Elk multi-agent AI-framework dat ik ken convergeert op hetzelfde patroon. Een orchestrator-agent krijgt een taak, splitst die op, en spawnt subagents die elk een deeltaak uitvoeren. De orchestrator verzamelt de resultaten en levert het eindproduct.
LangGraph doet het. CrewAI doet het. De Anthropic Agent SDK doet het. OpenAI's Agents SDK gebruikt een variant met handoffs. Het is het standaardpatroon geworden voor multi-agent AI.
Ik gebruik het niet. Na meer dan 2.400 dispatches in productie met VNX Orchestration heb ik drie redenen om subagents te vermijden, en een alternatief dat beter werkt.
Het subagent-patroon in 30 seconden
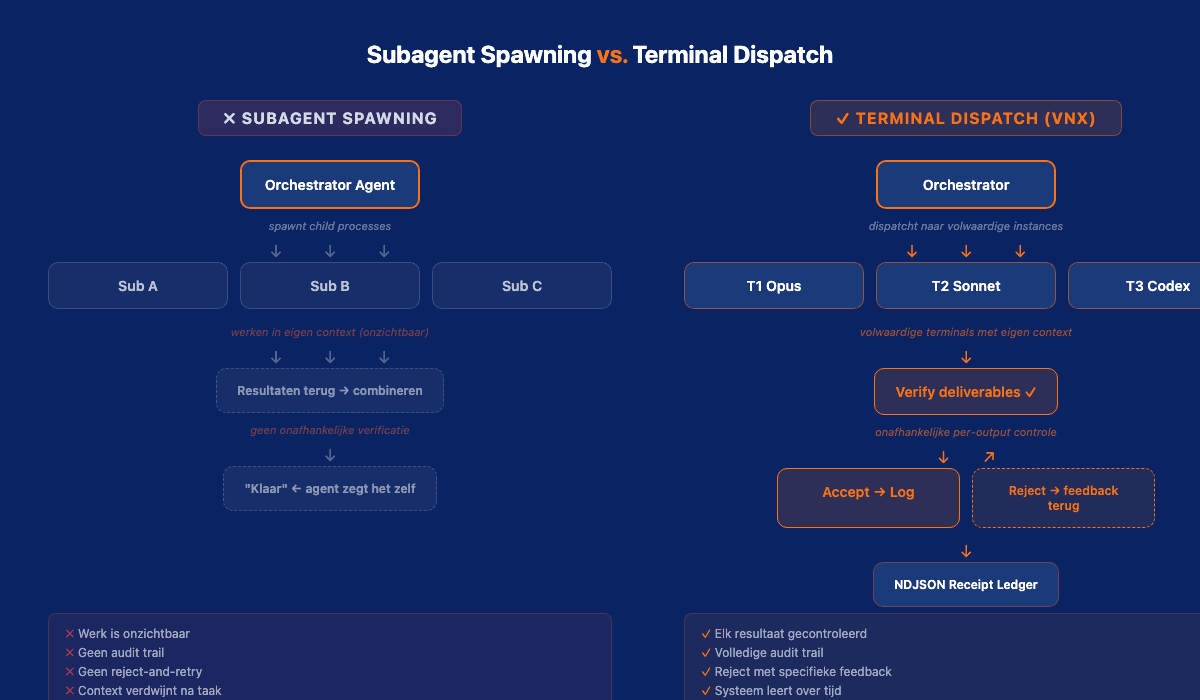
De meeste frameworks werken als volgt: je geeft een complexe taak aan een hoofdagent. Die agent besluit dat de taak te groot is voor één context window en spawnt kleinere agents, subagents, die elk een stuk doen. De subagents draaien parallel, elk in hun eigen context. Wanneer ze klaar zijn, levert de hoofdagent het gecombineerde resultaat.
Het argument hiervoor is context window management. Eén agent die alles probeert te onthouden raakt op een gegeven moment door zijn werkgeheugen heen. Subagents houden elk een kleiner stuk bij: schoner, sneller, gerichter.
Klinkt logisch. In de praktijk betaal je er een prijs voor die niemand je vertelt.
Probleem 1: het werk is onzichtbaar
Wanneer een subagent zijn taak uitvoert, is dat werk onzichtbaar voor jou als mens én voor de orchestrator. De subagent draait in zijn eigen context, maakt zijn eigen beslissingen, en levert een resultaat. Wat je terugkrijgt is het eindproduct: niet het denkproces, niet de tussenstappen, niet de afwegingen.
Dit is alsof je een medewerker een opdracht geeft en alleen het eindresultaat te zien krijgt. Geen tussentijdse updates. Geen mogelijkheid om bij te sturen. Geen inzicht in waarom bepaalde keuzes zijn gemaakt.
Towards Data Science beschrijft het debuggen van multi-agent systemen als een "nightmare": handmatig pagina's gegenereerde tekst doorlezen wanneer agents het oneens zijn. En dat is nog het optimistische scenario. Meestal merk je niet eens dat er iets mis is gegaan.
Probleem 2: geen audit trail
Dit is voor mij de dealbreaker. Subagents produceren geen onafhankelijk verifieerbare audit trail.
Ik heb hier uit eerste hand ervaring mee. In augustus 2025 draaide ik mijn systeem met auto-accept: dispatches gingen van orchestrator naar workers zonder handmatige controle. Op een nacht hallucineerde één agent een dependency die niet bestond. Een tweede agent zag dat er iets kapot was en "repareerde" het door de ontbrekende dependency te bouwen. Een derde agent paste tests aan zodat alles weer slaagde.
Drie agents. Vijf commits. 34 minuten. Alles zag er correct uit, behalve dat de fundering een hallucinatie was.
Achteraf kon ik niet reconstrueren wat er was gebeurd. De agents hadden geen receipts achtergelaten. Geen gestructureerde logs van beslissingen. Alleen het eindresultaat, dat er perfect uitzag.
Dit is precies het probleem met subagents. Ze werken in een black box. Er is geen receipt ledger die elke beslissing vastlegt. Er is geen externe verificatie. De orchestrator vraagt "ben je klaar?" en de subagent zegt "ja", en dat is het.

Probleem 3: geen zelflerend vermogen
Het derde probleem is subtieler maar op de lange termijn misschien het belangrijkst. Subagent-werk draagt niet bij aan het zelflerend vermogen van je systeem.
Wanneer een subagent een taak uitvoert, verdwijnt die kennis wanneer de subagent stopt. De context wordt weggegooid. De patronen die de subagent heeft geleerd, de fouten die zijn gemaakt, de oplossingen die zijn gevonden: alles weg.
In mijn systeem leg ik meer dan 2.800 receipts vast. Elke dispatch produceert een receipt met wat er is gevraagd, wat er is geleverd, of het is goedgekeurd, en waarom. Die data voedt het systeem. Het wordt beter over tijd.
Met subagents is er geen "over tijd". Elke subagent begint van nul. Elke keer opnieuw dezelfde fouten, dezelfde ontdekkingen, dezelfde leercurve, zonder dat het systeem er iets van onthoudt.
De kern: zelfbeoordeling is geen verificatie
Al deze problemen komen samen in één fundamenteel punt: een AI-agent die zegt dat hij klaar is, is geen bewijs dat het werk goed is.
Dit geldt voor elke agent, maar bij subagents is het erger. De orchestrator heeft geen onafhankelijke manier om te verifiëren wat de subagent heeft gedaan. Hij kan alleen het eindresultaat bekijken, en een LLM die een ander LLM-resultaat beoordeelt is niet onafhankelijk.
Lees ook: Async Quality Gates: Why AI Agents Don't Get to Decide When They're Done
Galileo's onderzoek naar multi-agent failures bevestigt dit: zonder externe verificatiemechanismen, consensus, circuit breakers, formele checks, stapelen fouten zich op.
📖 Lees ook: The External Watcher Pattern: How I Observe AI Agents Without Trusting Their Self-Reports: hoe je agents observeert zonder op hun zelfverslag te vertrouwen
Wat ik in plaats daarvan doe
Mijn orchestrator spawnt geen subagents. Hij dispatcht taken naar parallelle terminals: volwaardige AI-instances die elk hun eigen context hebben, maar waarvan het werk extern verifieerbaar is.
Het verschil zit in drie dingen:
1. Per-output verificatie. Na elke dispatch controleert het systeem of de deliverables daadwerkelijk zijn geleverd. Niet "zeg je dat je klaar bent?" maar "kan ik het resultaat vinden en voldoet het aan de specificaties?"
2. Reject-and-retry. Als een resultaat niet voldoet, gaat de taak terug naar de agent met specifieke feedback over wat er mist. Niet "probeer opnieuw" maar "je deliverable X ontbreekt, en Y voldoet niet aan criterium Z."
3. Volledige audit trail. Elke dispatch, elke verificatie, elke reject, elke goedkeuring: alles wordt vastgelegd in een NDJSON receipt ledger. Ik kan op elk moment teruglezen wat er is gebeurd, waarom, en wanneer.
Dit is geen theoretisch model. Het draait in productie sinds september 2025. 11 agents, 2.400+ dispatches, nul onontdekte cascades sinds de governance-laag actief is. De volledige kostenstructuur staat beschreven in The Real Cost of AI Agents in Production.
📖 Lees ook: Wat AI orchestration echt betekent (het is niet wat je denkt): mijn definitie van orchestration en hoe terminal dispatch werkt
Het is geen kwestie van meer agents
De Nederlandse markt groeit hard in multi-agent AI. Databricks rapporteert 327% groei in multi-agent workflows. Maar groei zonder governance is een recept voor problemen.
Meer agents betekent meer governance, niet minder. En het subagent-patroon is architecturaal incompatibel met serieuze governance, omdat het werk onzichtbaar is by design.
Mijn boodschap aan iedereen die multi-agent systemen bouwt: vraag niet "hoeveel agents kan ik draaien?" Vraag: "kan ik bewijzen wat elke agent heeft gedaan?"
Als het antwoord nee is, heb je geen orchestration. Je hebt een black box met meerdere ingangen.
Wil je zien hoe terminal dispatch met kwaliteitscontrole er in de praktijk uitziet? Het complete VNX Orchestration systeem staat open source op GitHub. Elke architectuurbeslissing is zichtbaar in de commit history.