Your Claude Code session doesn't crash when the context window fills up. It does something worse: it starts forgetting.
Not dramatically. Not with an error message. The agent just... drifts. It loses architectural decisions you made an hour ago. It rewrites code it already wrote. It proposes changes that contradict its own earlier analysis. The output still looks professional (clean commit messages, reasonable diffs), but the substance quietly degrades.
I call this context rot, and after 3,000+ hours in Claude Code running multi-agent workflows daily, I believe it's the single biggest unaddressed problem in AI-assisted development. This is especially critical in production systems using the Glass Box Governance architectureI've built as part of theVNX orchestration toolkit. When agents can't see or verify their own state, context rot leads to undetectable quality drift.
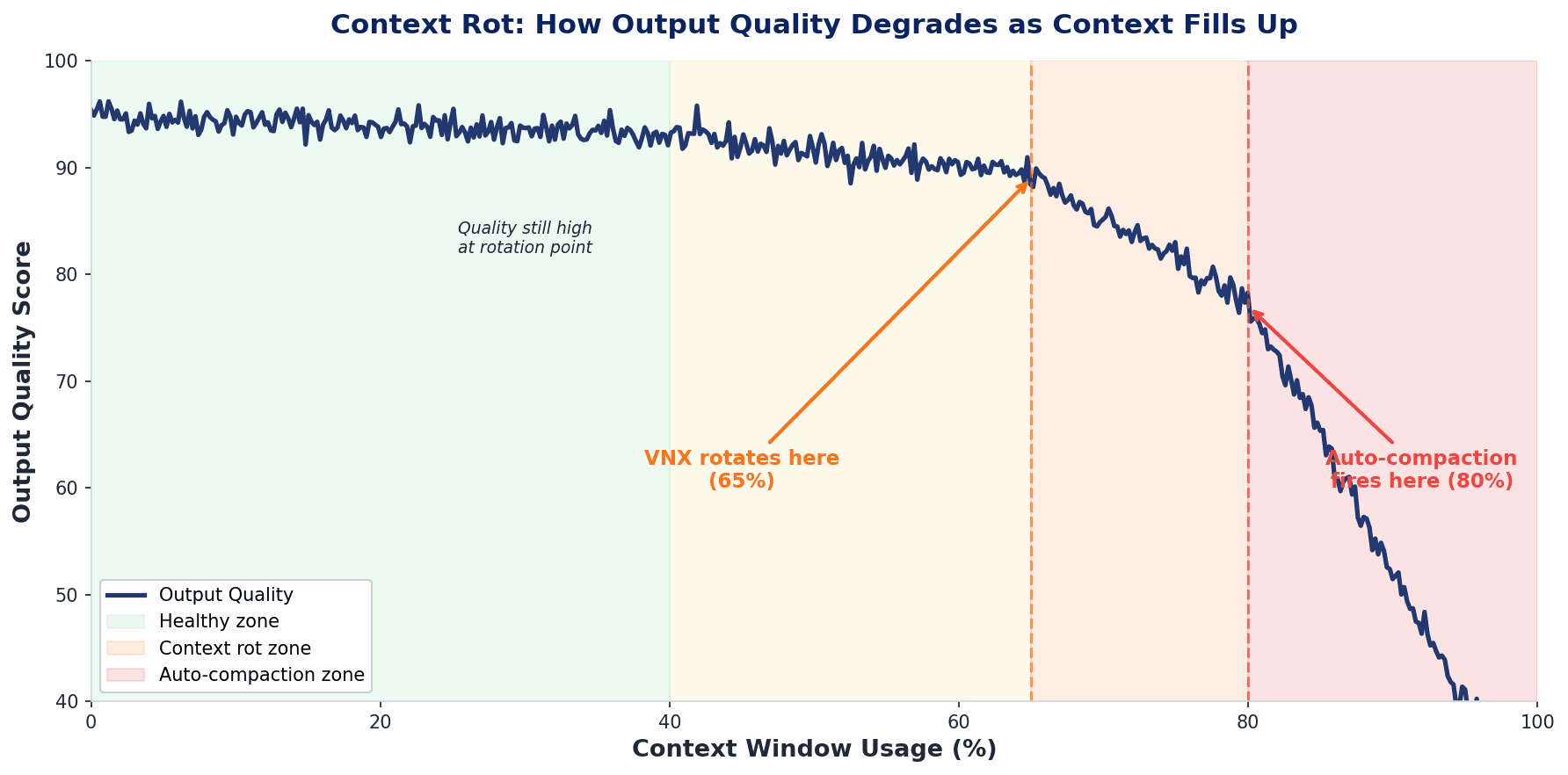
TL;DR: Context rot is the silent degradation of AI model performance during long sessions. It happens when the context window fills up past roughly 65% and the model starts forgetting earlier decisions, repeating work, and contradicting its own analysis, usually without any error or warning. You fix it by detecting context pressure early, saving session state to a structured handover document, clearing the window, and reloading the handover into a fresh session.
What is context rot in Claude Code?
Claude Code operates within a fixed context window of roughly 200,000 tokens. Every message, every file read, every tool result consumes part of that budget. When the window approaches capacity, Claude Code activates auto-compaction: it summarizes earlier messages to free up space.
This is where rot begins.
Auto-compaction is lossy compression on your working memory. It doesn't crash your session; it silently drops nuance. The summary of a 50-line architectural discussion becomes a single sentence. The specific test failure you debugged for 20 minutes gets compressed to "fixed test issues." The agent loses the why behind decisions and retains only a shallow what.
This isn't just my experience. It's well-documented in research. Stanford's "Lost in the Middle"(Liu et al., TACL 2024) showed that LLM performance degrades significantly when models must access information in the middle of long contexts, with performance drops of 15-47% as context length increases. A 2025 study on**"Context Discipline and Performance Correlation"confirms that reasoning accuracy and retrieval reliability degrade under maximum context loads, regardless of model size. And theNeedle in a Haystack research** demonstrated something counterintuitive: context length alone hurts performance even when retrieval is perfect. More context doesn't help. It actively makes things worse.
The symptoms are predictable once you know what to look for. The agent repeats work it already completed, re-reading files it read 30 minutes ago because the compacted summary doesn't mention them. It makes decisions that contradict earlier analysis, because the analysis was compressed away. Multi-step tasks fail in the middle stages because intermediate state vanished during compaction. The most insidious symptom: you don't notice until the output is wrong, because the agent's confidence never wavers. It just confidently produces worse work.
This is different from a model getting confused or hallucinating. Context rot is a structural problem: the information was there, the agent made good decisions based on it, and then the system silently removed it. The agent didn't make a mistake. Its working memory was taken away. Understanding how context flows through multi-agent systems is essential for building reliable AI workflows.
📖 Read also: Receipts, Not Chat Logs: Glass Box Governance: How audit trails help you detect quality degradation early
Why /clear isn't the answer
The obvious fix is /clear: wipe the context and start fresh. But /clear is a nuclear option. You lose everything: task state, files touched, progress made, architectural decisions, the entire working memory of the session. Starting over from scratch.
For simple tasks, that's fine. For a multi-hour implementation session where you're six PRs into a feature plan? Starting from zero is brutal.
I looked for a middle ground. What I wanted was simple in concept: detect that context is filling up, save the important state, clear the window, and resume from the saved state. A checkpoint-and-rotate pattern.
The problem: you can't trigger /clear from a Claude Code hook. There's a community feature request for this: issue #9118 on the Claude Code repository. Anthropic closed it as NOT_PLANNED. That issue has 200+ upvotes from developers hitting the same wall.
So I built a workaround.
The tmux workaround
The key insight: Claude Code runs inside tmux panes in my multi-terminal orchestration setup. And tmux can send keystrokes to any pane, including typing /clear and pressing Enter. You can't call /clear from a hook, but you can call it from outside the process entirely.
That tmux mechanism has since become the basis for more than rotation. The ephemeral tmux-spawn lane, which is becoming the default worker lane, uses the same tmux send-keys approach to launch a fresh interactive Claude Code window for every dispatch. The June 15 Anthropic billing change is the driver: headless claude -p moves to paid API credits, while interactive Claude Code stays on subscription. A fresh tmux window per dispatch preserves the subscription model. Rotation and spawning now share the same tmux infrastructure, but for different lifecycle events.
This opened the door to a fully automated rotation pipeline.
<!-- VISUAL: Architecture diagram showing the 3-hook pipeline flow from PreToolUse detection through tmux /clear to SessionStart recovery -->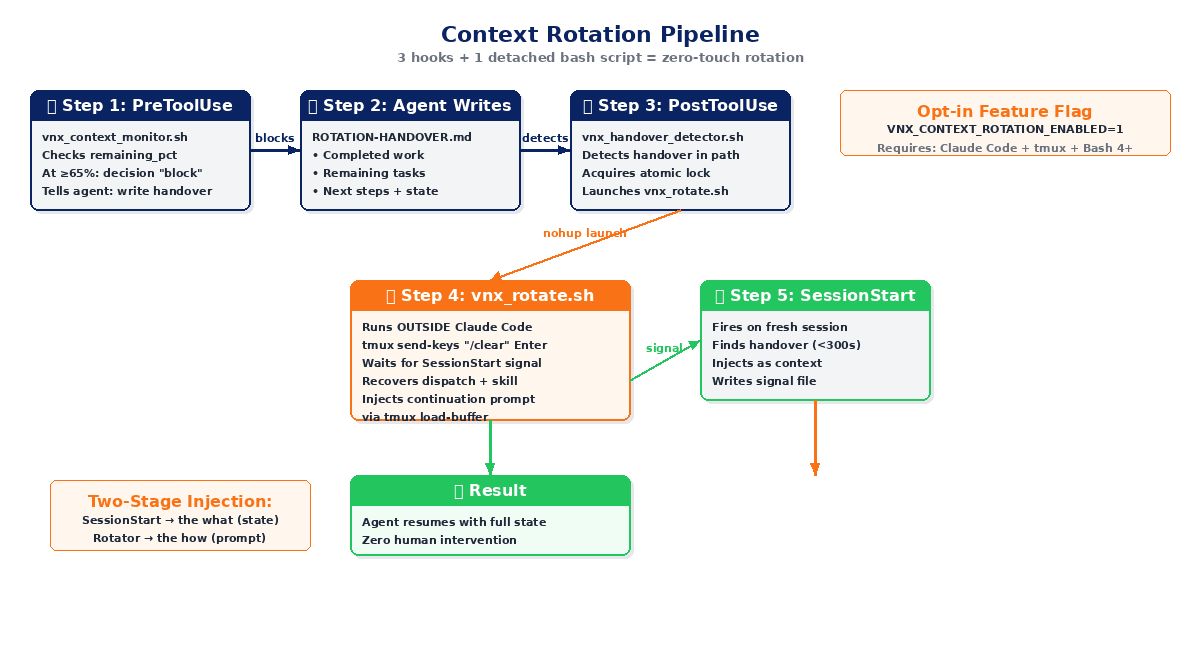
How the rotation pipeline works
The system uses three Claude Code hooks and one detached bash script. Here's the flow:
Step 1: Detect pressure (PreToolUse hook)
A hook called vnx_context_monitor.sh fires before every tool call. It reads the context_window data from Claude Code's hook input and checks the remaining_pct field.
When context usage hits 65% or higher, the hook returns decision: "block", literally stopping the agent mid-task and telling it: "You're running out of context. Write a handover document before proceeding."
Why 65% and not 80%? Because Claude Code's built-in auto-compaction fires around 80%. Rotating 15 points earlier gives the pipeline enough headroom to complete the handover and execute /clear before auto-compaction can race and win. If auto-compact fires first, you lose the nuance you're trying to preserve.
Step 2: Detect the handover (PostToolUse hook)
The agent, now blocked from continuing its task, does the one thing it's still allowed to do: write a file. Specifically, it writes ROTATION-HANDOVER.md, a structured markdown document containing the current task state.
A second hook, vnx_handover_detector.sh, watches for file writes. When it detects a file with ROTATION-HANDOVER in the path, it knows the agent has completed its handover. It acquires an atomic lock (to prevent race conditions if multiple terminals rotate simultaneously) and launches the rotator script vnx_rotate.sh as a detached process via nohup.
Step 3: Clear and inject (the rotator + SessionStart hook)
The rotator script runs outside Claude Code's process entirely. It:
- Resolves the correct tmux pane for the terminal
- Sends
/clearviatmux send-keys - Waits for a signal file from the SessionStart hook (up to 15 seconds)
- Extracts the Dispatch-ID from the handover document
- Recovers the original dispatch file and agent skill
- Injects a continuation prompt via
tmux load-buffer+paste-buffer
Meanwhile, the SessionStart hook fires on the fresh session and finds the most recent handover document (less than 300 seconds old). It injects the handover content as context, so the new session knows what was happening.
Two-stage injection: the SessionStart hook provides the what (task state, progress, remaining work), and the rotator provides the how (the continuation prompt with the correct skill and dispatch context).
The agent picks up exactly where it left off. Zero human intervention.
The handover contract
The handover document is the critical artifact. It's what bridges the old session and the new one. Here's a real example:
# T1 Context Rotation Handover
**Dispatch-ID**: pdf-assembler-split
**Context Used**: 67%
## Completed Work
- Scanned 7/11 SME targets (14 reports generated)
- Fixed browser pool memory leak (PR-3)
## Remaining Tasks
- Scan remaining 4 targets
- Generate comparison matrix
## Next Steps for Incoming Context
1. Continue SME scan batch from target #8
2. Server running on PID 42891, port 8077This isn't a transcript dump. It's a structured task state: enough for the incoming session to continue without re-reading the full conversation. Completed work, remaining tasks, and specific next steps with concrete details (PID numbers, port numbers, which target to start from).
The format is constrained deliberately. Claude writes this under context pressure, and context is running low by design. A freeform summary would be unreliable. The structured sections (Completed / Remaining / Next Steps) constrain the output enough to be consistently useful.
What nobody else has built
I analyzed five open-source projects attempting parts of this problem. None solve the full loop:
| Project | Auto-detect | tmux /clear | Handover inject | Atomic locking | Zero-touch |
|---|---|---|---|---|---|
| VNX Context Rotation | ✅ PreToolUse hook | ✅ async nohup | ✅ SessionStart + rotator | ✅ mkdir + TTL | ✅ |
| claude-code-handoff | — manual /handoff | — | ✅ SessionStart hook | — | — |
| claude-session-restore | — manual CLI | — | ✅ transcript parsing | — | — |
| claude_code_agent_farm | Semi (threshold flag) | ✅ Ctrl+R broadcast | — task queue restart | — | — |
| /wipe gist | — manual /wipe | ✅ send-keys | ✅ paste-buffer | — | — |
| claude-code-context-sync | — manual save | — | ✅ cross-window sync | — | — |
Here's what each project misses:
claude-code-handoff is the most recent (February 2026). It uses a /handoff slash command that generates a context file, which a SessionStart hook injects on the next session. Solid recovery mechanism, but you have to manually decide when to rotate and manually trigger /clear. No pressure detection, no automation.
claude-session-restore takes a different approach entirely: it's a Rust CLI that parses JSONL session files after the fact. Multi-vector analysis (tasks, user messages, tool operations, git history) to reconstruct context. Powerful for forensics, but it's a reconstruction tool, not a real-time intervention.
claude_code_agent_farm is the most architecturally similar to what I built: multi-agent tmux orchestration with 20+ parallel agents. It has a --context-threshold parameter that lets agents self-clear. But after clearing, agents restart from their task queue with no handover document. Session continuity is lost. The work the agent did before clearing? Gone, unless it happened to commit something.
The /wipe gist is technically closest to the VNX rotation flow. It uses the same tmux send-keys + load-buffer + paste-buffer pattern for clearing and injecting. But it's a manually triggered slash command with a fixed 8-second delay instead of signal-based coordination. No locking, no multi-terminal awareness, no automatic pressure detection.
claude-code-context-sync focuses on multi-window context synchronization, saving and resuming context across different windows. Useful for a different workflow, but no automatic detection or clearing.
The gap: every project solves one or two parts of the problem. None connect all four: automatic detection → structured handover → tmux clear → continuation injection. That's the closed loop I couldn't find and had to build. The full implementation is open source on GitHub, including the hook chain, lock mechanism, and handover templates.
There are also multiple open feature requests on the Anthropic Claude Code repositoryasking for native solutions to this problem, fromcontext window reset without session restarttosession handoff and continuity supporttocontext management CLI flags. The original hook-based /clear request (#9118)was closed as NOT_PLANNED, and related issues likerestoring blocking Stop command hooks (#3656)and/clear breaking transcript hooks (#3046) remain open. The demand is clear. The supply, for now, is community workarounds.
The safety mechanisms
Running automatic context rotation in production requires more than just the happy path. Here's what I built to prevent things from going wrong:
Atomic locking. When the PostToolUse hook triggers rotation, it acquires a mkdir-based lock with timestamp-based stale detection (300-second TTL). This prevents double-rotation when multiple terminals try to rotate simultaneously. One terminal rotates; the others wait.
Loop prevention. The PreToolUse hook passes Write, Read, Glob, and Grep through unconditionally, even when context pressure is high. This is critical. Without it, the hook would block the agent from writing the handover document, creating a deadlock where the agent needs to write a file to rotate but can't write a file because rotation is pending.
Multi-terminal isolation. Each terminal (T1/T2/T3) has independent pane resolution, lock files, and handover documents. T0 (the orchestrator) is excluded from rotation entirely. The orchestrator's context is long-lived by design and manages terminal coordination, so clearing it would break the system.
Fallback chain. The SessionStart recovery hook supports a --fallback parameter so worker terminals bootstrapping fresh tasks don't get confused by rotation recovery. A fresh dispatch shouldn't inherit a rotation handover from a previous task.
What I learned about timing
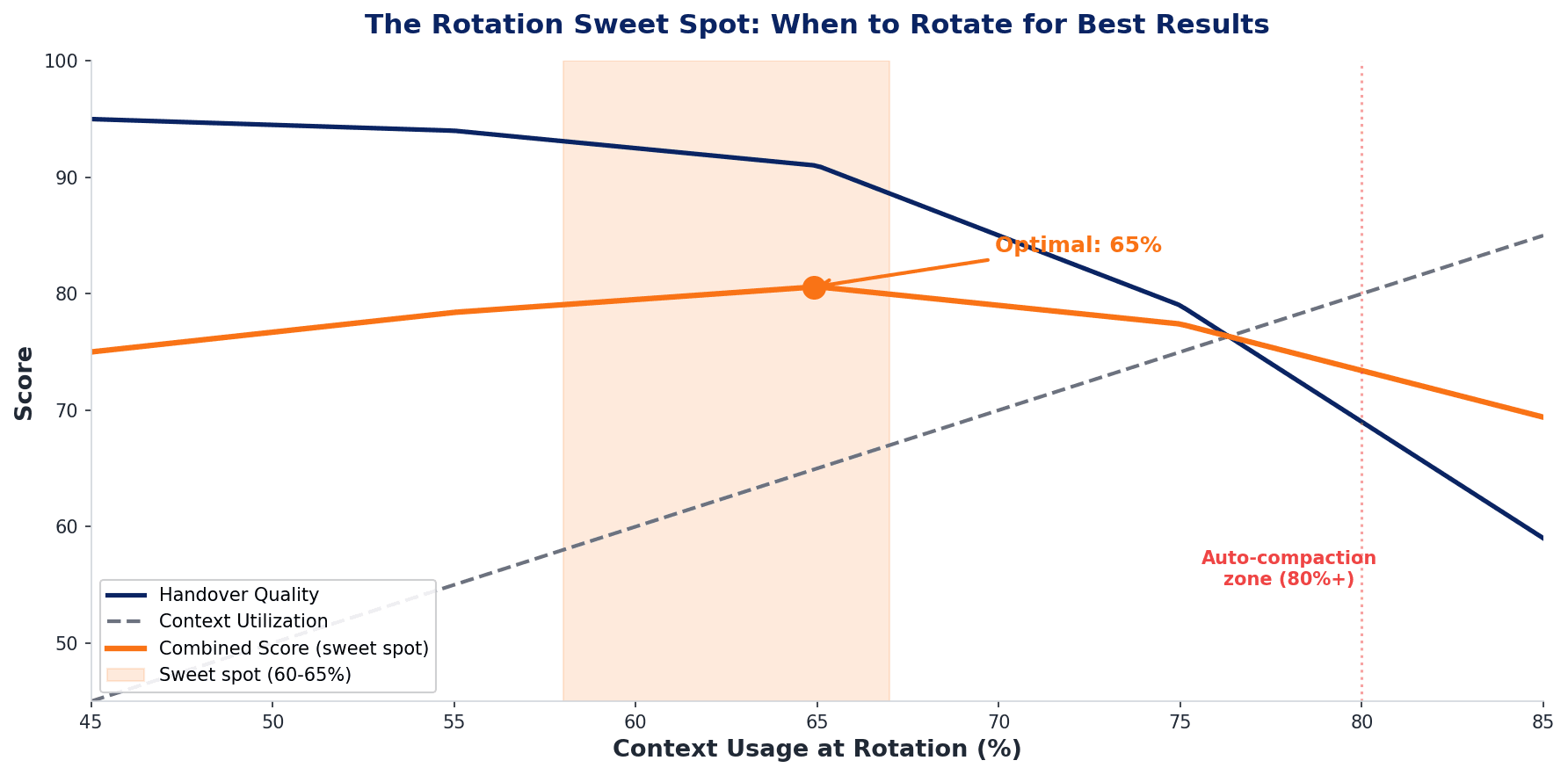
The biggest surprise from production testing: 65% is already late. I'm now experimenting with rotation at 60%, even 55% for complex tasks where context quality is critical.
The reasoning: context quality doesn't degrade linearly. This aligns with the research: the "Lost in the Middle" paper showed that degradation accelerates in the later portions of the context window, not gradually across the full length. At 50% context usage, everything is fine. At 65%, you start losing nuance in the compacted regions. At 75%, the agent is noticeably worse, re-reading files and contradicting earlier decisions. By 80%, Claude Code's auto-compaction fires and you've lost the war.
The sweet spot appears to be rotating when the context is still healthy, before you notice degradation, not after. It feels wasteful to clear a session that's still working well. But the handover quality is much higher when the agent writes it from a position of strength rather than under pressure. An agent at 60% context writes a clear, structured handover with specific details. An agent at 78% writes vague summaries and misses critical state.
I track every rotation event in the VNX receipt ledger, the same append-only NDJSON file that logs all agent actions. This gives me data on rotation frequency, handover quality, and task completion rates before and after rotation. Early data suggests that proactive rotation (60-65%) produces better handover documents and faster task resumption than reactive rotation (75%+).
Receipts are now provider-aware. Each rotation event carries the provider, model, and token or cost data for the session. This lets me correlate rotation frequency with lane-specific behavior. A rotation in the claude-subprocess lane looks different from a rotation in the ephemeral tmux-spawn lane. The provider metadata turns the rotation log from a generic event stream into a lane-specific health signal.
"The best time to rotate context is when you don't think you need to yet." That's the counterintuitive lesson from six months of production data. An agent writing a handover at 60% context produces clear, structured state. At 78%, it writes vague summaries and misses critical details. Rotate from strength, not desperation.
Known limitations
I want to be honest about what doesn't work perfectly.
tmux timing race. There's a small window (~1-2 seconds) after /clear where the terminal may not be ready for input. The rotator mitigates this with a settle delay and signal file, but it's not 100% deterministic. Occasionally the continuation prompt arrives before the session is fully initialized.
Handover quality varies. The handover document is written by Claude under context pressure. Sometimes the "Remaining Tasks" section is vague. Sometimes critical details are missing. The structured format constrains it enough to be usually useful, but "usually" isn't "always."
No native Anthropic support.This entire system exists because /clear can't be called from hooks (#9118, NOT_PLANNED). If Anthropic ever adds**native context management support**, the tmux workaround becomes unnecessary. Good riddance. The workaround works, but it's fragile compared to what a native implementation could be.
Even if native context management arrives, tmux itself will remain central to VNX because of the ephemeral tmux-spawn lane. That lane depends on the same tmux send-keys and paste-buffer primitives, though for spawning rather than rotating. The billing reality is that headless claude -p is becoming a paid API path. Interactive tmux windows are the cost-preserving alternative.
Skill context lost on /clear. Active Claude Code skills are not preserved across rotation. The rotator re-activates the original skill via a /{skill} prefix on the continuation prompt, recovered from the original dispatch file. This works, but it means the skill reloads from scratch. Any in-session skill state is lost.
📖 Read also: Zero-LLM Context Injection: How VNX Gives AI Agents the Right Code at the Right Time: the companion technique that prevents context from bloating in the first place
Try it yourself
Context rotation is part of the VNX Orchestration System, an open-source toolkit for multi-agent terminal workflows. The rotation feature is opt-in:
export VNX_CONTEXT_ROTATION_ENABLED=1You need Claude Code with hooks support, tmux, and Bash 4+. The full setup is three hook registrations in .claude/settings.json and one environment variable. The documentation covers the complete hook chain, file structure, and configuration options.
📖 Read also: Multi-Model AI Orchestration From a Single Terminal: How I run Claude, Codex, and Gemini in parallel with unified governance
The dry-run demo (demo/dry-run/replay.sh --fast) shows the full governance pipeline, including context rotation, without requiring any LLM API calls.
How to fix context rot in Claude Code
Detect context pressure early
Save state to a structured handover document
Clear the session and reload the handover
Frequently asked questions
Update: June 2026
VNX reached 1.0 code-freeze in early June. The context rotation pipeline described here is still in production, but it now shares infrastructure with the ephemeral tmux-spawn lane. That lane is becoming the default worker path, driven by the June 15 Anthropic billing change that moves headless claude -p to paid API credits. Rotation resets a long-lived session; tmux-spawn creates a fresh one per dispatch. Both use the same tmux primitives. Receipts are now provider-aware, so I can correlate rotation health with the lane that produced it. The core lesson has not changed: rotate before you think you need to.
The bigger question
Context rot isn't a Claude-specific problem. Every AI coding agent with a fixed context window will hit this wall. Cursor, Cline, Codex CLI, Gemini Code: they all operate within context limits, and they all degrade when those limits are reached.
The solution doesn't have to look like mine. But the pattern (detect pressure, checkpoint state, clear, resume) is universal. Whether it's implemented as hooks + tmux, or native IDE support, or a language server protocol extension, the need is the same: AI coding sessions need a way to rotate context without losing continuity.
For organizations looking to deploy AI agents in production, this challenge is amplified. Smaller companies adopting AI especially need reliable, low-friction solutions. They can't afford to lose work due to context degradation.
Right now, most developers just accept context degradation as a fact of life. They restart sessions manually, lose progress, and re-explain their codebase from scratch. That's the equivalent of rebooting your computer every hour because it runs out of RAM. We can do better.
If you're hitting the context wall in your AI coding workflow, I'd be curious to hear how you handle it. And if you have ideas for improving automatic rotation (better handover formats, smarter timing heuristics, alternative clear mechanisms), the repo is open and I'm building in public.
If you're interested in the multi-agent system that context rotation is part of, read Glass Box Governance: How I Built a Self-Auditing Multi-Agent AI System: where I explain the full orchestration architecture, receipt-driven audit trails, and why transparency beats trust in production AI.
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.