In de afgelopen weken schreef ik over CLAUDE.md, rules.md, hooks, context engineering, en self-learning loops via intelligence pipelines. Telkens met voorbeelden uit mijn eigen setup.
Vandaag de samenhang: hoe past dit alles samen? Wat staat waar? Wat doet wat? Voor AI peers en hobbyisten die voorbij de eerste experimenten zijn, een complete walkthrough van mijn werkende productie-setup.
Geen abstracties. Wel: file-paths, command-mappingen, patronen die ik 8 maanden in productie heb getest.
De getallen
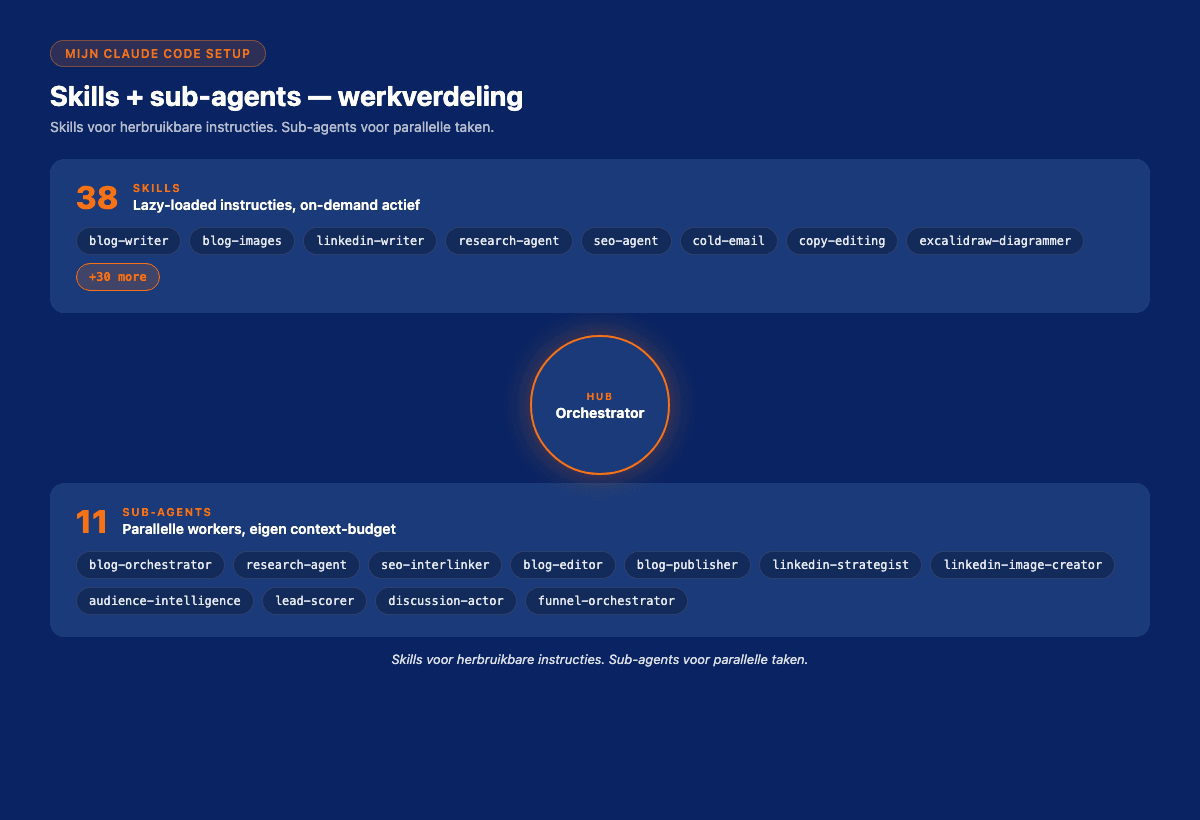
- 38 skills, herbruikbare instructie-sets, gedeeltelijk in
.claude/skills/, gedeeltelijk in~/.claude/skills/ - 11 sub-agents, gespecialiseerde agents voor research, code review, architecture, etc.
- 6 hooks, SessionStart, PreToolUse, PostToolUse, Stop
- 4 memory directories, always, on-demand, per-task, archive
- 3 rules-bestanden, tone-of-voice, testing, security
- 1 CLAUDE.md per project, context per project
- 0 vector databases, alles markdown + NDJSON
Schaal: middelgroot. Niet enterprise. Wel veel voor een solopreneur.
De directory-structuur
Eerst een vogelvlucht. Hoe is alles georganiseerd?
Globaal, ~/.claude/
~/.claude/
├── CLAUDE.md ← tech-rules + @import profile.md (~10 regels)
├── profile.md ← identiteit + portfolio (cross-project)
├── rules/ ← user-level rules, in alle projecten actief
│ ├── voice-profile.md ← hoe ik schrijf
│ └── anti-ai-tics.md ← generieke AI-zinnen die ik nooit wil
├── skills/ ← skills die in alle projecten beschikbaar zijn
│ ├── linkedin-writer/
│ ├── blog-orchestrator/
│ ├── research-agent/
│ └── (35 anderen)
├── memory/ ← persoonlijke memory (niet in git)
│ └── (per project een subfolder)
├── settings.json ← machine-niveau settings
└── plugins/ ← Claude Code pluginsPer-project, .claude/
[project-root]/
├── CLAUDE.md ← project-specifieke context
└──.claude/
├── rules/
│ ├── tone-of-voice.md
│ ├── testing.md
│ └── security.md
├── skills/ ← project-specifieke skills (overruled globaal)
├── hooks/ ← project-specifieke hooks
│ ├── load_memory.sh ← SessionStart
│ ├── bash_safety.sh ← PreToolUse
│ └── auto_test.sh ← PostToolUse
├── memory/ ← project-state, MEMORY.md
│ ├── always/
│ │ └── MEMORY.md
│ └── on-demand/
│ ├── decisions.md
│ └── lessons_learned.md
├── work/ ← per-task state
│ └── [task-folders]/
└── commands/ ← slash commands
├── blog.md
├── linkedin.md
└── (4 anderen)Belangrijk: globale skills/memory zijn voor mijn algemene werk. Project-skills/memory zijn voor specifieke projecten. Bij conflict wint project.
📖 Lees ook: Hooks in Claude Code: geautomatiseerde acties na elke prompt: hoe SessionStart, PostToolUse en Stop je workflow automatiseren
De gelaagde architectuur: identiteit, voice, en project-context apart
De directory-structuur hierboven is georganiseerd langs één principe: wat is identiteit en wat is project-context? Identiteit verandert zelden, project-context verandert wekelijks. Door ze fysiek te scheiden voorkom ik dat een blog-sessie iets weet over een klant-deadline, en dat een coding-sessie zich druk maakt om marketing-buzzwords.
Twee niveaus dus, scherp gescheiden.

Niveau 1, globaal (~/.claude/)
profile.md wordt automatisch geladen via de @~/.claude/profile.md regel in CLAUDE.md. Voordeel: één bron voor mijn identiteit, geen herhaling per project.
Wat in profile.md staat:
- Wie ik ben (Head of AI Solutions SalesMinds + VNX Digital + SEOcrawler)
- Communicatie-voorkeuren (Nederlands, 1e persoon enkelvoud, geen em-dashes)
- Werk-voorkeuren (architect-mindset, governance-stokpaardje, human-in-the-loop)
- Portfolio-overview (één paragraaf per domein)
Het is bewust statisch. Deadlines en project-status horen niet hier, die wonen in project-memory.
Niveau 2, per project (<project>/.claude/)
Drie subtiele dingen die ik hier doe:
Path-scoping via een paar instellingsregels bovenaan een rules-bestand (YAML frontmatter voor wie die term kent). Mijn tone-of-voice.md heeft paths: ["Content/**", "project/vnx_digital/**"], wat betekent: alleen actief als Claude in die mappen werkt. In een coding-sessie in Development/ laadt deze rule niet. Officieel ondersteund door Claude Code, weinig gebruikt.
Project-memory in .claude/memory/ met een MEMORY.md index. Hier komen observaties die voor één project gelden, bijvoorbeeld aliassen tussen klantnamen, of specifieke pricing-beslissingen.
Anti-marketing-buzzwords als aparte rule. Termen als "revolutionair" of "game-changer" blokkeer ik in content-folders, niet in code. Globale en project-rules vullen elkaar aan zonder elkaar te storen.
Wat dit oplevert in de praktijk
In een coding-sessie in ~/Development/SEOcrawler_v2/:
- Globale identiteit + voice + anti-AI-tics laadt (~120 regels)
- Project CLAUDE.md laadt (~80 regels)
- Marketing-rules laden NIET (path-scope past niet)
- Project-memory laadt (~50 regels)
In een blog-sessie in ~/Desktop/BUSINESS/Content/blog/:
- Alle bovenstaande PLUS marketing-rules PLUS blog-rules
- Tone-of-voice.md activeert via path-scope
- Anti-marketing-buzzwords laden in voor content-werk
Totaal: ~300 regels gerichte context per sessie. Geen ruis. Geen ontbrekende info. Claude weet altijd wie ik ben, en in een blog-folder weet hij óók hoe ik klink.
Dit patroon, gelaagde scheiding tussen identiteit en context, is wat het verschil maakt tussen 38 skills die wel werken en 38 skills die elkaar in de weg zitten.
De 38 skills (overzicht)
Niet alle 38 individueel, wel de categorieën die je kunt zien:
Content & Marketing (13 skills)
blog-orchestrator, blog-writer, blog-images, blog-publisher, blog-editor, seo-interlinker, seo-agent, linkedin-writer, linkedin-strategist, linkedin-image-creator, social-content, copywriting, copy-editing
Deze coördineren mijn content-pipeline. blog-orchestrator is de top, hij roept andere skills aan in volgorde.
Audience & Lead Intelligence (5 skills)
audience-intelligence, lead-scorer, discussion-actor, cold-email, email-sequence
Voor mijn LinkedIn intelligence engine en lead-werk.
Product Marketing & Strategy (5 skills)
product-marketing-context, marketing-psychology, marketing-ideas, pricing-strategy, launch-strategy
Strategische skills die ik wekelijks aanroep voor branding-werk.
Development Operations (8 skills)
research-agent, vnx-project-setup, excalidraw-diagrammer, phantombuster, claude-api, plus de SuperClaude sc:* skills (sc:document, sc:implement, etc.)
Voor technisch werk en architectuur-werk.
Visual & Diagram (3 skills)
linkedin-carousel-builder, excalidraw-diagrammer, linkedin-image-creator
Reflection & Process (4 skills)
competitor-alternatives, funnel-orchestrator, content-strategy, reddit-marketing
Per maand: ik gebruik typisch 5-8 skills per dag, niet alle 38. Het zit allemaal beschikbaar zodat als ik het nodig heb, het er is.
De 11 sub-agents
Sub-agents zijn aparte. Een skill is een instructie-set. Een sub-agent is een aparte sessie met eigen context. Mijn 11:
| Agent | Wat het doet | Wanneer ik hem aanroep |
|---|---|---|
general-purpose | Open onderzoeksvragen | Onderzoek dat 3+ queries kost |
Explore | Code zoeken in repo | "Waar staat X?" |
Plan | Implementatieplan maken | Voor non-trivial features |
backend-architect | Backend ontwerp | Database design, API design |
frontend-architect | Frontend ontwerp | UI patterns, accessibility |
system-architect | Systeem-niveau | Architectuur-keuzes met long-term impact |
security-engineer | Security review | Voor elke significante PR |
quality-engineer | Test strategy | Edge cases bepalen |
performance-engineer | Performance optimization | Wanneer benchmarks nodig zijn |
python-expert | Python best practices | VNX-werk vooral |
claude-code-guide | Claude Code expertise | Vragen over CC zelf |
Niet alle 11 dagelijks. Wel ze allemaal binnen handbereik via Agent(subagent_type=...).
De 6 hooks
Concreet:
.claude/hooks/
├── load_memory.sh ← SessionStart, laadt always/MEMORY.md
├── bash_safety.sh ← PreToolUse, blokkeert gevaarlijke commands
├── auto_test_on_edit.sh ← PostToolUse, triggert test bij file-edit
├── receipt_logger.sh ← PostToolUse, logt actie in NDJSON
├── context_monitor.sh ← PreToolUse, blokkeert bij 65% context
└── auto_commit_notes.sh ← Stop, committeert work-notesDe context_monitor.sh is degene die op #1 in Google staat, auto-rotation bij 65% gevuld geheugen.
Hoe het samenwerkt, een concrete sessie
Hoe ziet een typische sessie eruit?
Stap 1, Sessie start. Ik open Claude Code in mijn blog-project. SessionStart-hook draait load_memory.sh. Dit injecteert:
~/.claude/CLAUDE.md(persoonlijke werkstijl, ~40 regels)[project]/CLAUDE.md(blog-project context, ~60 regels).claude/rules/tone-of-voice.md(stem-regels, ~90 regels).claude/memory/always/MEMORY.md(project-status, ~50 regels)
Totaal: ~240 regels baseline context. Schoon, gefocust, geen ruis.
Stap 2, Slash command. Ik typ /blog kalender. Slash command leest de eerstvolgende blog uit mijn kalender en triggert de pipeline.
Stap 3, Skill orchestratie. blog-orchestrator skill activeert. Roept achter elkaar aan:
research-agent(sub-agent, parallelle research)seo-agent(skill, keyword analysis)blog-writer(skill, draft schrijven)seo-interlinker(skill, interne links)blog-images(skill, visuals)blog-editor(skill, kwaliteits-check)
Per stap: receipt naar NDJSON (via PostToolUse hook). Output naar Telegram (via webhook).
Stap 4, Mijn review. Bij elke significante stap krijg ik een Telegram-bericht met "concept klaar voor review". Ik open in browser, lees, accepteer of vraag wijziging.
Stap 5, Sessie eind. Stop-hook draait auto_commit_notes.sh. Werknotities en memory-updates worden vastgelegd.
Geen handmatige coördinatie. Geen "wacht, welke skill moet ik nu aanroepen?". Het systeem weet de volgorde, ik beslis de quality gates.
📖 Lees ook: Agentic OS: de centrale bediening voor je bedrijf: hoe agents, orchestratie en context samen een werkend systeem vormen
Drie patronen die het verschil maken
Niet alle 38 skills zijn even belangrijk. Drie patronen die het meeste verschil maken:
Patroon 1, Orchestrator skills
blog-orchestrator en linkedin zijn meta-skills. Ze coördineren andere skills. Een orchestrator skill heeft drie eigenschappen:
- Roept andere skills aan in vaste volgorde
- Heeft duidelijke quality gates per stap
- Slaat tussenresultaten op zodat je kunt onderbreken
Ik heb 4-5 orchestrator skills. Voor herhalende multi-step workflows zijn ze goud waard.
Patroon 2, Skills met expliciete ICP
Elke skill weet voor wie hij schrijft/maakt. blog-writer heeft drie modes (NL MKB, NL AI peers, EN architects). linkedin-writer heeft eigen ICP-targeting. cold-email werkt per ICP-segment.
Zonder ICP-awareness zou de output generiek worden. Met ICP-awareness past elke output bij de doelgroep zonder dat ik het hoef te specificeren.
Patroon 3, Skills met "anti-claims"
Elke skill in productie heeft een sectie "wat dit NIET doet". Voorbeeld in blog-writer:
- Schrijft niet over health/medical zonder disclaimer
- Schrijft niet over Vincent's vrouw of privé-leven
- Genereert geen testimonials over klanten
- Schrijft niet in andere persoon dan eerste-persoon
Anti-claims voorkomen dat skills dingen doen die jij niet wilt, vaak gevoeliger dan wat ze wel moeten doen.
Wat ik zou doen anders bij een nieuwe setup
Drie eerlijke leerpunten van 8 maanden:
- Begin niet met 38 skills. Begin met 3 voor je meest-herhalende taken. Voeg pas een 4e toe als die echt 80% bewezen waarde heeft. Mijn 38 zijn organisch gegroeid, niet ontworpen vooraf.
- Memory > skills voor onbeschermde info. In het begin stopte ik veel context in skills. Hoort vaak in memory. Memory is goedkoper te updaten en blijft persistent.
- Hooks eerst, dan skills. SessionStart-hook met memory-loader is meer waard dan 5 nieuwe skills. Bouw de fundering voor je optopt.
Wat doe je deze week?
Drie acties, naar gelang waar jij staat:
Beginner (1-2 maanden CC):
- Maak één CLAUDE.md, één SessionStart-hook, één slash command voor je vaakste taak.
Intermediate (3-6 maanden CC):
- Voeg 2-3 skills toe voor terugkerende workflows. Zet rules.md op met testing- en security-regels.
Advanced (6+ maanden CC):
- Bouw een orchestrator skill voor één multi-step workflow. Kijk of memory-tier-systeem werkbaar is. Voeg context-monitor hook toe.
Niet alles tegelijk. De waarde komt uit consistent gebruiken van wat je hebt, niet uit het hebben van veel.
Veelgestelde vragen
Samenvatting
38 skills, 11 sub-agents, 6 hooks, 4 memory directories, opgebouwd in 8 maanden Claude Code in productie. De waarde zit niet in het aantal, maar in de drie patronen: orchestrator skills voor multi-step workflows, ICP-aware output, en anti-claims om te voorkomen dat skills doen wat jij niet wilt.
Begin niet met deze schaal. Begin met CLAUDE.md, één SessionStart-hook, en één slash command. Voeg toe naargelang je workflow het nodig heeft.
In zes maanden heb je iets dat compounding werkt, net als bij elke discipline waar je consistent in investeert. Geen 38 skills nodig. Wel 38 weken trouw werken aan de essentie.
Wil je sparring over jouw eigen Claude Code setup? Volg me op LinkedIn, daar deel ik wekelijks build-in-public updates over hoe mijn setup zich ontwikkelt. Of kijk op mijn werkwijze-pagina hoe ik dit soort systemen bouw voor andere bedrijven.