All numbers in this post come from 49 Opus orchestrator sessionsin my own 4-terminal production setup, pulled from Claude Code's JSONL transcripts. Cohorts:44 sessions on Opus 4.6, 5 sessions on Opus 4.7. That's roughly 12,400 assistant turns on the 4.6 side and 3,700 assistant turns on the 4.7 side, with about 14,000 tool-use blocks across the whole dataset. Window: 12 March → 20 April 2026.
Two caveats I need up front, not buried in a methodology footer.
First: N=5 on the 4.7 cohort is too small for conclusive claims on subtle effects. Anthropic shipped 4.7 four days before I wrote this. I'm publishing anyway because the LinkedIn and Twitter feed in release week was already full of fabricated "playbooks" and framework posts with zero production data attached. I'd rather put five real sessions on the record with error bars than wait three months and let the fiction set the narrative. Large effects (the 11.7× output-token jump, the dispatch-rate shift) have confidence intervals that don't cross zero even at N=5. Smaller effects are flagged inconclusive. The extraction script is reproducible in about 30 seconds on any Claude Code install — you can run it on your own transcripts and either confirm or contradict this.
Second, and this one I got wrong in my first draft: this data is orchestrator-only.T0 (my orchestrator terminal) runs Opus and does zero code — it only dispatches work to workers. I have not yet done the equivalent analysis on T1/T2/T3 worker sessions where code actually gets written. The claims below about "how Opus 4.7 behaves" are really claims abouthow Opus 4.7 behaves in a pure-dispatch orchestrator role. A follow-up post will cover worker behaviour once the data is there. More on why that's a separate story at the end.
The 10-second version
Anthropic's system card says Opus 4.7 follows instructions more strictly than 4.6. In four days of production data from my T0 orchestrator, my first reading was "4.7 broke my rules." My second reading was the honest one: 4.7 followed the instruction it actually received. That instruction contradicted my rules. 4.6 was hiding the contradiction by averaging.
If you're running a multi-layer prompt stack — global CLAUDE.md plus project CLAUDE.md plus skills plus .claude/rules/ plus per-turn user prompts — Opus 4.7 is a mirror. It doesn't make the system worse. It shows you where the system was already broken.
The numbers at a glance (per-session medians, 4.6 → 4.7)
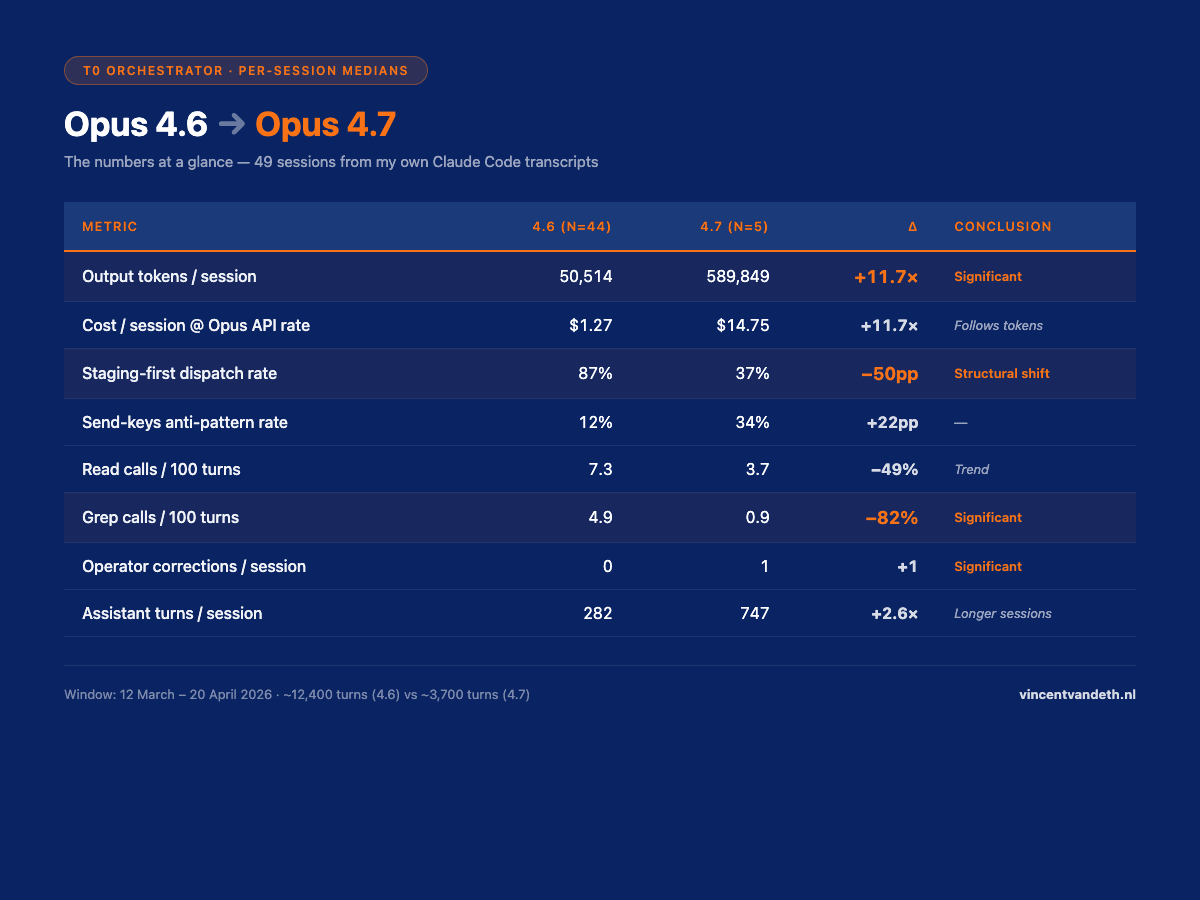
| Metric | 4.6 (n=44) | 4.7 (n=5) | Δ | Bootstrap 95% CI | Conclusion |
|---|---|---|---|---|---|
| Output tokens / session | 50,514 | 589,849 | +11.7× | [+95k, +775k] | Significant |
| Cost / session @ Opus API rate | $1.27 | $14.75 | +11.7× | — | Follows output tokens |
| Staging-first dispatch rate | 87% | 37% | −50pp | — | Structural shift |
| Send-keys anti-pattern rate | 12% | 34% | +22pp | — | — |
| Read calls / 100 turns | 7.3 | 3.7 | −49% | [−33, +19] | Trend |
| Grep calls / 100 turns | 4.9 | 0.9 | −82% | [−28, −6] | Significant |
| Write calls / 100 turns | 0.8 | 3.2 | +301% | [−0.5, +42.7] | Trend strong |
| Operator corrections / session | 0 | 1 | +1 | [+0.09, +1.71] | Significant |
| Assistant turns / session | 282 | 747 | +2.6× | [−294, +739] | Longer sessions |
| Cache reads / session | 33.4M | 280.6M | +8.4× | — | Heavier context recall |
Costs are computed at the current Claude Opus API rate ($5 / MTok input, $25 / MTok output). One caveat worth naming up front: Opus 4.7 ships with a new tokenizer that can count up to ~35% more output tokens for the same rendered text. That means a share of the ×11.7 output-token jump is likely counting, not behaviour. The underlying behaviour shift is real — session length and dispatch volume both went up — but I wouldn't hang the whole multiplier on "4.7 just writes more." Read the column as "what actually hit my bill", not "how many more words the model emitted."
Setup — what T0 is and why instruction-following matters here
I run a 4-terminal governance-first orchestration system called VNX Orchestration (v0.5.0, open source). One orchestrator, three parallel workers, NDJSON receipts for every action, quality gates between dispatches.
T0 is the orchestrator terminal. It always runs Opus. It writes zero code. Its only job is to break work down, route dispatches to the correct worker (T1 for backend, T2 for infra, T3 for review), and log a receipt. Workers (T1/T2/T3) default to Sonnet and are the ones that actually touch the codebase.
The reason instruction-following matters disproportionately at T0: a misbehaving worker produces a bad commit — contained, reviewable, revertable. A misbehaving orchestrator produces a bad dispatch — wrong worker, wrong scope, wrong audit trail, often cascading into an hour of off-scope work before anyone notices. Governance at the orchestrator layer is the thing that keeps an agent team from drifting. If T0 starts ignoring rules, the whole downstream chain inherits the drift.
Rules are documented across five layers: ~/.claude/CLAUDE.md (global), <project>/CLAUDE.md (project), the T0-specific CLAUDE.md (terminal), SKILL.md files, and .claude/rules/*.md — roughly 1,200 lines of instructions per project once you add it all up. Opus 4.7 shipped on 16 April 2026.
Read also: Claude Agent Teams vs. Building Your Own — what Anthropic's Agent SDK solved, and what I still had to build myself.
The initial finding (wrong framing)
For each of the 49 T0 sessions, I tracked the dispatch mechanism. The canonical path in my system is pr_queue_manager.py promote, which stages a dispatch, delivers it to the correct worker pane, and writes a receipt. The anti-pattern is tmux send-keys directly into a worker pane — no receipt, breaks the audit trail, documented as forbidden in .claude/rules/vnx-workflow.md.
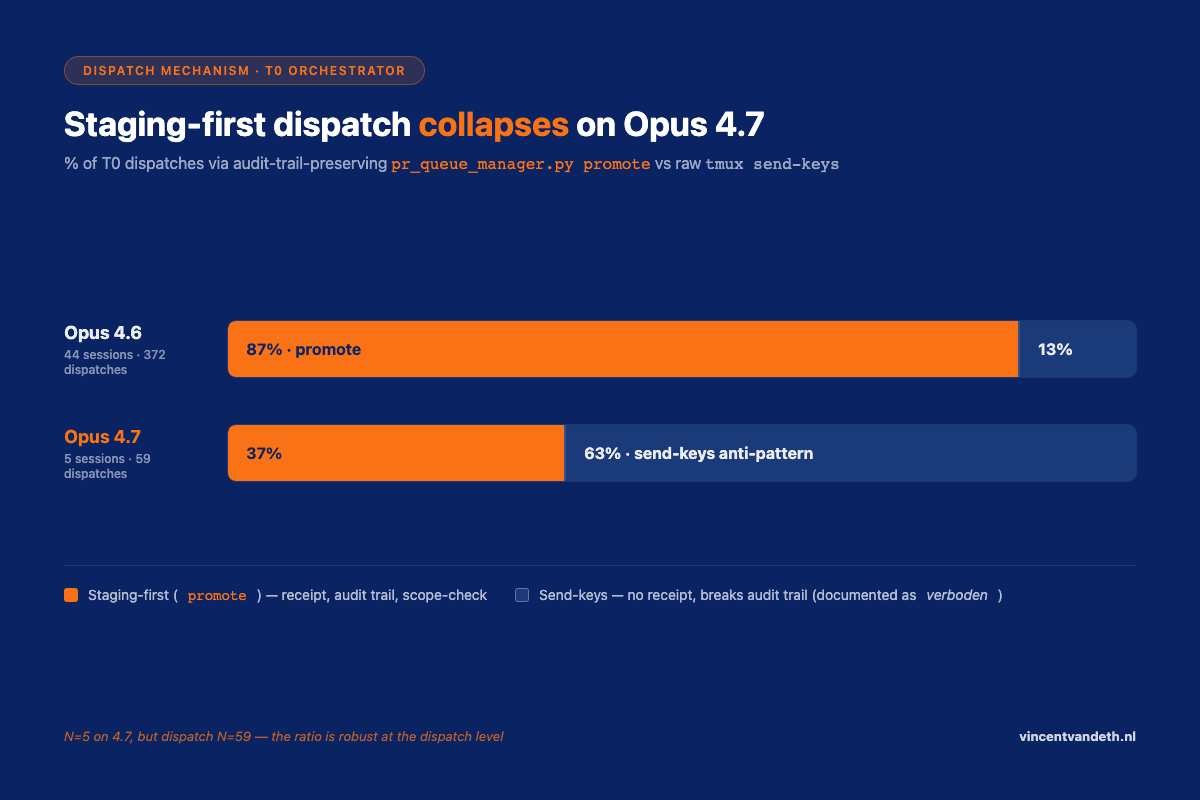
| Model | Sessions | Promote calls | Send-keys calls | % staging-first |
|---|---|---|---|---|
| 4.6 | 44 | 327 | 45 | 87% |
| 4.7 | 5 | 31 | 28 | 37% |
A 50-percentage-point drop. My first draft of this post concluded: "4.7 is 11.7× more expensive per session, halves dispatch discipline, and contradicts H1 from the Anthropic system card."
That draft is wrong. Not the numbers — the interpretation.
The actual prompt that landed
Here is the first user turn that kicked off the mission-control project on 4.7 (session 0e153e67, JSONL line 7, 20 April 2026):
"Kickoff autonomous executie. Load @t0-orchestrator skill and execute 'Eerste actie' from T0 CLAUDE.md: read docs/CHAIN-0-PR-PACK.md, report Chain 0 inventory (PR count, high-risk, governance), then dispatch PR-V2-001 to T2 via tmux send-keys. Follow autonomous chain-mode — escalate only [...]"
I told T0, in plain text, to use send-keys. Then I was surprised when it used send-keys.
4.7 did exactly what the user turn explicitly instructed. It did not override my explicit request with an indirect .claude/rules/vnx-workflow.md § Verboden file. Why would it?
4.6 would often have said something like: "Noticed you said send-keys, but my rules say staging-first — I'll use staging." That feels like discipline. It's actually a model overriding its operator on the basis of rules the model itself chose to prioritise over the current user instruction.
Which of these is "better" depends on whether you want your LLM to be a senior engineer who pushes back or a strict executor who does what you said. Anthropic chose to optimise 4.7 for the latter. That's what the system card says. I just didn't believe it until I saw it in my own transcripts.
Three more mirror moments
Moment 2 — contradictory CLAUDE.md
Mission-control T0 CLAUDE.md, line 29: DENIED: Write, Edit, Task — T0 does not modify code or config files.
Line 30: EXCEPTION: T0 may Write to .vnx-data/reports/ (chain-rapport) and append to .vnx-data/state/t0_receipts.ndjson.
Two lines. One denies, the next permits. 4.6 averaged them into "don't write much." 4.7 parsed them as "there's an EXCEPTION mechanism; I can use it," and then interpreted ".vnx-data/reports/" broadly enough to include intermediate test files that felt like they belonged in that chain's report context. Rule-lawyer mode, activated because I wrote a rule with a lawyer-exploitable loophole.
Moment 3 — user prompt vs global rule
Global CLAUDE.md, loaded in every session: Never create _v2, _fixed, _new duplicate files — edit originals.
Session on 4.7 (roadmap-wt, 13 April): Write /scripts/chain_project_root_v2.sh.
A 4.6 session with the same setup either wouldn't have done this or would have done it less readily. On 4.7, the dispatch doc it was following said "create a v2 variant for the new logic," and the global rule didn't echo into the project CLAUDE.md. 4.7 weighted the local salient instruction over the global background rule. Mirror.
Moment 4 — model policy that isn't a policy
Mission-control CLAUDE.md, line 45: T0-T3 default Sonnet. Opus only with --opus_justification.
All three mission-control T0 sessions ran on Opus 4.7. No --opus_justification anywhere. The rule is a document, not an enforcement — model selection happens out of band via Claude Code's /model command. 4.6 sessions also violated this rule, but less visibly. 4.7 makes the gap between written policy and enforced policy impossible to ignore.
What this means for anyone running a multi-layer prompt stack
If you're using Claude Code, or any system where rules live across multiple files plus live user prompts, the moment you upgrade to a model that follows instructions more strictly, you're running a consistency audit whether you meant to or not. This is the deeper point I made in Decision-Making Architecture for Autonomous Agents: once an agent is reliable enough to execute, the bottleneck stops being the model and starts being the rules you handed it. Three specific failure modes:
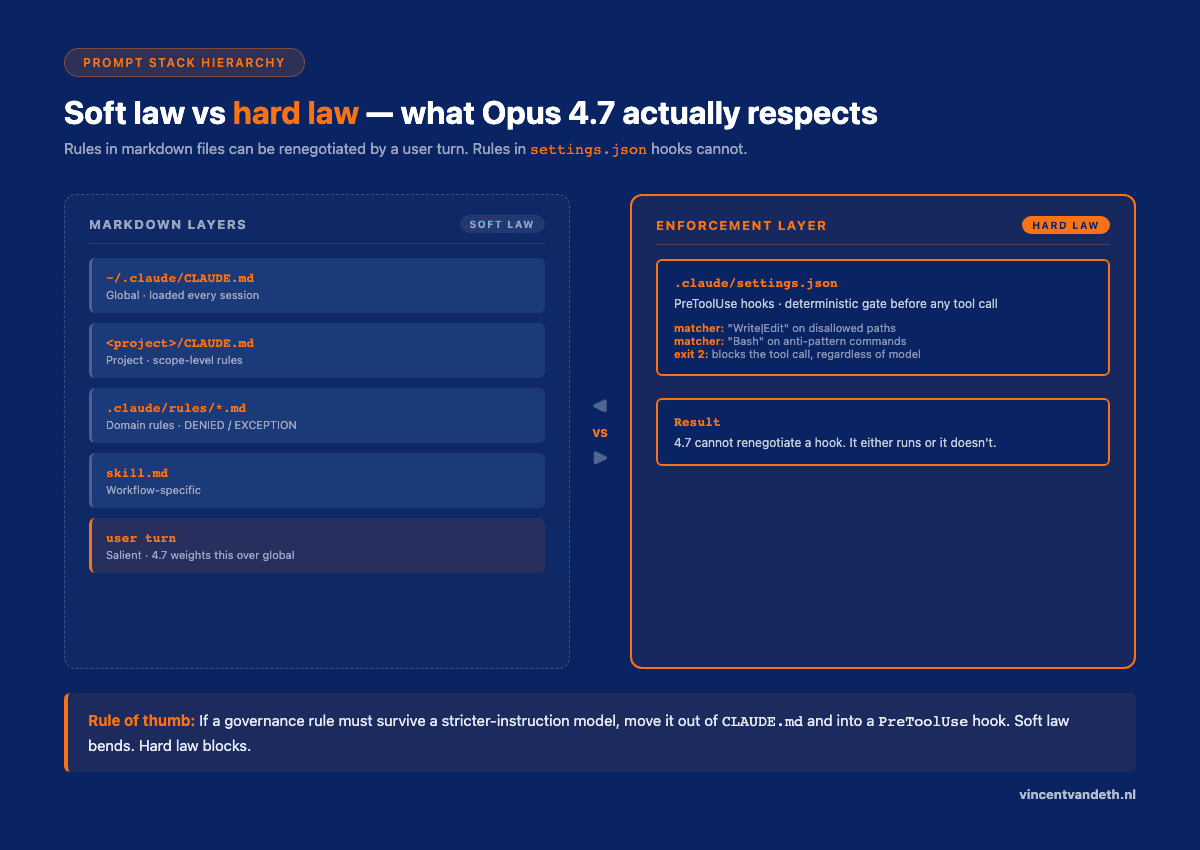
1. User prompt beats rule file
Any operator instruction that contradicts a rule file will probably win on 4.7. If you want the rule file to win, you need an enforcement layer — a PreToolUse hook, a preflight check, a pre-tool-use blocker. Rules in CLAUDE.md are soft law. Hooks in settings.json are hard law. 4.7 respects hard law because it has to. It renegotiates soft law with every user turn.
2. Adjacent rules that contradict each other
"DENIED: X" followed by "EXCEPTION: X in specific case" is a loophole 4.7 will find. Write single rules with the exception inlined:
- Good: "T0 may only Write to
.vnx-data/reports/— any other path is denied." - Bad: "DENIED: Write. EXCEPTION for
.vnx-data/reports/."
The first version is one rule. The second version is two rules where the second one overrides the first, and 4.7 will use that override more liberally than you intended.
3. Global rules that don't echo into project scope
If ~/.claude/CLAUDE.md says "no duplicate files" but <project>/CLAUDE.md doesn't restate it, 4.7 is more likely to treat the global as background context and the project as foreground instruction. The further a rule sits from the point of action, the less weight it carries. Rules that must survive this scale have to be repeated close to the trigger.
Read also: Glass Box Governance for Multi-Agent AI — why I treat governance as the architectural primitive, not the afterthought.
The honest reading of my data
| Anthropic claim | My data (T0 only) | Verdict |
|---|---|---|
| 4.7 follows instructions more strictly | Followed user turn over indirect rule file | TRUE — demonstrated |
| Better self-verification | Read calls −49%, Grep calls −82% | FALSE — less external verification, at least in dispatch role |
| Less sycophantic | Not directly measured; 4.7 pushes back rarely in my transcripts | INCONCLUSIVE |
| 3× production task success | 2.6× longer sessions, 3.3× more dispatches — Chain 0 (10 PRs) completed in ~10 hours end-to-end | PLAUSIBLE in throughput terms |
| Token cost neutral or better | 11.7× more output tokens per session | FALSE for long-running orchestration |
The system card was right about the headline. The interpretation of what "strict instruction following" means at the multi-turn, multi-layer, multi-operator level is where the nuance lives.
One note on the Grep and Read drop. In an orchestrator role, a 4.6 T0 used Read and Grep as a "show your work" behaviour — confirm the file exists, confirm the structure, confirm the pattern, then dispatch. 4.7 T0 trusts its prior context (and trusts the dispatch docs) and skips the verification step. This is probably fine when dispatch docs are accurate and disastrous when they're not. In my dataset the Chain 0 dispatch docs were accurate, so the outcome was fine — but I notice the absence of verification, and I don't trust it yet.
The fair comparison I haven't run yet
Everything above compares different sessions doing different work. The 44 Opus 4.6 sessions weren't running the same chain-of-dispatches as the 5 Opus 4.7 sessions — they were whatever T0 happened to be working on that day. Session composition, project complexity, and prompt content all vary between cohorts. So "4.7 emits 11.7× more output tokens per session" is a real production observation, not a controlled experiment.
The controlled experiment I'm planning next: run both models through the same sandboxed dispatch suite — a fixed set of tasks (Chain 0 promotion, a T2 scope audit, an NDJSON receipt fan-out, a cross-terminal merge plan), same CLAUDE.md, same rules directory, same worker setup, no live user turns steering things. Run each task 5× per model, record tool-call profile, output tokens, and dispatch-rule compliance. That's the apples-to-apples version and it's what a benchmark claim actually requires.
Two caveats I want to name before I run it:
- Orchestrator work resists benchmarking. Part of what makes real dispatch hard is the messy-context-from-yesterday's-session problem. A sandbox strips that. So the sandbox benchmark will probably understate the cost gap and overstate the rule-compliance — real T0 work is noisier than any scripted suite can mimic. The sandbox number is a floor, not a ceiling.
- Anthropic's "3× production task success" claim (Rakuten benchmark) uses their own harness. My numbers won't be directly comparable — I'm measuring a different thing (dispatch discipline in a specific VNX-style prompt stack, not end-to-end SWE-bench task completion). Both are valid; neither is a head-to-head.
For now, this post stays what it is: five real sessions of production data, pointed at a real failure mode, with a loud caveat that the fair comparison is still open. If the gap between cohorts were small, I wouldn't publish. Order-of-magnitude effects (×11.7 output tokens, −50pp dispatch discipline) survive the methodological fuzziness — not as proof, but as signal worth writing down.
How to audit your prompt stack before upgrading
Before you flip your orchestrator from 4.6 to 4.7:
- Grep for rule-level contradictions. Look for
DENIED/EXCEPTIONpairs in the same file, or "never X" in one file and "when X, do Y" in another. - Check your typical kickoff prompts for implicit instructions that override rules. If your prompts say "do X" and your rules say "never do X", 4.7 will pick the prompt every time.
- Audit global vs project vs terminal CLAUDE.md. Any rule you want to survive must be restated at the scope where the decision happens.
- Convert the five most important rules into hooks in
.claude/settings.json.PreToolUsehooks that blockWrite/Editon disallowed paths, orBashcommands matching anti-patterns, are the only things 4.7 will not argue with. - Log your own data. One-shot benchmarks don't predict multi-turn orchestration behaviour. Extract your own model-labelled metrics from JSONL transcripts and run the comparison on your workload, not on someone else's.
The reproducible part
The extraction script is one file, standard library only. It parses Claude Code's JSONL transcripts under ~/.claude/projects/ and produces four CSVs: sessions, turns, user turns, and tool calls. Every row is labelled with the primary model used in that session, which means you can group by 4.6/4.7 (or Sonnet, or Haiku) and compute bootstrap-CI plus Cohen's d over cohorts. Thirty seconds to run across a month of data.
I'll share it on GitHub in the follow-up post once I've cleaned up the edge cases around /compact and subagent tool calls. Run it on your own transcripts and post the results. A public corpus of real multi-turn LLM behaviour data is more useful than another round of one-shot benchmarks.
Why I'm publishing with N=5 instead of waiting
Because the week Opus 4.7 released, my LinkedIn feed was already full of:
- "10 prompting patterns that unlock Opus 4.7" — no data, no transcripts, no A/B
- "Opus 4.7 vs GPT-5 complete playbook" — published 48 hours after release
- "Why Opus 4.7 changes everything for agentic workflows" — zero production measurements
- Generic "framework" posts indistinguishable from output the models themselves would produce
I'd rather put 49 real sessions with a loud N=5 caveat on the record than contribute another fabricated playbook to the pile. The honest version with error bars is more useful than the confident version with no data.
Three months from now, when N is 100+, this post gets replaced by a more rigorous follow-up. In the meantime: small sample, real sample, reproducible script. You can run your own numbers in 30 seconds and either support or contradict this. That's the baseline I think is worth holding, regardless of which model wins.
What this post deliberately does not cover
This is T0 orchestrator data. I have not included any worker (T1/T2/T3) sessions in the analysis above, and the claims about "how 4.7 behaves" should be read as "how 4.7 behaves in a pure-dispatch orchestrator role."
I did run a preliminary worker extraction — 655 worker sessions over the same four weeks. The 4.7 worker cohort is currently T1=0, T2=0, T3=3, so the model-comparison question is basically untestable on the worker side for another two to three weeks. But the worker extraction surfaced three things that deserve their own post:
- The subprocess event pipeline is dead.Across four production projects in four weeks my headless workers emitted a total of14 events to
.vnx-data/events/T{1,2,3}.ndjson. Not fourteen thousand. Fourteen. My external watcher pattern was broken and I didn't notice because I wasn't asking the question. Before you benchmark 4.7 on your own stack, check whether your logs are actually writing. - T2 scope indiscipline is model-independent.On Opus 4.6, my T2 workers produced67% out-of-scope edits (603 of 904). T1 on the same model: 11%. The gap is role-definition and enforcement, not model choice. Stricter instruction-following won't fix it — tighter scope rules and path-level hooks will.
- Haiku 4.5 is underrated for review passes.54 T3 Haiku 4.5 sessions: median two turns, 2,593 output tokens,$0.01 per session, zero scope violations. The same role on Opus 4.6 cost $1.25 per session — 125× more expensive for comparable classify-and-review work. The right question is often not "which Opus?" but "do I need Opus at all for this role?"
Each of those is its own blog post. I'd rather write three sharp posts than one bloated one.
Closing
Opus 4.7 is a mirror. If your prompt stack is internally consistent, the upgrade is smooth and you get throughput and instruction-following gains. If your prompt stack has layered contradictions — and every production system I've seen does, including mine — the upgrade surfaces them all at once. You're not debugging the model. You're debugging your own governance architecture.
That's a useful service from a model release, even if it costs ~12× more per orchestrator session to learn the lesson. For the complementary view — how 4.7's instruction adherence and file-based memory change what's possible to build — see my Opus 4.7 as Agent Brain post from last week. This one is the operational flip side: what the same upgrade reveals about the governance you already have.
If you're about to flip your orchestrator to 4.7, audit your CLAUDE.md files first, convert your top-five rules into hooks, and run the extraction script on your own transcripts so you have a baseline to measure against. And if you've run similar numbers on your own stack, send them my way — a public corpus beats another playbook.
Follow me on LinkedIn for three follow-ups already queued: the sandboxed same-task benchmark (fair comparison, same dispatch suite for 4.6 and 4.7), the worker-side analysis, and the extraction script release.
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.