Twee dagen geleden lanceerde mijn SEO-tool. Een van de meest gestelde vragen sindsdien: hoe meet die tool nu eigenlijk of mijn site zichtbaar is voor ChatGPT, Perplexity en AI Overviews?
Eerlijk antwoord: niemand kan met 100% zekerheid zeggen of een AI-zoekmachine jouw content gaat citeren. De interne werking van die modellen is een black box. Maar je kunt wel proxies meten, kenmerken waarvan we weten dat ze de kans op AI-citatie verhogen. En die kun je objectief scoren.
Vandaag een kijkje onder de motorkap van de drie GEO/AEO-extractors in mijn SEO-tool. Geen verkooppraat, wel: hoe ze werken, wat ze meten, en de eerlijke beperkingen.
Wat is "AI-zichtbaarheid" precies?
Voor we de extractors bekijken: het concept zelf moet helder zijn.
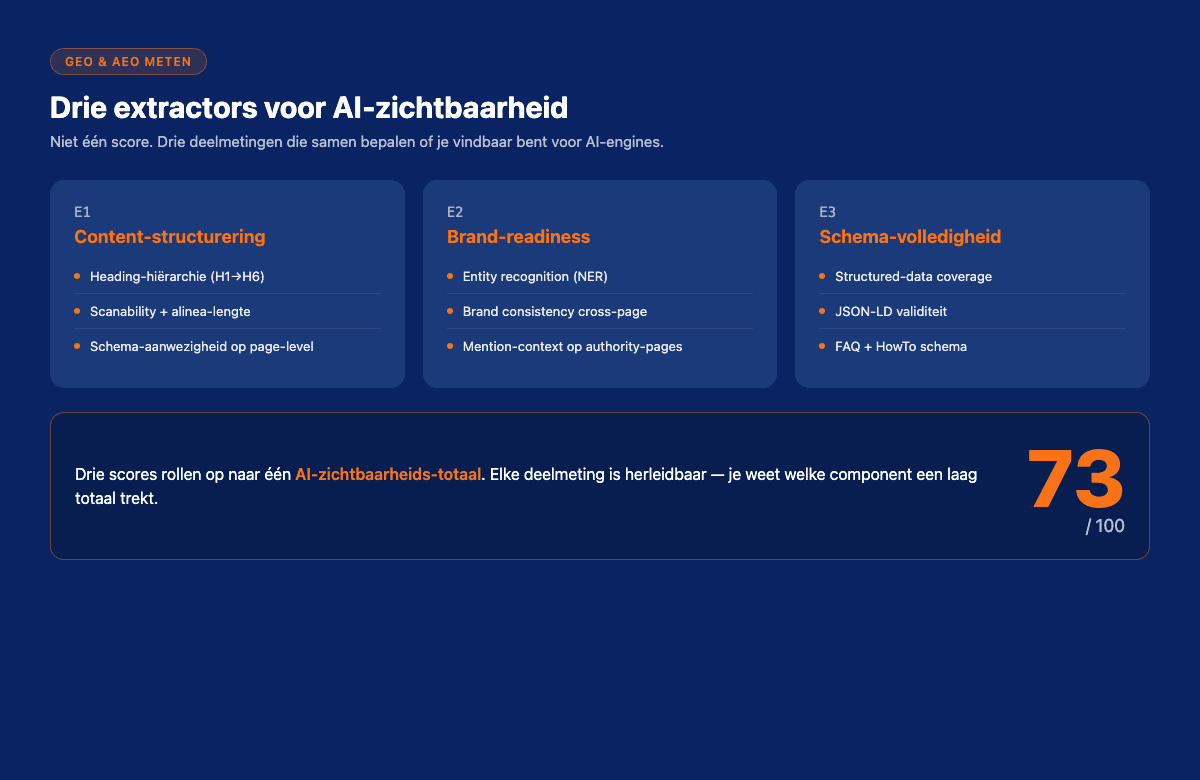
AI-zichtbaarheid splits ik op in drie meetbare lagen:
- Parseability, kan een AI-engine jouw content correct lezen en interpreteren?
- Citeerbaarheid, heeft jouw content de structuur en signalen die AI-engines voorkeur geven bij het kiezen van bronnen?
- Brand-discoverability, als jouw content geciteerd wordt, wordt jouw merk dan ook genoemd?
Drie verschillende vragen. Drie verschillende scores. In één scan.
Extractor 1, Content-structurering voor AI Overviews
Wat het meet: of de structuur van jouw content past bij hoe AI-engines content extraheren.
De feiten:AI-engines pakken geen alinea's van 200 woorden. Ze pakkenkleine, gestructureerde brokjes: een definitie, een lijst, een korte uitleg, een directe FAQ-antwoord. Jouw content moet die brokjes leveren.
Concreet wat de extractor checkt:
- Antwoord-eerst-detectie, staat in de eerste 2 zinnen na een H2 het kernantwoord op de vraag van die H2? (Zo ja: hoge citeerkans. Zo nee: AI Overview slaat over.)
- Lijststructuren, hoeveel
<ul>,<ol>, en gestructureerde tabellen heb je? Content met lijsten wordt 2-4x vaker geciteerd dan pure paragraaf-content. - Definitie-patronen, komt het patroon "Term, beschrijving" minimaal X keer voor? Dat is exact wat AI-engines zoeken voor inline-citaties.
- Alinealengte, zijn alinea's onder de 4 zinnen? Lange paragrafen worden slecht extraheerbaar.
Hoe de score eruit ziet: percentage van pagina's dat aan elk criterium voldoet, plus aanbevelingen per pagina ("voeg FAQ-schema toe op pagina X", "herstructureer alinea Y van 8 naar 3 zinnen").
Eerlijke beperking:dit zegt niets over of je contentinhoudelijk goed is. Een goed-gestructureerde slechte tekst scoort hoog. Een slecht-gestructureerde excellente tekst scoort laag. De score is een proxy voor parseerbaarheid, niet voor kwaliteit.
Extractor 2, Brand-mention readiness
Wat het meet: als jouw content geciteerd wordt door een AI-engine, is jouw merk dan zichtbaar?
De feiten: AI-engines citeren content vaak met of zonder merknaamvermelding. Als jij wordt geciteerd zonder dat je merk wordt genoemd, krijg je het verkeer niet en de naam-bekendheid niet. Pure brand-loss.
Concreet wat de extractor checkt:
- Author-byline aanwezigheid, heeft elke pagina een auteur duidelijk vermeld? (AI-engines hechten waarde aan author-attribution sinds 2025.)
- Bedrijfsnaam in eerste 100 woorden, wordt je bedrijfsnaam in de opening genoemd, niet alleen in de footer? AI-engines pakken vaak de eerste paragraaf voor citatie.
- Author en Organization JSON-LD schema, heb je
PersonenOrganizationschema's correct geïmplementeerd? Dat geeft AI-engines een gestructureerd handvat voor merknaam-extractie. - "Vincent van Deth zegt:" patronen, voorgezette quotes met author-attribution worden vaker letterlijk geciteerd. Het zijn gemakkelijke citatie-anchors.
Hoe de score eruit ziet: percentage pagina's met sterke brand-mention readiness, plus per pagina concrete fixes ("voeg author-byline toe op pagina X", "schema Person ontbreekt").
Eerlijke beperking: zelfs als alles op groen staat, kan een AI-engine besluiten je merk niet te noemen. Het is kansverhoging, geen garantie.
Extractor 3, Schema voor GEO/AEO
Wat het meet: is je gestructureerde data (JSON-LD) volledig en correct voor de schema-typen die AI-engines daadwerkelijk gebruiken?
De feiten: Schema.org is een container. Niet alle schema-types zijn even waardevol. AI-engines hebben in 2025-2026 voorkeuren gevormd: bepaalde schemas leveren consistent meer citaties op dan andere.
Concreet wat de extractor checkt:
- FAQPage schema op pagina's met FAQ-secties, bijna verplicht voor AEO in 2026
- HowTo schema op handleidingen en stappenplannen, sterk citatie-signaal
- Article schema met
dateModified,author,publishercorrect ingevuld, basisniveau-vereiste - BreadcrumbList schema, helpt AI-engines de site-structuur begrijpen voor context-aware citatie
- Schema-validiteit zelf, geen schema is beter dan kapot schema. Veel sites hebben schema dat niet valideert tegen Schema.org-spec.
Hoe de score eruit ziet: validatierapport per pagina ("FAQPage ontbreekt op 12 pagina's met FAQ-content", "Article-schema heeft author veld niet ingevuld op 8 pagina's"), plus directe JSON-LD-snippets om te kopiëren-en-plakken.
Eerlijke beperking: schema is een signaal, niet een garantie. Een pagina met perfect schema kan nog steeds slecht citeerbaar zijn als de inhoud-laag (Extractor 1) het niet ondersteunt.
📖 Lees ook: JSON-LD Schema en AI-zoekmachines: waarom je website onzichtbaar is zonder structured data: de technische kant van schema-implementatie voor AI-zichtbaarheid.
Hoe combineer je de drie scores?
Geen wiskundige formule die ik hier ga delen, concurrenten lezen ook mee. Wel het principe: de drie scores worden gewogen op basis van welke scenario je content heeft.
Een blog (informationeel) heeft Extractor 1 (structurering) zwaarder gewogen. Een productpagina (commercieel) heeft Extractor 2 (brand) zwaarder gewogen. Een handleiding heeft Extractor 3 (HowTo schema) zwaarder gewogen.
Die contextuele weging is de waarde-toevoeging die je niet krijgt bij generieke schema-validators of ranking-tools. De score weet welke vragen jouw content moet beantwoorden, en weegt daar de extractors op af.
Concrete output voor één pagina
Hier is hoe een output eruit ziet voor één blogpagina:
Page: /blog/2026-05-19-seo-tool-launch
Type detected: thought-leadership / launch-announcement
GEO/AEO Total Score: 78/100 (good, room for improvement)
├─ Extractor 1 (Content Structuring): 72/100
│ ├─ Antwoord-eerst structuur in 4 van 5 H2's
│ ├─ ️ Lijststructuren: 2 (verwacht ≥4 voor blog van 1.500 woorden)
│ └─ ️ Alinea 7 te lang (8 zinnen), splits aanbevolen
├─ Extractor 2 (Brand Mention Readiness): 92/100
│ ├─ Author byline aanwezig
│ ├─ Bedrijfsnaam in eerste 100 woorden
│ ├─ Person en Organization schema correct
│ └─ ️ Geen "Vincent van Deth zegt:" patronen, kansgemist
└─ Extractor 3 (Schema): 70/100
├─ Article schema valid
├─ FAQPage schema ontbreekt (pagina heeft FAQ-sectie)
├─ ️ BreadcrumbList ontbreekt
└─ dateModified correct
Top 3 actionable items:
1. Voeg FAQPage JSON-LD schema toe → click [Generate Schema]
2. Splits alinea 7 in twee korte alinea's
3. Voeg een lijststructuur toe rond "drie principes"Dat is het verschil tussen een rapport en een actielijst. Drie acties, deze week uitvoerbaar, met directe impact op AI-zichtbaarheid.
Eerlijke beperkingen van AI-zichtbaarheids-meting
Zoals beloofd: drie eerlijke disclaimers.
1. Geen meting van werkelijke citaties
Mijn tool meet kansverhogend potentieel, geen daadwerkelijke citaties. Of ChatGPT jouw content gaat citeren als iemand een vraag stelt, dat kun je alleen achteraf verifieren door zelf vragen te stellen aan ChatGPT en te kijken.
In de roadmap voor Q3 2026: een feature die wekelijks geautomatiseerd 10-50 vragen test in ChatGPT/Perplexity en bijhoudt of jouw merk wordt genoemd. Tot dan: doe het maandelijks handmatig op je top-10 onderwerpen.
2. AI-engines veranderen sneller dan tools
ChatGPT-versies, Google AI Overview-algoritmes, Perplexity's ranking, die veranderen letterlijk maandelijks. De extractors worden door mij continu geüpdatet, maar er is altijd een lag. Volg mijn changelog voor wat er nieuw is gemeten.
3. Concurrentie-vergelijking is moeilijker dan ranking-vergelijking
In klassieke SEO kun je je positie tegenover een concurrent meten (zoekvolume, ranking-positie). In AI-zichtbaarheid niet eenvoudig, er is geen "ranking" per se. Wat wel kan: vergelijk wie van jullie vaker geciteerd wordt in dezelfde test-vragen. Geen exact, wel indicatief.
Wat je deze week kunt doen
Voor de meeste MKB-eigenaren: vier acties.
- Zorg dat elke blog een FAQ-sectie heeft + FAQPage schema. Dit is de hoogste-impact-laagste-effort actie.
- Open je top-10 pagina's en check dat de eerste 100 woorden je merk noemen. Niet alleen footer.
- Test in ChatGPT, Perplexity, en Google's AI Overview met 5 relevante vragen voor jouw branche. Wordt jouw merk genoemd? Concurrent? Niemand?
- Voeg Author en Organization JSON-LD schema toe als ze ontbreken.
Voor een snellere, geautomatiseerde versie van precies dit: start een trial van mijn SEO-tool en de eerste scan staat in 24 uur klaar.
Veelgestelde vragen
Drie extractors, één AI-zichtbaarheidsscore
AI-zichtbaarheid meten is niet hetzelfde als SEO meten. Drie extractors leveren een proxy-score: parseability (content-structurering), citeerbaarheid (brand-readiness), en schema-volledigheid. De combinatie geeft je in 2026 een realistisch beeld van of jouw site zichtbaar is voor ChatGPT, Perplexity en Google's AI Overviews.
Geen perfect signaal, wel een werkbaar signaal. En het verschil tussen "we doen aan AI" en "we worden gevonden door AI" loopt door deze drie extractors.
Wil je weten waar jouw site staat? Start een trial, eerste scan binnen 24 uur, inclusief de drie GEO/AEO-extractors. Liever eerst de aanpak bespreken? Zie mijn werkwijze.