Wanneer je "AI orchestration" googelt, krijg je steeds hetzelfde plaatje. Een centrale agent, de orchestrator, die taken uitzet bij subagents. De subagents werken parallel, elk in hun eigen context window. De orchestrator verzamelt de resultaten en combineert ze tot een antwoord.
Elk framework tekent het zo. Elk artikel beschrijft het zo. LangGraph, CrewAI, Anthropic's Agent SDK: allemaal hetzelfde patroon.
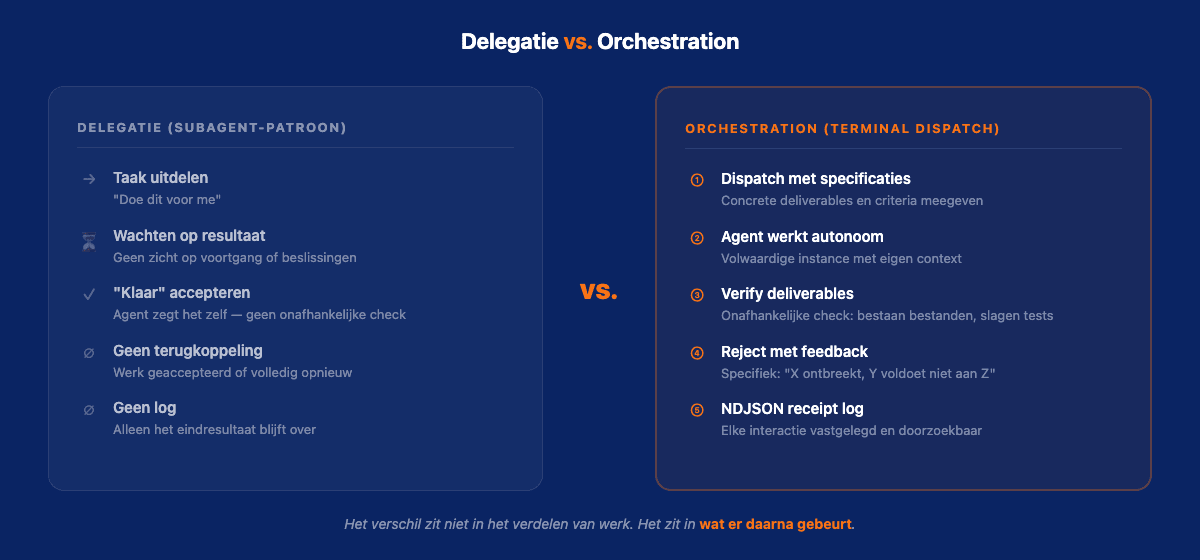
Na zes maanden dagelijks multi-agent systemen draaien in productie weet ik: dat is niet orchestration. Dat is delegatie. En het verschil is fundamenteel.
Delegatie vs. orchestration
Stel je voor dat je een projectleider bent met drie teamleden. Je geeft elk een taak en zegt: "Laat me weten als je klaar bent." Wanneer ze klaar zijn, combineer je hun werk.
Dat is delegatie. Het werkt wanneer je teamleden betrouwbaar zijn, de taken onafhankelijk zijn, en de kwaliteit voorspelbaar is.
Orchestration is iets anders. Orchestration is: je geeft elk een taak met specifieke deliverables. Wanneer iemand zegt "klaar", controleer je of de deliverables er daadwerkelijk zijn en of ze aan de eisen voldoen. Als dat niet zo is, stuur je het werk terug met specifieke feedback. Je legt elke interactie vast. En je past de taakverdeling aan op basis van wie goed presteert.
Het verschil zit niet in het verdelen van werk. Het zit in wat er gebeurt nadat het werk is afgeleverd.

Hoe de meeste frameworks het doen
Het dominante patroon in 2026 werkt als volgt:
- Orchestrator-agent ontvangt een complexe taak
- Orchestrator besluit dat de taak te groot is voor één context window
- Orchestrator spawnt subagents: child-processes met een beperkte opdracht
- Subagents werken parallel, elk in hun eigen context
- Subagents leveren resultaat terug aan de orchestrator
- Orchestrator combineert de resultaten
Het argument voor dit patroon is context window management. Anthropic's eigen engineering blog beschrijft hoe gespecialiseerde subagents gerichte taken afhandelen met eigen context windows en een samengevat resultaat terugleveren aan de hoofdagent.
Dat klopt. Maar het lost één probleem op, context overflow, en creëert er drie nieuwe: geen onafhankelijke verificatie, geen audit trail, en geen feedback loop. Ik heb hier uitgebreid over geschreven in waarom ik geen subagents gebruik.
Hoe mijn orchestrator werkt
Terminal dispatch in plaats van subagent spawning
Per-output kwaliteitscontrole
Reject-and-retry met specifieke feedback
NDJSON receipt ledger
Waarom dit ertoe doet
De Nederlandse AI-markt groeit explosief. 327% groei in multi-agent workflows in 2025 alleen al. Maar de artikelen die ik lees, op Techzine, AI.nl, gaan bijna uitsluitend over de mogelijkheden. Meer agents, meer taken, meer parallellisatie.
Niemand schrijft over controle.
Machine Learning Mastery beschrijft de trend naar "bounded autonomy architectures with clear operational limits, escalation paths, comprehensive audit trails". Camunda's rapport over agentic orchestration laat zien dat de meerderheid van organisaties een kloof ervaart tussen hun AI-visie en de productierealiteit. En Deepchecks noemt een complete audit trail als een van de kernvereisten voor productie-AI.
De patronen zijn duidelijk:
- Dispatch, niet spawn. Stuur taken naar volwaardige instances, niet naar wegwerp-subagents.
- Verifieer het resultaat, niet de belofte. Controleer deliverables onafhankelijk van wat de agent zegt.
- Reject met context. Stuur werk terug met specifieke feedback, niet met een generieke retry.
- Leg alles vast. Elke dispatch, elke verificatie, elke beslissing, in een doorzoekbaar formaat.
📖 Lees ook: Waarom ik geen subagents gebruik: drie productie-problemen met het subagent-patroon en wat er beter werkt
Dit is geen framework
Ik verkoop geen framework. Ik beschrijf principes die werken ongeacht welke tools je gebruikt. Je kunt dit bouwen met Claude Code, met Codex CLI, met Gemini, of met een combinatie. De architectuur, niet het model, bepaalt de uitkomst. De architectuur is open source.
Het punt is niet welke AI je gebruikt. Het punt is of je kunt bewijzen wat die AI heeft gedaan.
Orchestration zonder verificatie is delegatie. En delegatie zonder controle is hopen dat het goed gaat.
Na 2.400+ dispatches in productie kan ik je vertellen: hoop is geen architectuur.
Benieuwd hoe dit er in de praktijk uitziet? Ik heb het complete systeem open source beschikbaar gemaakt op GitHub. En in de Glass Box Governance serie beschrijf ik elke laag van de architectuur, van receipt ledgers tot quality gates.