Most writing about agentic AI has an enterprise shape. Teams of agents serving teams of humans. Multi-tenant, distributed, with role-based access and SSO. The architectural questions are about how dozens of agents coordinate, how thousands of users get served, how a Fortune 500 governs.
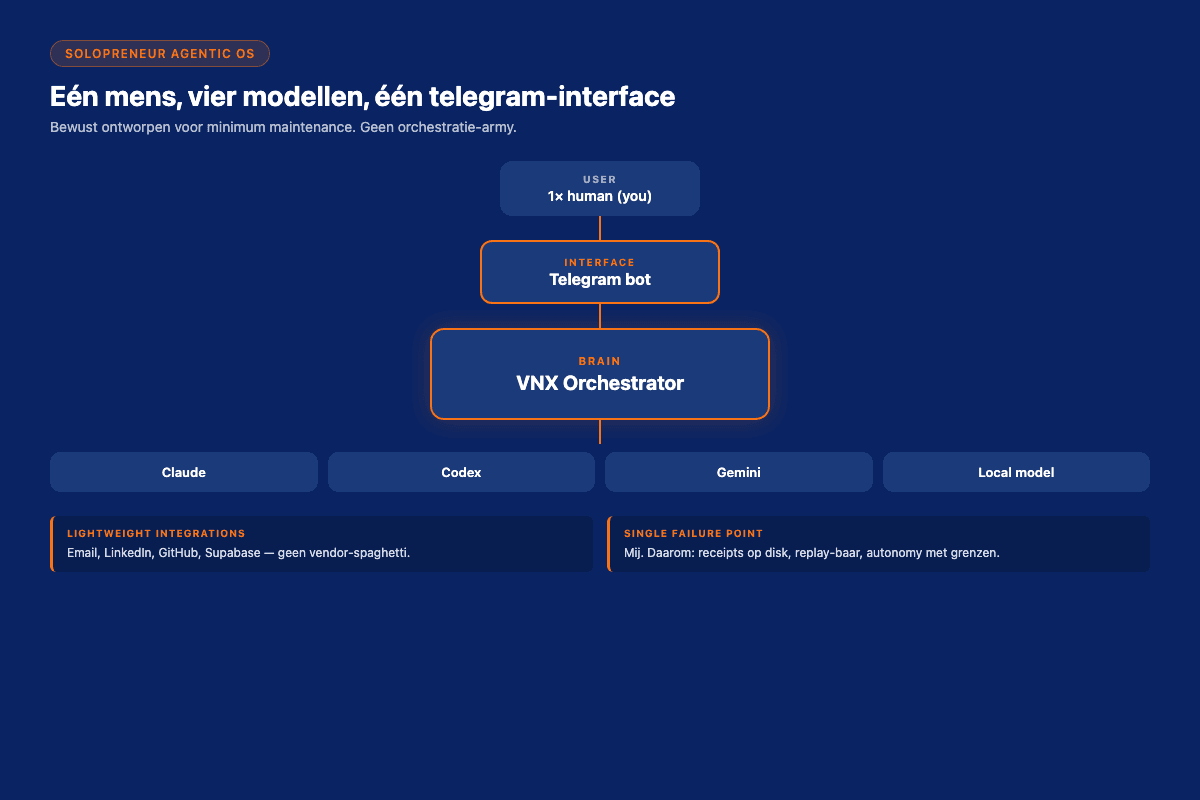
The single-operator case is different. There is one human. There are 4-11 AI agents. There is no team to coordinate around. The questions are smaller, but oddly underrepresented: how does one person design an autonomous orchestration setup that they actually trust, and that compounds in value over months?
This is what I learned building one for myself across eight months. Not a how-to. A design doc, the trade-offs I made, the patterns that survived, and the mistakes that taught me something.
The premise: one operator, multiple agents, full lifecycle
The constraints I started with:
- One operator, me. No team. No second person who knows the system.
- Multiple agents, Claude (reference), Codex (peer reviewer), Gemini (architecture), Ollama (experimental). Plus 11 functional agent-roles (blog writer, lead scorer, research-agent, etc.) running on top of those models.
- Full lifecycle, content production, lead management, code review, blog publishing, customer outreach, consulting work.
- No specialist team to delegate ops to. Everything has to be operable by me alone, including failure modes.
Within those constraints, I evolved a design over eight months. It is recognizably different from any enterprise agentic stack I have seen documented.
📖 Read also: Glass-Box Governance: receipts as the database: why append-only NDJSON beats SQL for single-operator AI audit trails
Design decision 1, Chat as the primary interface
In an enterprise agentic setup the interface is usually a web dashboard. Multiple users, role-based views, lots of state. Visual UI makes sense.
For a single operator, web UI is overhead. Every screen you build is a screen you maintain. Every chart you wire up is one more thing that breaks during a deploy. And the workflow of "open browser, navigate to dashboard, find the action button, click" is slow compared to "type a command in a chat I have already open."
Chat (in my case Telegram) became the primary interface for 90% of dispatches. Web dashboard exists but is reserved for the 10% that genuinely needs visual review (image curation, large-batch operations, deep diff analysis).
Trade-off: chat is text-only. Some workflows do not fit text well (visual review, multi-window context, complex form input). For those: dashboard. For everything else: chat wins on speed-of-thought.
This is the design choice that surprised me most. I started building a Next.js dashboard in March 2026 and found myself never opening it. The chat-first decision was an emergent realization, not a planned architecture.
Design decision 2, Receipts as the canonical state
In an enterprise system, state lives in a database. Multiple writers, transactions, ORM, schema migrations. There are good reasons.
For a single operator, the database is overhead. The actual question I want to answer is "what did agent T2 commit yesterday?", and that question is more naturally answered by an append-only NDJSON receipt ledger than by a SQL query.
I went with three append-only NDJSON streams: t0_receipts.ndjson, governance_audit.ndjson, dispatch_register.ndjson. Crash-resilient, queryable with jq + grep, no database to maintain. I wrote about the architecture in detail in the previous EN deep dive.
For multi-user systems this would not fit. The lack of transactional consistency, the concurrent-writer constraints, all real limitations at team scale. For one operator on one machine: clear win.
Design decision 3, Asymmetric autonomy
Enterprise agentic thinking often assumes uniform autonomy: agents have capabilities, governance constrains them. The single-operator case can do something subtler, different agents with different autonomy levels, calibrated to track record.
In my system:
- Worker agents (T1, T2, T3), autonomous within file-scope manifest. Can run for minutes without oversight.
- Orchestrator (T0), autonomous in dispatch routing, but cannot write files (Claude Code hooks enforce read-only).
- Quality gates, autonomous in pass/fail decision. Cannot be reasoned around, they are file-locked.
- Skills, autonomous in their domain. Skill-level instructions versioned and reviewable.
Each layer has its own contract. The orchestrator cannot do what a worker does. The worker cannot do what a gate does. Asymmetric autonomy lets you give heavy autonomy to layers you trust deeply, and tight constraints to layers where the blast radius is bigger.
In an enterprise system this would emerge from RBAC. In a single-operator system it emerges from explicit architectural separation. Same effect, different mechanism.
Design decision 4, Two-path human approval
There are exactly two ways something gets executed in my system:
Path A, staging→promote. I write a dispatch into dispatches/staging/<id>.md. I review. I run vnx promote to move it to dispatches/pending/. The system picks it up.
Path B, popup confirmation. For ad-hoc dispatches that the orchestrator generates (e.g., autonomous research loops), a popup confirmation watcher triggers before execution. I tap "approve" or "reject."
Both paths are governed by file-locks, not LLM-reasoning. The orchestrator cannot route around them. Even when I went full autonomous on March 17, 2026, the two-path approval architecture stayed. "Autonomous" means "less manual intervention for in-policy work." It does not mean "no oversight."
For an enterprise system this would be policy-as-code. For a single operator: file-locked path discipline. Same outcome.
📖 Read also: Context rotation at scale: how VNX keeps AI agents honest: the architectural feature behind 10,000+ dispatches without context drift
Design decision 5, Context rotation as architecture, not feature
The 65% context rotation with auto-handoff is the most-cited feature of my system. It also is the most architecturally consequential.
The interesting thing is why it had to be architectural rather than a feature. As one operator, I cannot babysit context windows for four parallel agents. By the time I notice a degraded session, hours of work have happened in suboptimal context. Manual /clear is not a real solution; it loses state.
The fix had to be embedded in the dispatch lifecycle: detect context fill, write structured handover, clear, re-inject continuation prompt. As a three-hook pipeline, it works without my attention.
In an enterprise system, you would have an ops team monitoring this. In a single-operator system: it has to be the architecture itself.
Design decision 6, Failure modes have to be discoverable in seconds
When the system fails, and it does, I have seconds to triage before context-switch costs become real. I cannot read 200 lines of logs to figure out what broke.
So failure modes have to be loud and structured:
- Telegram alert for any dispatch that exits non-clean
- Live tail of
t0_receipts.ndjsonrunning in a tmux pane during work hours - Three NDJSON streams that I can grep instantly: receipts, audit log, register
- One-line jq queries memorized for common questions ("what failed in the last hour?")
Compare to an enterprise setup with Datadog, PagerDuty, an on-call rotation. None of that fits a single operator's budget or attention span. The fix is structuring the data so that grep + jq are the dashboard.

What enterprise agentic thinking does NOT apply
Three patterns I bounced off and rejected.
Multi-tenant agent fleets. Enterprise thinking optimizes for many users sharing many agents. As one operator, I optimize for me being able to understand the entire system in my head. Multi-tenant complexity buys nothing here.
Heavyweight observability stacks. APM tools, distributed tracing, OpenTelemetry, all valuable at team scale. For one operator, structured NDJSON + grep beats them on speed-of-debug.
Permissioning systems. RBAC, SCIM, SSO, none of which I need. Asymmetric autonomy by architecture (worker can't do what gate does) is the simpler version.
This is not anti-enterprise. It is not-enterprise. The single-operator design space is its own thing.
What I would do differently if starting again
Three things, eight months in.
One: Start with the receipt ledger before the dispatcher. I started with tmux send-keys and added receipts a day later. Building the ledger first would have saved me a week of debugging chat scrollback.
Two: Build context rotation in Phase 1, not Phase 4. I shipped the 65%-rotation in February 2026, six months into the project. Every session before then was suboptimal. The fix is not hard once you have hooks; the absence is expensive.
Three: Pick chat as primary interface earlier. The three months I spent on a Next.js dashboard taught me something, but most of what it taught me was that I did not need it.
What this enables (eight months in)
Concrete capabilities I have today that I did not have eight months ago:
- 2,800+ structured receipts queryable across the SEO tool and VNX repos combined
- Cross-provider review at every merge gate (Codex + Gemini + CI green)
- Auto-handover at 65% context with skill recovery on the new side
- Self-healing worker pool with unified supervisor, outages recover in seconds, not minutes
- Telegram-based command center for 90% of daily operations
- Crash-resilient state,
rmany derived JSON file and rebuild from receipts in one command
That stack runs in my home office, on one operator's box, with zero cloud dependencies for the orchestration layer. It is the kind of system enterprise procurement assumes is expensive, and at single-operator scale costs about €85/month in infrastructure plus the cost of my attention.
What this does NOT enable
Honest section.
Not multi-machine HA. One operator, one box. Distributed-multi-machine is on the roadmap but not built.
Not multi-user. No SSO, no RBAC, no role separation. If someone else needs access, they need a separate setup.
Not zero-trust security. I rely on OS-level process isolation and file-locks. For multi-user environments, real auth would be needed.
Not infinite scale. The current design is tested at 4 terminals, ~2,800 receipts, eight months of state. 10+ terminals or millions of receipts would require architectural revision.
These are real limits. They do not bother me because I am one operator. They would bother a team or an enterprise.
The bigger question
The reason I am writing this is not "look how clever my setup is." It is that I think a lot of solopreneurs and small-team builders are looking at enterprise agentic-AI thinking and feeling like they have to wait until the patterns simplify.
They do not. The single-operator design space already exists. It is small, it is unfashionable, and it gets less written about than enterprise patterns. But it is real, and it compounds across months in ways that are genuinely useful.
If you are building for yourself or your three-person team, do not copy enterprise patterns. They are over-engineered for your scale and under-engineered for your actual constraint, which is your own attention.
Build for one operator. Optimize for explicit architecture over policy-as-code. Pick chat over dashboard until proven otherwise. Make failure modes loud. Treat the receipt ledger as primary.
That is the agentic OS for one person.
Discussing this with peer architects? Connect on LinkedIn, I am always interested in how others are solving the single-operator design problem. Or look at the VNX repo for the open-source reference implementation. If you want this kind of architecture for your own team, see my AI architecture work.
Sources & references
- VNX Orchestration repo
- VNX evolution post, 8 months of building
- Glass-Box Governance, receipts as database
- Three NDJSON Streams architecture
- Context Rotation at 65%, the architectural feature that mattered most
- Agentic OS: de centrale bediening voor je bedrijf, Dutch companion piece
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.