Every time I dispatch a task to one of my AI agents, it arrives with something extra: a curated set of code patterns, prevention rules, and warnings, all specific to the task at hand. The agent doesn't request this context. It doesn't know it's being augmented. The intelligence just appears in the prompt, ready to use.
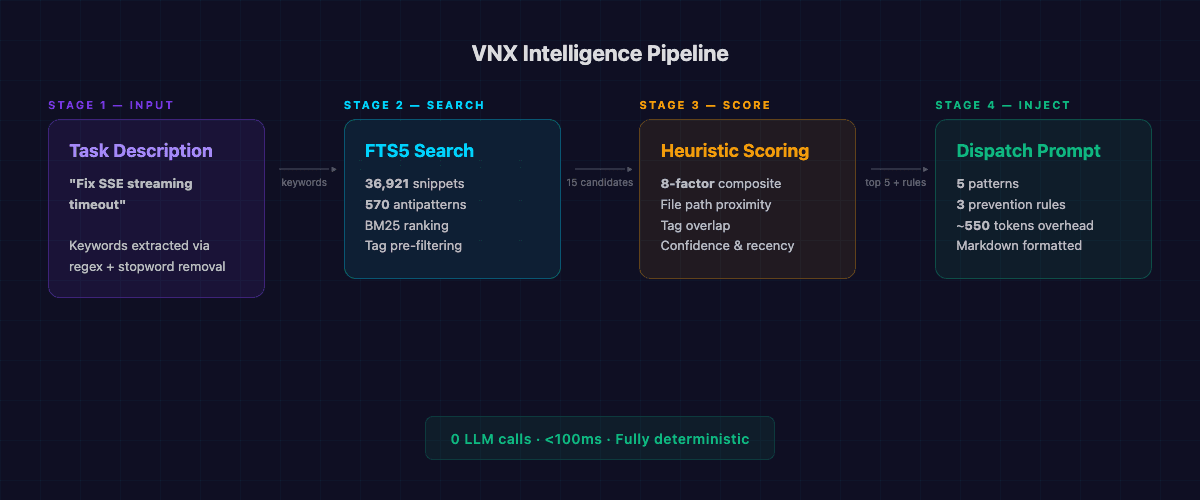
The system behind this is the VNX Intelligence Engine. It indexes my entire codebase (36,921 code snippets, 570 known antipatterns, 380 mined reports) into an FTS5 full-text search database. When a dispatch is created, the engine queries this database, scores the results with an 8-factor heuristic, and injects the top 5 most relevant patterns directly into the agent's prompt. No LLM calls. No RAG pipeline. No vector embeddings. Just SQLite FTS5 and deterministic scoring.
The result: every agent starts every task with relevant context it didn't have to search for. And it costs exactly zero additional tokens to decide what to inject.
The problem: agents start every task blind
If you've worked with AI coding agents, you've seen the pattern. You give an agent a task, say "fix the SSE streaming timeout," and it starts by reading files. Lots of files. It explores the directory structure, opens related modules, scans imports, and eventually builds enough context to attempt a solution. This exploration phase burns tokens and time, and the agent often misses relevant code that lives in unexpected places.
In a multi-terminal setup where three agents work in parallel, this problem triples. Each agent independently explores the same codebase, often reading the same files, missing the same patterns, and repeating the same mistakes that a previous agent already encountered. And because every terminal starts with a clean context window, there's no accumulated knowledge to fall back on. Each dispatch is a fresh start.
The naive solution is to give every agent the entire codebase context. But that's 50,000+ lines of production code, far beyond any context window. Even with aggressive summarization, you'd need an LLM call just to decide what context to include, which defeats the purpose.
I needed something different: a system that could find the 5 most relevant code patterns for any given task, in under 100 milliseconds, without calling any AI model.
How the intelligence engine works
The VNX Intelligence Engine operates in four stages: index, search, score, and inject. Each stage is deterministic; given the same input, you get the same output every time.
Stage 1: Indexing the codebase
Two specialized extractors continuously index the codebase into an FTS5 database:
The Code Snippet Extractor uses Python's AST parser to walk every source file and extract individual functions with their signatures, docstrings, and line ranges. Not file-level chunks; function-level precision. When the intelligence engine suggests create_gauge_chart, it points to dashboard.py:145-167, not just "somewhere in dashboard.py."
The Doc Section Extractor does the same for markdown documentation: it splits files at heading boundaries, scores each section for information density, and stores them with their exact line ranges. A section about SSE event schemas gets indexed separately from the deployment guide in the same file.
Code Snippet Extractor (AST) Doc Section Extractor (Markdown)
├── Parse Python files ├── Split at heading boundaries
├── Extract function signatures ├── Score information density
├── Capture docstrings + body ├── Extract code blocks within sections
├── Record line ranges (start:end) ├── Record heading hierarchy
└── Store in FTS5 with metadata └── Store in FTS5 with quality scoreThe result is a single SQLite database with FTS5 full-text indexing across all code and documentation. Every entry carries metadata: file path, line range, language, component tags, and a quality score.

Stage 2: FTS5 full-text search
When a dispatch is created, the engine extracts keywords from the task description, using a simple regex-based extraction with stopword removal, no ML involved. These keywords become an FTS5 query:
SELECT snippet_id, title, file_path, line_range, description,
quality_score, rank
FROM code_snippets
WHERE code_snippets MATCH '"sse" OR "streaming" OR "timeout"'
AND quality_score >= 85
ORDER BY rank, quality_score DESC
LIMIT 15FTS5 uses BM25 ranking internally, the same algorithm that powered early Google. It finds patterns where the query terms appear frequently in the snippet but rarely across the whole database. The LIMIT 15 retrieves 3x the final count, giving the scoring stage room to re-rank.
A key pre-filter narrows the search space before scoring:
Component tag filtering extracts hints from the task description and narrows the full pattern database to the subset relevant to the task at hand. A task about API validation doesn't need patterns about chart rendering. This typically narrows thousands of patterns to a few hundred candidates, an 85% reduction in search space.
Stage 3: Heuristic relevance scoring
The raw FTS5 results go through an 8-factor composite scoring function:
relevance = keyword_density × 0.15 # How many query terms appear
+ tag_overlap × 0.15 # Component tag match
+ file_path_proximity × 0.20 # Same file or directory
+ quality_score × 0.15 # Code quality metric
+ usage_count × 0.10 # How often agents used this pattern
+ confidence × 0.10 # Learning loop adjustment
+ recency × 0.10 # When the pattern was last relevant
+ cache_confidence × 0.05 # TTL-based cache freshnessThe weights reflect hard-won lessons. File path proximity gets the highest weight (0.20) because patterns from the same directory are almost always more relevant than semantically similar patterns from elsewhere. Usage count and confidence are lower (0.10 each) because the learning loop needs time to accumulate signal.
The scoring function is pure Python: no matrix operations, no model inference. It runs in under 50ms for the full candidate set.

Stage 4: Injection into the dispatch
The top 5 patterns and top 3 prevention rules get formatted as markdown and injected directly into the agent's prompt, between the skill activation and the task instructions:
Use the @backend-developer skill.
---
## Intelligence Context
### Relevant Patterns
- **handle_sse_disconnect** (relevance: 0.97): Graceful SSE client
disconnect with retry backoff and connection cleanup
@ `event_stream.py:89-134`
- **validate_stream_payload** (relevance: 0.91): Schema validation
for SSE event payloads before broadcast
@ `stream_validator.py:45-72`
### Prevention Rules
- Always close SSE connections in finally blocks, 3 incidents of leaked connections in Q1
- Test SSE timeouts with simulated slow clients, not just fast localhost
---
Fix the SSE streaming timeout that causes client disconnects after 30 seconds of inactivity.The agent receives this as part of its prompt. It doesn't know the context was injected -- it just sees relevant code references and warnings alongside its task. From the agent's perspective, the dispatcher simply gave it well-researched instructions.
Total overhead: ~550 tokens per dispatch. For comparison, having the agent search for this context itself would cost 2,000-5,000 tokens in tool calls and file reads -- assuming it found the right patterns at all.
This injection step is now part of a uniform PREPARE phase that runs across every lane in the system. The full assembled instruction carries: the skill body (what the agent should do), a permission preamble scoping which tools it actually needs, the intelligence context from FTS5 (what it should know), and a report-contract directive (what structure its output must follow). The intelligence engine is the "know" layer -- one of four components, each deterministic, each costing zero LLM calls.
The tag taxonomy: how the system knows what's relevant
Raw keyword matching gets you 60% of the way. The other 40% comes from the tag taxonomy, a structured categorization system that groups patterns by phase, component, issue type, and severity.
Phase Tags Component Tags Issue Tags Severity Tags
├── design ├── crawler ├── validation-error ├── critical-blocker
├── implementation ├── storage ├── performance ├── high-priority
├── testing ├── api ├── memory-problem ├── medium-impact
└── production └── frontend └── race-condition └── low-impactThese tags describe the code patterns, not the agents or terminals. When a dispatch mentions "API validation," the engine filters patterns to those tagged with api-component and validation-error. The filtering is entirely task-driven; any agent on any terminal might receive these patterns, depending on what task it's assigned.
The taxonomy also drives prevention rule generation. When a tag combination appears in 2+ antipatterns (say api-component + memory-problem), the system automatically generates a prevention rule: "API tasks involving memory management have a 40% failure rate. Implement explicit memory budgets before starting."
These rules aren't written by hand. They're mined from the 570 antipatterns in the database, weighted by occurrence frequency. The more times a particular failure mode appears, the higher confidence the prevention rule carries.
📖 Read also: Glass Box Governance: the four architectural pillars that make multi-agent workflows auditable
The learning loop: patterns that earn their place
Static pattern matching degrades over time. Code changes, new modules appear, old patterns become irrelevant. The intelligence engine handles this through a feedback loop that adjusts confidence scores based on actual usage.
Here's how it works:
-
Offer: When patterns are injected into a dispatch, their hashes are recorded as "offered."
-
Track: When the agent completes the task, the receipt captures which patterns were actually referenced in the agent's work.
-
Score: Patterns that were used get a 10% confidence boost. Patterns that were offered but ignored get a 5% daily decay. Patterns associated with failed tasks get a 20% penalty.
-
Rank: Next time a similar task comes up, the adjusted confidence scores shift the ranking. Patterns that consistently help rise to the top. Patterns that agents consistently ignore gradually fade.
Dispatch created
↓ offered_pattern_hashes: [a1b2, c3d4, e5f6, g7h8, i9j0]
Agent completes task
↓ used_pattern_hashes: [a1b2, e5f6]
Confidence adjustment
↓ a1b2: confidence × 1.10 (used)
↓ c3d4: confidence × 0.95 (ignored)
↓ e5f6: confidence × 1.10 (used)
↓ g7h8: confidence × 0.95 (ignored)
↓ i9j0: confidence × 0.95 (ignored)This isn't machine learning. There's no model training, no gradient descent, no GPU required. It's bookkeeping with exponential moving averages. But over hundreds of dispatches, it produces a surprisingly effective relevance signal. Patterns that help agents succeed float to the top. Patterns that don't, sink.
The daily learning cycle runs at 18:00, processing all receipts from the past 24 hours. The entire cycle takes under a minute; it's just database updates.

How this compares to other approaches
I'm not the first person to think about giving AI agents better context. The landscape of code-aware AI tools has exploded, and most of them solve some version of this problem. Here's how the major approaches compare:
| Approach | Retrieval method | LLM calls for retrieval | Latency | Deterministic | Semantic understanding | Infrastructure |
|---|---|---|---|---|---|---|
| VNX Intelligence | FTS5 + heuristic scoring | 0 | <100ms | Yes | Limited (tag-compensated) | SQLite (local) |
| RAG pipelines (LangChain, LlamaIndex) | Vector embeddings + cosine similarity | 1-2 per query (embed + rerank) | 200-500ms | No | Strong | Vector DB (Pinecone, Weaviate, etc.) |
| Cursor / Copilot | Embedding-based code search | 1 per query | 100-300ms | No | Strong | Cloud API |
| Aider repo map | Tree-sitter AST → token-optimized map | 0 | <50ms | Yes | None (structural only) | Local |
| Sourcegraph Cody | Code graph + embeddings | 1 per query | 200-400ms | No | Strong | Sourcegraph instance |
| CLAUDE.md / rules files | Static, manually curated | 0 | 0ms (always loaded) | Yes | N/A | Filesystem |
| Agent self-search | LLM reads files, runs grep | 5-20 per task | 10-60s | No | Strong | None (built-in) |
Every approach makes a different tradeoff. RAG and embedding-based systems win on semantic understanding: they'll connect "rate limiting" to "throttling" even if the terms don't co-occur. Aider's repo map wins on simplicity; it's elegant, zero-dependency, and fast. Static rules files (like CLAUDE.md) win on reliability: no moving parts, no failure modes.
VNX trades semantic depth for three properties that matter more in a governance context:
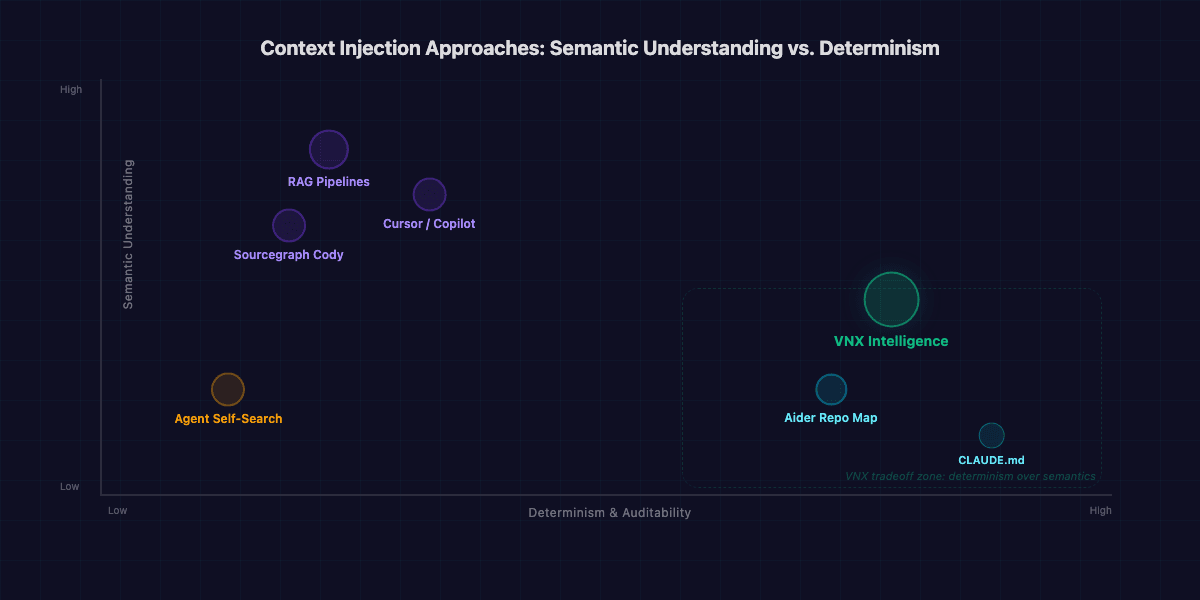
The architectural decisions behind "no RAG, no external memory"
This isn't a "RAG bad" argument. It's a set of deliberate tradeoffs driven by the constraints of multi-agent governance.
Decision 1: Determinism over semantics
FTS5 + heuristic scoring produces the same results for the same input, every time. Vector similarity search doesn't. Embeddings drift with model updates, and cosine similarity produces subtly different rankings depending on the embedding model version.
This matters because every dispatch in VNX produces a receipt. When something goes wrong, I reconstruct the chain: what context did the agent receive? Why those patterns and not others? With FTS5, the answer is traceable: these keywords matched, these tags overlapped, this file path proximity score was highest. With embeddings, the answer is "the vectors were close in 1536-dimensional space," which tells you nothing actionable.
What I give up: An agent working on "rate limiting" won't automatically get patterns about "throttling" unless both terms appear in the same snippet. The tag taxonomy covers most of these gaps, but not all.
Why it's worth it: In eight months, I've debugged context injection issues exactly four times. Each time, I traced the problem in under 5 minutes because the scoring is fully transparent. With an opaque similarity score, those would have been hour-long investigations.
Decision 2: Zero external dependencies
The intelligence engine runs entirely on SQLite: the same machine, the same process, no network calls. No vector database to host, no embedding API to pay for, no service to keep running.
This is an architectural constraint I chose early in building VNX: every component must work offline, on a single machine, with no external services. Not because cloud services are bad, but because external dependencies in an orchestration layer create failure modes that compound across agents. If Pinecone is slow, all three workers wait. If the embedding API rate-limits, the dispatch queue backs up. If the vector DB corrupts, intelligence degrades silently.
With SQLite FTS5, the failure mode is "disk read fails," which means the entire machine is down anyway.
| Consideration | External memory (Pinecone, Weaviate) | Local FTS5 (VNX) |
|---|---|---|
| Setup complexity | Managed service or self-hosted | pip install + SQLite (built-in) |
| Monthly cost | $70-300/mo (managed) | $0 |
| Failure modes | Network, auth, rate limits, cold starts | Disk I/O only |
| Embedding updates | Re-embed on code changes ($) | Re-index on code changes (free) |
| Semantic search | Native | Not supported (tag-compensated) |
| Auditability | Score only | Full factor breakdown |
| Offline capable | No | Yes |
Decision 3: No LLM in the retrieval path
Embedding 36,000+ code snippets requires an embedding model. Updating embeddings when code changes requires more calls. Querying requires yet more calls. A single dispatch could trigger 2-3 LLM API calls just to decide what context to include, before the agent even starts working.
At dozens of dispatches per day, that's hundreds of additional API calls. Not expensive individually, but it adds up; and more importantly, it adds latency and failure modes to the critical path. The intelligence engine runs in the dispatch pipeline: if it's slow, every task is slow. If it fails, no task gets context.
By keeping the retrieval path LLM-free, I reserve all model capacity for the actual work. The agents get relevant context in <100ms, and the only API calls are the ones where agents think and write code.
The principle: cheap, fast, and deterministic for context retrieval. Expensive and creative for the actual work. Don't use a $0.01 API call to decide what to feed a $0.15 API call; use a $0.00 database query instead.
The numbers
After eight months of production use, the system has reached a scale that makes the deterministic approach viable:
| Metric | Value |
|---|---|
| Code snippets indexed (FTS5) | 36,921 |
| Known antipatterns | 570 |
| Mined reports | 380 |
| Patterns injected per dispatch | 5 |
| Prevention rules per task | 1-4 |
| Query latency (cached) | <10ms |
| Query latency (uncached) | <100ms |
| Intelligence overhead per dispatch | ~550 tokens |
| Token savings vs. agent self-search | 80-95% |
| LLM calls for context decisions | 0 |
The 80-95% token savings come from comparing two approaches: agents that search for context themselves (reading files, running grep, exploring directories) vs. agents that receive pre-computed context in their prompt. The token management techniques across the full VNX system go even further, but the intelligence engine is the single biggest contributor.
What this means in practice
A concrete example from yesterday. I dispatched a task: "Add retry logic to the KVK API client for transient failures."
The intelligence engine:
- Extracted keywords:
retry,KVK,API,client,transient,failures - Filtered to patterns tagged with API-related components (~450 candidates)
- Boosted patterns from
kvk_client.pyand related files - Found 3 existing retry implementations in the codebase, a prevention rule about KVK rate limits, and an antipattern about retry storms from a previous incident
- Injected all of this into the dispatch in 87ms
The agent received the task with full context: here's how retry is implemented elsewhere in this codebase, here's a known issue to watch for, and here's a previous failure related to this exact API. It wrote the implementation in one pass, following the existing patterns, avoiding the known pitfalls.
Without the intelligence engine, the agent would have spent 2,000+ tokens exploring the codebase, might have missed the retry storm antipattern entirely, and would have invented its own retry pattern instead of following the established one.
Multiply this by dozens of dispatches per day across multiple agents, and the compound effect becomes significant. The agents don't just save tokens; they produce more consistent code because they're all working from the same pattern library.
"The best context injection is the kind the agent doesn't notice. It just writes better code and doesn't know why."
📖 Read also: Why I Chose NDJSON Over Postgres for My AI Agent Audit Trail: the receipt format that feeds the intelligence learning loop
What's next
The current system is deterministic by design, but there are clear opportunities to add a thin intelligence layer on top:
Citation-based memory: linking patterns to specific git commits so stale patterns (from deleted or refactored code) get automatically flagged and decayed.
Observational memory: compressing receipt ledger data into reusable patterns. The 50,000+ token receipts from completed tasks contain patterns that aren't yet captured in the code snippet database.
None of these require LLM calls for the retrieval path. The principle holds: the decision of what context to inject should be as cheap and deterministic as possible. Save the expensive inference for the actual work.
Update: June 2026
The intelligence engine has been running since this post without architectural changes -- FTS5, heuristic scoring, zero LLM calls, same principle. What changed is the dispatch pipeline around it. The injection step is now the "intelligence" component of a uniform PREPARE phase used across all six worker lanes (Claude tmux-spawn, Claude headless subprocess, Codex, Kimi, Gemini, DeepSeek harness). Every dispatch assembles: skill body + permission preamble + intelligence context + report-contract directive. The engine's job is the third slot -- and it still costs zero tokens to decide what goes in.
The VNX intelligence engine is part of the VNX orchestration system, an open-source multi-agent governance framework. The intelligence engine, FTS5 database, and scoring algorithms are available in the repository.
This post is a companion to the Glass Box Governance series. For the full architecture, from multi-terminal orchestration to quality gates to cascade prevention, start with Part 1.
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.