Een overheid die een topmodel zomaar uitzet. Dat was de Fable 5 ban, en het maakte iets pijnlijk duidelijk: als jouw bedrijf volledig op één externe AI-leverancier draait, beslist die leverancier mee over jouw bedrijfsvoering.
Dat zette me aan het denken. Hoe ver kom je eigenlijk zonder de cloud? Een lokaal LLM draaien op je eigen Mac betekent: je data verlaat je kantoor niet, je betaalt geen abonnement per gebruiker, en geen overheid of provider kan jouw model uitzetten.
Dus testte ik het. Niet met speelgoedprompts, maar met 18 taken die een MKB-ondernemer echt doet. 8 modellen, op mijn eigen hardware. Hieronder de cijfers, en een nuchter beslismodel: wat draai je lokaal, wat doe je beter in de cloud.
Wat ik precies heb getest
Ik draaide alle modellen op één machine: een Mac met 24 GB geheugen, met Ollama als gratis software om modellen lokaal te draaien. Daarnaast testte ik twee cloud-modellen van Claude via de API, zodat ik een eerlijke vergelijking had.
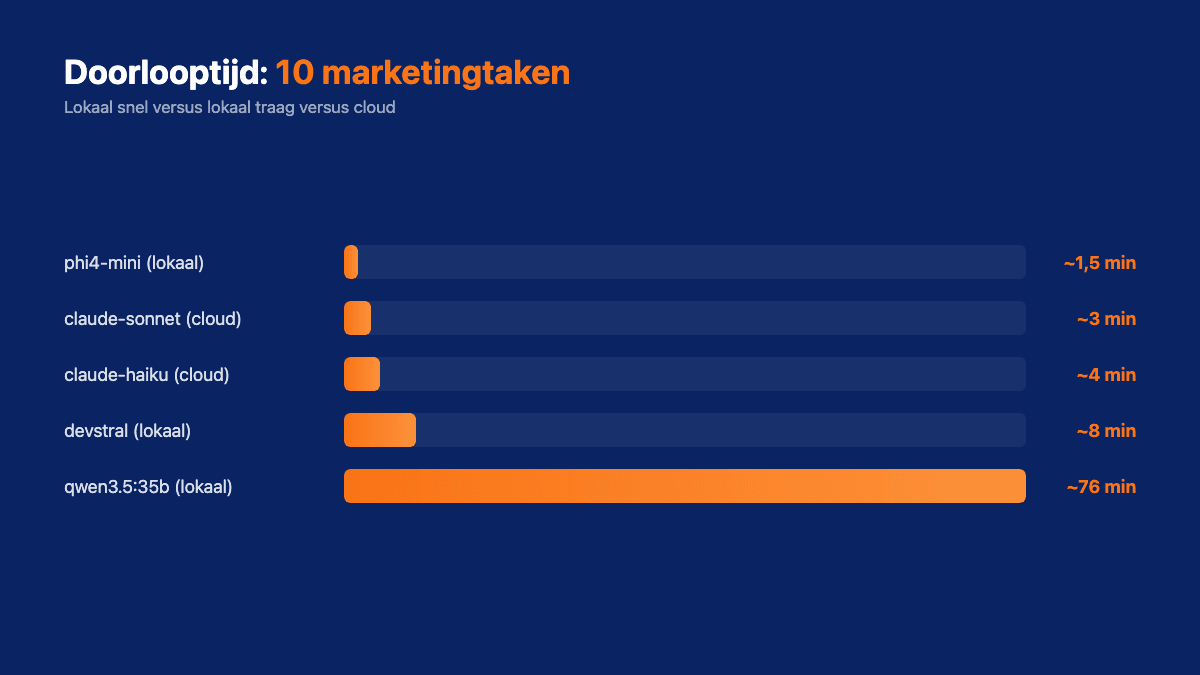
De takenlijst was bewust praktisch. 10 marketingtaken (LinkedIn-post, Google Ads, SEO-teksten, een reactie op een Google-review, een productbeschrijving, een re-engagement e-mail, FAQ's, een leadbeoordeling, een concurrentievergelijking en een Instagram-carrousel) en 8 technische taken voor wie ook code laat schrijven.
Elk model kreeg exact dezelfde opdracht. De output beoordeelde ik automatisch op drie dingen: levert het bruikbare tekst op, zitten alle gevraagde onderdelen erin, en is het echt Nederlands?
Een lokaal LLM draaien: de modellen op een rij
Niet elk model past op elke Mac. Een model moet in je werkgeheugen passen, niet alleen op je schijf. Past het niet, dan valt je machine terug op de harde schijf en wordt een taak van een halve minuut ineens tien minuten, of hij crasht.
Dit is het complete overzicht van wat ik testte:
| Model | Grootte | Snelheid | Compleet | Geheugen nodig | Geschikt voor |
|---|---|---|---|---|---|
| phi4-mini | 2,3 GB | 28-32 tok/s | 92% | 8 GB | Snelle eerste drafts, draait op vrijwel elke Mac |
| qwen2.5-coder 14B | 9,1 GB | 8,6 tok/s | 95% (code) | 16 GB | Productie-code en refactoring |
| codestral | 11,7 GB | 6,2 tok/s | 91% | 16 GB | Snelle marketingteksten |
| devstral | 14 GB | 5,9 tok/s | 98% | 16 GB | Beste prijs/kwaliteit lokaal |
| qwen3.5 27B (dense) | 17 GB | crasht | 0% | 32 GB+ | Niet bruikbaar op 24 GB |
| qwen3.5 35B (MoE) | 23 GB | 8,8 tok/s | 99-100% | 24 GB | Beste Nederlands, maar traag |
| claude-haiku (cloud) | n.v.t. | 11,8 tok/s | 100% | n.v.t. | Goedkoop cloud-alternatief |
| claude-sonnet (cloud) | n.v.t. | 15,0 tok/s | 98% | n.v.t. | Premium cloud-kwaliteit |
Eén ding springt eruit. Het grootste lokale model dat ik probeerde, een dense variant van 17 GB, crashte volledig op 24 GB geheugen. Nul bruikbare output.
Tegelijk draaide het 35B-model van 23 GB wél soepel. Dat klinkt onlogisch, tot je weet hoe ze werken: het 35B-model activeert maar een klein deel van zichzelf per woord (een zogeheten mixture-of-experts), terwijl het 17 GB-model alles tegelijk in geheugen wil houden. Voor het MKB betekent dit één ding: groter is niet automatisch beter, en het etiket op een model zegt weinig over of het op jouw Mac draait.
De snelheid: hier schrikken de meeste mensen van
Niemand vertelt je dit over lokale AI: het snelheidsverschil tussen modellen is gigantisch. Niet een beetje. We praten over 37 seconden tegenover meer dan negen minuten voor dezelfde LinkedIn-post.
Kijk naar de totale tijd voor alle tien marketingtaken samen:
| Model | Alle 10 taken | Gemiddeld per taak |
|---|---|---|
| codestral | ~9 minuten | ~56 seconden |
| devstral | ~9 minuten | ~56 seconden |
| qwen3.5 9B | ~1 uur 7 min | ~6,5 minuten |
| qwen3.5 35B | ~1 uur 23 min | ~8 minuten |
De Mistral-modellen (codestral en devstral) doen alle tien taken in negen minuten totaal. De grootste Qwen-modellen hebben daar ruim een uur voor nodig.
De verklaring is simpel: de snelle modellen schrijven kortere, compactere teksten. De trage modellen schrijven uitgebreider. Voor marketing is uitgebreider niet per se beter. Een LinkedIn-post van drie alinea's verkoopt vaak meer dan een lap tekst.
En dan de verrassing: phi4-mini, het kleinste model van 2,3 GB, doet een taak in zo'n negen seconden. Dat is sneller dan de cloud-modellen van Claude, die er 19 tot 24 seconden over doen. Een model dat op elke Mac met 8 GB past, klopt qua snelheid de cloud.
De kwaliteit: snel is niet altijd goed genoeg
Snelheid is leuk, maar levert het bruikbare teksten op? Hier zie je waar de prijs van die snelheid zit.
Op compleetheid (krijg je alle gevraagde onderdelen?) eindigde de top zo: qwen3.5 35B op 99-100%, devstral op 98%, codestral op 91% en het kleinere qwen3.5 9B op 89%. phi4-mini haalde 92%, knap voor zo'n klein model, met als zwakke plek SEO-meta-tags.
Het verschil zit in de nuance. Neem de reactie op een Google-review van een restaurant: een gast prees het eten maar klaagde over 25 minuten wachten op de drankjes.
Het 35B-model noemt specifiek die "25 minuten", erkent dat het "niet past bij onze standaard" en geeft een concrete verbeterstap. Devstral is zakelijk correct maar kort. Codestral maakte zelfs een taalfout in een andere taak: "Winter is op de deur" in plaats van "voor de deur".
Voor een snelle social post is dat verschil te verwaarlozen. Voor een gevoelige klantreactie of een belangrijke offerte telt elke nuance. Daar betaal je de extra minuten graag.
Twee instellingen die het verschil maakten
Twee technische lessen vertaal ik graag naar gewone taal, want ze bepalen of lokale AI voor jou werkt of niet.
In mijn eerste testronde scoorden de grote modellen dramatisch slecht. Toen ik de tokenlimiet verdubbelde (simpel gezegd: de maximale lengte die het model mag produceren), verdrievoudigden de scores. Ik had niet het model gemeten, maar het plafond dat ik er zelf op had gezet.
De tweede les gaat over "denkmodellen", die eerst hardop nadenken voor ze antwoorden, zoals de redeneer-stand van ChatGPT. Voor marketing helpt dat niet. Het model verspilt zijn budget aan denkstappen in plaats van aan jouw tekst. Voor marketing zet je die stand dus uit.
De moraal voor het MKB: lokale AI vraagt een paar goede instellingen. Verkeerd ingesteld lijkt een prima model waardeloos. Goed ingesteld doet het verrassend veel.
Waar lokale modellen vastlopen
Eerlijk blijven hoort erbij. Op de zwaardere technische taken haakten de lokale modellen af. Toen ik de hardste codeertaken draaide, liep het kleinere model op twee van de acht taken vast: een complexe upsert-functie en een Nederlandse bedrijfsdata-validator (KvK, BTW, IBAN) liepen domweg in een timeout.
De boodschap is niet "lokaal kan niks". De boodschap is: ken de grens. Voor tekst, social, e-mail en simpele structuurtaken is lokaal ruim voldoende. Voor zware, foutgevoelige codeertaken pak je beter een cloud-model, of laat je het door iemand bouwen.
Het eerlijke verhaal: cloud wint vaak op prijs-kwaliteit
Ik ben geen lokaal-fanaat die de cloud wegzet. Kijk naar de cijfers van Claude.
Claude Haiku via de API leverde 100% complete output, gemiddeld 24 seconden per taak, voor ongeveer 4 cent per volledige run van tien taken. Claude Sonnet: 98% compleet, 19 seconden, zo'n 5 cent per run. Dat is bizar goedkoop voor de kwaliteit.
Reken het door. Stel je doet 100 van zulke runs per maand. Dan ben je met Claude 4 tot 5 euro kwijt. Voor output die qua kwaliteit aan de top zit en die je niets aan instellen of onderhoud kost.
Lokaal is gratis in euro's, maar niet gratis in tijd en hardware. Het beste lokale model voor Nederlands deed er ruim een uur over voor diezelfde tien taken. Cloud doet dat in een paar minuten, in topkwaliteit, voor een paar cent.
Het echte voordeel van lokaal is dus niet de prijs. Het is de controle: je data blijft binnen, je bent van niemand afhankelijk, en niemand kan je model uitzetten. Precies de les van de Fable 5 ban en waarom vendor-onafhankelijkheid telt.
Wat draai je lokaal, wat doe je in de cloud?
Geen religieuze keuze, maar een nuchtere afweging per taak. Dit is het beslismodel dat ik zelf aanhoud:
Draai het lokaal als:
- je data gevoelig is en je kantoor niet mag verlaten (klantgegevens, contracten, interne cijfers)
- je veel volume draait en de cloud-rekening oploopt
- je offline of zonder afhankelijkheid wil kunnen werken
- de taak relatief simpel is: social posts, e-mails, eerste drafts, samenvattingen
Doe het in de cloud als:
- de taak echt om topkwaliteit of fijne nuance vraagt (belangrijke klantcommunicatie, gevoelige reacties)
- je het maar af en toe nodig hebt en niets wil instellen of onderhouden
- het een zware, foutgevoelige taak is zoals complexe code
- je geen Mac met genoeg geheugen hebt
In de praktijk gebruik ik een mix. phi4-mini voor snelle drafts. devstral als werkpaard voor dagelijkse Nederlandse teksten. En de cloud erbij wanneer het er echt op aankomt. Datzelfde principe (de juiste tool per taak, met de mens die de eindbeslissing houdt) ligt ten grondslag aan hoe ik mijn governance opzet voor AI-systemen die door elkaar heen werken.
Veelgestelde vragen
Beginnen kost vijf minuten
Wil je het zelf proberen? Je hebt geen account, geen creditcard en geen abonnement nodig.
- Download Ollama op ollama.com (gratis, één knop)
- Open de Terminal
- Typ
ollama pull devstralen wacht tot de download klaar is - Typ
ollama run devstral - Plak je opdracht en je krijgt je tekst
Begin met één model. devstral op een Mac met 16 GB geeft je 10 van de 10 marketingtaken compleet, in minder dan een minuut per taak, zonder dat er ook maar één byte je computer verlaat.
De Fable 5 ban liet zien hoe kwetsbaar je bent als je volledig op één externe partij leunt. Een lokaal LLM draaien lost dat niet in één klap op, maar het geeft je een keuze. En een keuze hebben is precies wat je als ondernemer wil.
Wil je hulp bij die afweging voor je eigen bedrijf? Bekijk hoe ik AI-systemen voor het MKB ontwerp.