De benchmarks van Opus 4.7 zijn indrukwekkend. 64,3% op SWE-bench Pro: een sprong van 20% ten opzichte van Opus 4.6. Drie keer meer productietaken opgelost. Hogere scores dan GPT-5.4 op de belangrijkste coding benchmarks.
Maar benchmarks zijn gecontroleerde tests. Ik bouw al maanden met multi-agent systemen in productie. Wat ik wil weten: verandert dit model hoe mijn agents zich gedragen?
Na een dag testen is het antwoord: ja. Niet vanwege de ruwe prestaties, maar vanwege drie verbeteringen die weinig aandacht krijgen, en die precies raken aan hoe ik mijn orkestratie-systeem heb ontworpen.
File-based memory: validatie van een architectuurkeuze
Opus 4.7 schrijft en leest scratchpad-bestanden als standaard gedrag. Het model pakt z'n eigen notities op waar het gebleven was, zonder dat je workarounds hoeft te bouwen om context tussen sessies te bewaren.
Dit is niet zomaar een handige feature. Dit is validatie van een fundamentele architectuurkeuze.
Mijn VNX Orchestration-systeem draait volledig op het filesystem. Geen database. Append-only ledger. NDJSON receipts per beslissing. Context per dispatch. Elk agent-team leest en schrijft naar bestanden: dat is het hele communicatieprotocol.
Toen ik dat een jaar geleden zo ontwierp, was de logica simpel: bestanden zijn universeel, versioneerbaar, en transparant. Elke agent kan ze lezen. Elke ontwikkelaar kan ze inspecteren. Geen vendor lock-in op een specifieke database of messaging-queue.
Dat Anthropic's meest geavanceerde model nu native hetzelfde patroon hanteert, bevestigt die keuze. Opus 4.7 hoeft niet meer "geleerd" te worden om met bestanden te werken. Het doet het vanzelf.

Minder subagents: glass box wint van black box
Vorige versies van Opus hadden de neiging om subagents te spawnen zodra ze de kans kregen. Je gaf een opdracht en het model splitste die op in deeltaken, delegeerde naar subprocessen, en leverde een resultaat, zonder dat je zicht had op wat er tussenin gebeurde.
Dat is black box gedrag. En het is precies wat ik probeer te vermijden met glass box governance.
Opus 4.7 doet dit minder agressief. Het model probeert vaker zelf de taak af te ronden in plaats van te delegeren naar onzichtbare subprocessen.
Waarom dat ertoe doet:
- Traceerbaarheid: ik wil weten welke agent wat deed, wanneer, en waarom. Niet achteraf reconstrueren wat er in een subproces is misgegaan.
- Quality gates: mijn systeem heeft checkpoints tussen elke stap. Subagents omzeilen die gates.
- Kosten: subagents vermenigvuldigen tokengebruik. Minder subprocessen = meer controle over je API-kosten.
De shift van "ik delegeer het wel" naar "ik doe het zelf" past perfect in een architectuur waar controle een ontwerpkeuze is, geen beperking.
📖 Lees ook: Waarom ik geen subagents gebruik in mijn AI-orkestratie: het architectuurprincipe achter minder delegatie en meer controle.
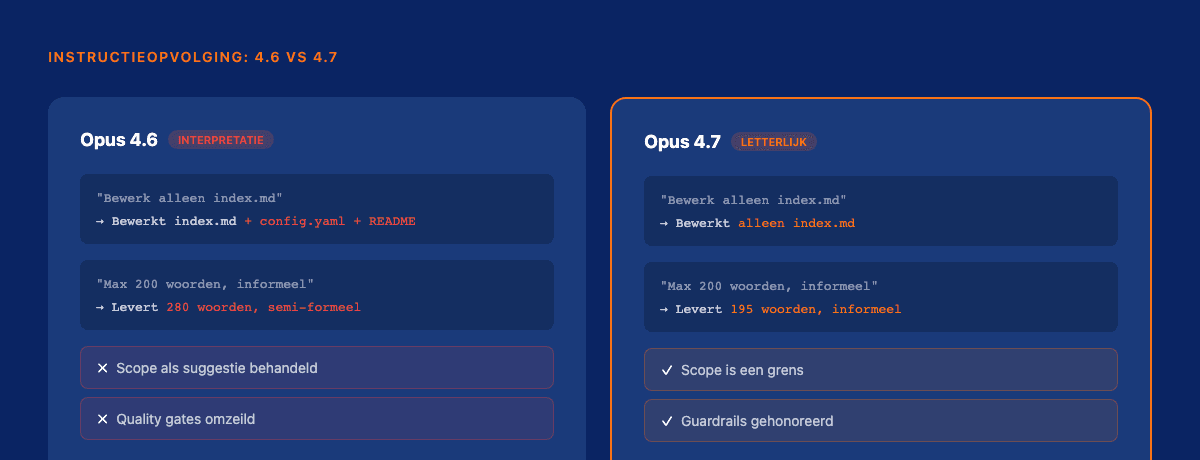
Letterlijkere instructieopvolging: de stille revolutie
Dit is de verbetering die het minste aandacht krijgt en de meeste impact heeft op productieworkflows.
Als je zegt "bewerk alleen dit bestand", dan doet Opus 4.7 dat nu ook echt. Geen interpretatie meer van wat je "waarschijnlijk ook bedoelde." Geen bonuswijzigingen in bestanden die je niet had aangewezen.
Voor een orchestrator is dat niet "handig." Dat is de basis van betrouwbaarheid.
Mijn dispatch-systeem stuurt instructies naar agents met specifieke scope: welke bestanden, welke functionaliteit, welke constraints. Als een model die scope interpreteert als suggestie in plaats van grens, vallen je governance-lagen uit elkaar.
Met striktere instructieopvolging worden guardrails betrouwbaarder:
- Scope beperking: "werk alleen in deze directory" wordt nu echt gehonoreerd
- Format compliance: output in het gevraagde format, zonder creatieve toevoegingen
- Constraint respect: als je zegt "maximaal 500 tokens" of "gebruik alleen deze tools", dan houdt het model zich daaraan
Dit is de shift waar ik al langer over schrijf: van prompt engineering naar context engineering. Het model hoeft niet meer overtuigd te worden om instructies te volgen. Het doet het gewoon.
De coding-verbeteringen in context
De ruwe cijfers:
| Benchmark | Opus 4.6 | Opus 4.7 | Verschil |
|---|---|---|---|
| SWE-bench Pro | 53,4% | 64,3% | +20% |
| SWE-bench Verified | n.v.t. | 87,6% | n.v.t. |
| CursorBench | 58% | 70% | +21% |
| Rakuten productietaken | 1x | 3x | +200% |
Indrukwekkend. Maar wat betekent het in de praktijk?
Minder babysitting bij complexe taken. Opus 4.7 werkt coherent over langere periodes zonder dat je halverwege moet bijsturen. Het model verifieert z'n eigen output voordat het terugrapporteert. Minder "het ziet er goed uit maar de tests falen."
Betere foutafhandeling. Het model herstelt beter van tool-fouten. Als een API-call mislukt, probeert het een alternatieve aanpak in plaats van te stoppen. Voor een orchestrator die 's nachts draait zonder supervisie is dat het verschil tussen een succesvolle run en een lege inbox de volgende ochtend.
Hogere first-pass yield. In SPC-termen: meer taken correct afgerond in de eerste poging. Minder rework, minder correctierondes. Dat bespaart niet alleen tokens, maar ook de tijd die je kwijt bent aan het reviewen van halve oplossingen.
De echte shift
Gartner rapporteert een stijging van 1.445% in vragen over multi-agent systemen tussen Q1 2024 en Q2 2025. Gartner voorspelt dat 40% van enterprise-applicaties eind 2026 task-specifieke agents bevat.
De markt beweegt van losse AI-tools naar gecoordineerde agent teams. En daarvoor heb je een orchestrator nodig die betrouwbaar is, niet eentje die indruk maakt op benchmarks.
Opus 4.7 maakt die stap kleiner. File-based memory maakt context-overdracht simpeler. Minder subagent-spawning maakt governance haalbaar. Letterlijkere instructieopvolging maakt guardrails betrouwbaar.
Het is niet de benchmarks die het verschil maken. Het is de betrouwbaarheid.
Wil je de impact op marketing en sales zien? Lees wat Opus 4.7 concreet verandert voor je dagelijkse marketing en sales. Voor de Engelse deep dive over governance engineering als discipline: Opus 4.7 as Agent Brain.
Wat dit betekent voor jouw AI-implementatie
Je hoeft geen multi-agent systeem te bouwen om hier profijt van te hebben. Als je Claude gebruikt voor dagelijkse taken (coding, content, analyse) merk je deze verbeteringen direct:
- Start met een complex document. Upload een PDF met tabellen en grafieken. Vergelijk de analyse met wat je eerder kreeg.
- Test instructieopvolging. Geef een gedetailleerde briefing met specifieke constraints. Kijk of het model zich eraan houdt.
- Geef een langere taak. Iets dat meerdere stappen vereist. Kijk of het resultaat consistent blijft van begin tot eind.
Als je wel met agents werkt: test of je governance-regels strenger worden nageleefd. Dat is waar de echte winst zit.