85.000 dollar. Dat was de machine uit mijn vorige post. De meest gelikete reactie was niet "wauw", maar: wie heeft dat geld.
Terecht. En het goede nieuws: je hebt geen 85.000 dollar nodig om je AI lokaal te draaien. Er is een hele klasse lokale AI-hardware tussen de 2.000 en 5.000 dollar. Een eigen AI-werkstation onder je bureau, vanaf de prijs van een nette laptop.
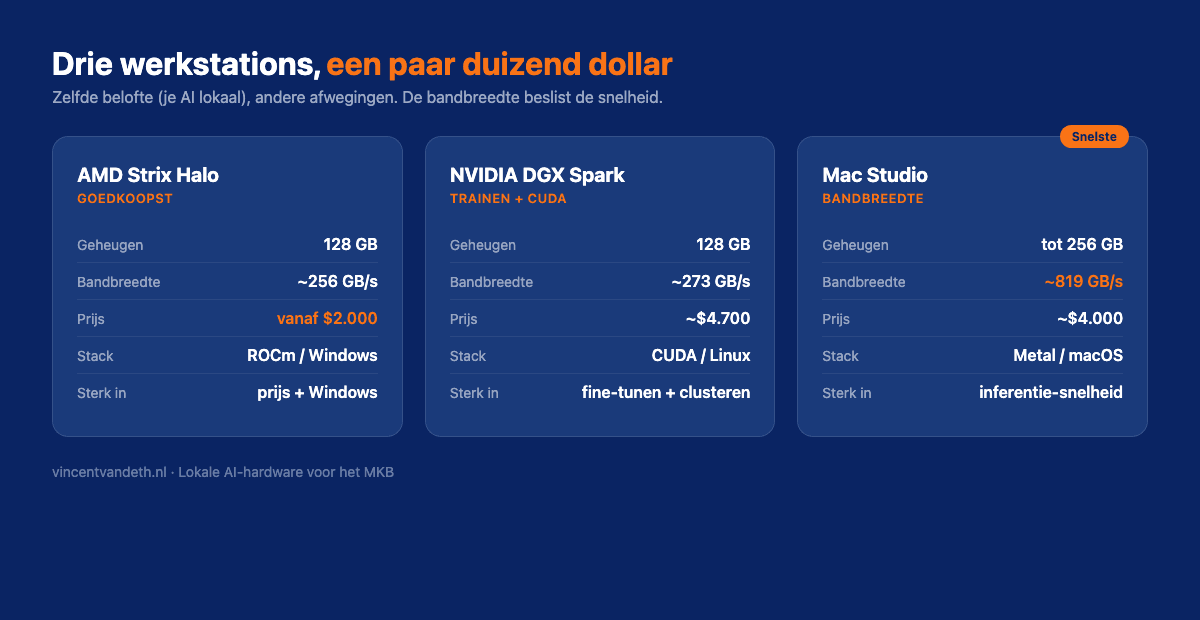
Ik vergelijk de drie die er nu toe doen: de NVIDIA DGX Spark, de AMD Strix Halo, en de Mac Studio. Zelfde belofte, andere afwegingen.
Waarom je AI lokaal zou draaien
Voordat je iets koopt, de vraag waar het echt om draait: waarom lokaal in plaats van de cloud?
Vier redenen die voor het MKB tellen:
- Je data blijft binnen. Klantgegevens, contracten en cijfers verlaten je kantoor niet. AVG wordt een architectuurkeuze in plaats van een verwerkersovereenkomst.
- Geen rekening per gebruik. Geen kosten per token, geen rate limits. Je betaalt de hardware één keer.
- Geen afhankelijkheid. Geen provider die je model kan uitzetten of de prijs kan verhogen. Dat is de Fable 5-les over vendor-onafhankelijkheid.
- Je eigen model. Je kunt een open model fine-tunen op je eigen data, zodat het jouw vakkennis kent.
De duurste variant van dit verhaal is die machine van 85.000 dollar. Dit artikel gaat over de betaalbare kant.
De twee betaalbare dozen
NVIDIA DGX Spark
De Spark is een mini-supercomputer ter grootte van een dikke boterham. 128 gigabyte werkgeheugen, de complete NVIDIA-software-stack (CUDA), voor zo'n 4.700 dollar.
Waar hij in uitblinkt:
- Trainen en fine-tunen. Dit is de sterkste kant. Je draait dezelfde stack als de grote datacenters, alleen onder je bureau.
- Uitbreiden. Je kunt twee Sparks aan elkaar koppelen (256 GB, modellen tot ~400 miljard parameters), en met vier plus een netwerkswitch tot 512 GB en modellen tot enkele honderden miljarden parameters. Niet dat het MKB dat nodig heeft, maar de groeiruimte is er.
- Meerdere modellen tegelijk. Een handvol modellen van 14 tot 32 miljard parameters draaien comfortabel naast elkaar.
AMD Strix Halo
Officieel de AMD Ryzen AI Max+ 395. Je vindt hem in mini-pc's zoals de Framework Desktop, de GMKtec EVO-X2 en de HP Z2 Mini. Ook 128 gigabyte, maar vanaf ongeveer 2.000 dollar.
Waar hij wint:
- Prijs. Bijna de helft van de Spark voor dezelfde hoeveelheid geheugen.
- Windows óf Linux. Het is een gewone x86-machine. Wil je niet op Linux werken, dan draait hij gewoon Windows.
- MoE-modellen. Op modellen die maar een deel van zichzelf activeren (zoals Qwen3 en gpt-oss) is hij vaak sneller. Op een dicht 70B-model ontlopen de Spark en de Strix Halo elkaar weinig.
De keerzijde: de software-stack (ROCm) is rauwer dan CUDA. Voor inferentie prima, voor zwaar trainwerk minder volwassen.
De eerlijke kanttekening: het draait om bandbreedte
Nu het stuk dat verkopers overslaan. Geen van deze machines is een racemonster op een groot model.
De reden is geheugenbandbreedte, niet rekenkracht. Hoe sneller het geheugen, hoe sneller een model woorden produceert. En daar zit de bottleneck:
| Werkstation | Geheugen | Bandbreedte | Vanafprijs |
|---|---|---|---|
| AMD Strix Halo | 128 GB | ~256 GB/s | vanaf ~$2.000 |
| NVIDIA DGX Spark | 128 GB | ~273 GB/s | ~$4.700 |
| Mac Studio (M3 Ultra) | tot 256 GB | ~819 GB/s | vanaf ~$4.000 |
Op een groot, dicht model van 70 miljard parameters tikken de Spark en de Strix Halo allebei maar een paar woorden per seconde weg. Traag. Wie pure snelheid op grote modellen wil, zit met de Mac Studio en zijn 819 GB/s ruim drie keer beter.
Maar dat is niet waar deze dozen voor zijn. De zoete plek is anders:
- Modellen van 14 tot 32 miljard parameters. Die draaien vlot, en ze zijn inmiddels verrassend goed voor zakelijke taken.
- Mixture-of-experts-modellen (zoals Qwen3 en gpt-oss). Die activeren maar een klein deel van zichzelf per woord en verlichten de bandbreedte-bottleneck flink. Zelfs een model van 120 miljard parameters draait zo bruikbaar.
- Fine-tunen. Hier wint de Spark met zijn CUDA-stack.
Welk model je het beste lokaal draait, en hoe snel dat echt gaat, testte ik eerder in mijn benchmark van lokale modellen voor het MKB.
Welke lokale AI-hardware past bij wie
Geen religieuze keuze, een nuchtere afweging. Dit is mijn beslismodel:
- Wil je trainen of fine-tunen, en wil je de NVIDIA-stack? De DGX Spark. Je betaalt voor CUDA en de groeiruimte.
- Wil je het goedkoopst, en draai je liever Windows? De AMD Strix Halo, bijvoorbeeld in een Framework Desktop. Vanaf ~2.000 dollar.
- Werk je al op een Mac, of wil je de snelste inferentie op grote modellen? De Mac Studio. De bandbreedte is ongeëvenaard, en je kunt hem als server aan je netwerk hangen en er via SSH op werken. Meer daarover in waarom een Mac de beste keuze is om AI lokaal te draaien.
📖 Lees ook: Wat een AI-werkstation van 85.000 dollar echt koopt: de premium-route en waarom soevereiniteit soms die prijs waard is.
Wat je er morgen mee doet
Concreet, geen theorie. Met een van deze dozen draai je lokaal:
- Een klantenservice-assistent die je eigen toon spreekt, getraind op je eigen tickets.
- Een classificatie-model dat lead, klacht, factuur en spam uit elkaar haalt.
- Offerte-concepten op basis van je laatste honderden deals.
Allemaal zonder dat er één byte je kantoor verlaat. De cloud blijft handig voor het zware werk dat topkwaliteit vraagt. De rest draai je thuis.
Veelgestelde vragen
Welke doos past bij jou?
De kern is simpel: een eigen AI onder je bureau kost geen fortuin meer. Voor een paar duizend dollar heb je een machine die je data binnenhoudt en je modellen lokaal draait.
Welke je kiest hangt af van één vraag: wil je vooral draaien, of ook trainen? Goedkoop en Windows, of de volle NVIDIA-stack, of de bandbreedte van een Mac.
Wil je hulp bij die afweging voor je eigen bedrijf, en bij wat je er daarna op zet? Bekijk hoe ik AI-systemen voor het MKB ontwerp, of volg me op LinkedIn waar ik dit soort keuzes hardop maak.