX dispatches for the actual fix. The exploration is fast and collaborative. The implementation is governed and auditable.

What I hope Anthropic builds next
Agent Teams is a genuinely good v1. The architecture is sound, the developer experience is smooth, and the parallel exploration model works well. If I were advising Anthropic on what to add next, the list would be short:
Persistent audit trail. Today, the governance record is the conversation history, which doesn't survive session termination. A structured, append-only log of team actions (who did what, when, with what result) would transform Agent Teams from an exploration tool into a production tool. (This is essentially the NDJSON receipt ledger built into the platform.)
External quality gates. The TaskCompleted hook is a start, but it runs in the same environment the agent controls. An independent validation layer (file size checks, complexity analysis, dead code detection) that evaluates agent output without the agent's influence would close the biggest governance gap.
Multi-provider teammates. The ability to spawn a Codex or Gemini teammate alongside Claude teammates would make Agent Teams the first platform to offer native multi-provider orchestration. The external watcher pattern, observing agent output from outside the agent's context, shows this is architecturally feasible.
Configurable human gates. A setting between "the lead decides everything" and "ask me for every action." Something like: autonomous for research tasks, human-approved for code changes. Risk-proportional oversight.
📖 Read also: The External Watcher Pattern: how to observe agent behavior independently, without trusting what agents say they did
The deeper question
The emergence of Agent Teams validates something I've believed since the first month of running VNX: multi-agent coordination is becoming table stakes. Everyone will be running agent teams soon, whether through Anthropic's product, LangGraph, CrewAI, or homebrew systems like mine.
But coordination without governance is a recipe for sophisticated failure. The more capable your agent team, the more convincingly it can produce work that looks correct but isn't. The Cascade of Doom doesn't get less dangerous with better models; it gets more dangerous, because the output becomes harder to distinguish from genuine good work.
The question isn't "should I use Agent Teams or build my own?" The question is: what happens when your agents are wrong, and how will you know?
If you have a good answer to that question, use whatever orchestration tool fits your workflow. If you don't, read the rest of this series. The cascade will find you eventually. And it's much cheaper to build the gates before it does.
Update: June 2026
VNX reached 1.0 code-freeze since this comparison was written. Three things have changed. First, Anthropic's June 15 billing change makes the "build your own" path more nuanced: headless claude -p calls now consume paid API credits, so the interactive tmux-spawn lane is the default Claude worker path for subscription-preserving economics. Second, the governance layer is now uniform across all six lanes: PREPARE to GOVERN to RECEIPT, with every receipt carrying provider, model, and token/cost data. Third, the 4-architect design panel (Codex + Kimi + DeepSeek + Opus) is a regular part of feature design now -- real multi-model synthesis, not single-model iteration. Agent Teams is still the right answer for exploration. For production code with an audit trail, the build-your-own path has only gotten more capable.
This post is part of the Glass Box Governance series.
Previous: Multi-Model AI Orchestration from a Single Terminal Next: Why Architecture Beats Models
📚 Glass Box Governance series
- One Terminal to Rule Them All: How I Orchestrate Claude, Codex, and Gemini Without Them Knowing About Each Other
- Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance
- The Cascade of Doom: When AI Agents Hallucinate in Chains
- Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail
- Claude Agent Teams vs. Building Your Own: What Anthropic Solved (And What They Left Out) ← you are here
- The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports
- Why Architecture Beats Models: Lessons from 2400+ AI Agent Dispatches
- Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
- From Human-in-the-Loop to Human-on-the-Loop: A Production Graduation Path
- Traceability as Architecture: Designing AI Systems Where Every Decision Has a Receipt
- Decision-Making Architecture: Why Autonomous Agents Need Governance, Not Just Instructions
- Context Rotation at Scale: How VNX Keeps AI Agents Honest After 10,000 Dispatches
- Autonomous Agent Patterns: 5 Production-Tested Approaches for Agents That Run Without You
- Governance Scoring: How to Measure Whether Your AI Agent Deserves More Autonomy
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.