Toen ik in 2024 over Claude Code sprak met ondernemers, ging het altijd over "prompt engineering". De juiste woorden, de juiste structuur, de magische instructie die output verbeterde.
In 2026 is dat verhaal voorbij. De grootste hefboom voor AI-output is niet langer de prompt, het is de context. Wat de AI al weet voordat je je prompt geeft. Welke files in zijn werkgeheugen zitten. Welke memory hij heeft geladen. Welke tools beschikbaar zijn. Welke ruis erin zit die hem afleidt.
Dat heet context engineering, een term die ik eerder dit jaar al introduceerde. Vandaag een dieper-praktische post: concrete patronen om je AI-context schoon, gefocust en hoog-signaal te houden.
Voor AI peers en hobbyisten die voorbij hun eerste 6 maanden Claude Code zijn, dit is waar de echte productiviteitswinst zit.
Het probleem: te veel context wordt ruis
Claude Code heeft (mei 2026) een context-window van enkele honderdduizenden tokens. Dat klinkt als veel. Het is genoeg voor 400-500 pagina's tekst.
Maar wat blijkt in de praktijk: zodra een sessie boven de 65% van zijn context-capaciteit komt, verslechtert de output meetbaar. In mijn eigen VNX-systeem: kwaliteitsscores onder 65% gemiddeld 0.86. Boven 65%: 0.78. Met grotere variatie.
Het probleem is niet "te weinig context". Het probleem is te veel context met te veel ruis.
Een AI met 200 pagina's irrelevant materiaal in zijn context werkt slechter dan een AI met 50 pagina's geconcentreerd materiaal. Dat is het hele inzicht achter context engineering.
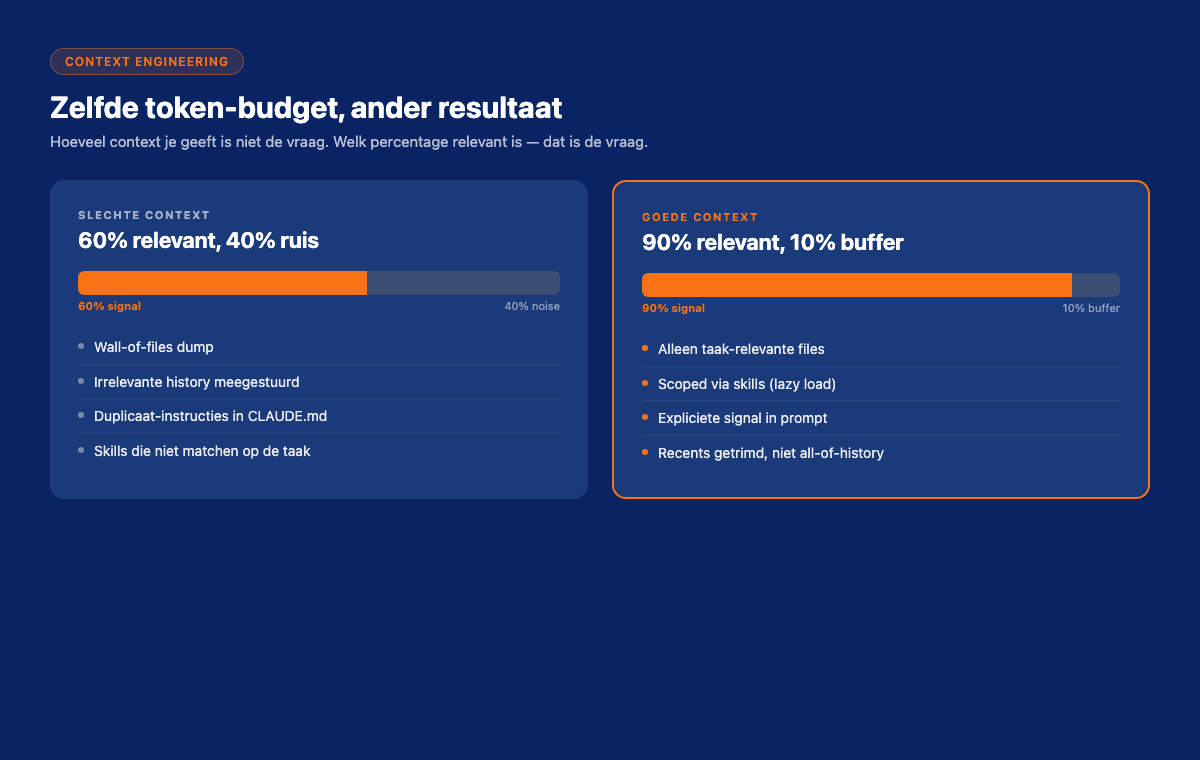
Patroon 1, Selectief laden, niet alles laden
De grootste fout van beginners (en eerlijk: ook van mij in 2024): alle relevante files openen in één sessie, voor het geval Claude er iets van nodig heeft.
Dat verspilt context-budget op materiaal dat 90% niet relevant is voor de huidige taak.
Beter patroon:geef Claude de tools om fileson-demand te lezen, en vertrouw erop dat hij ze opent als ze nodig zijn.
Concreet: in plaats van bij sessie-start 12 files te openen, vertel je Claude bij start: "we werken aan feature X. De relevante files staan in src/features/x/. Lees ze als je ze nodig hebt."
Claude leest dan precies wat hij gebruikt, en de rest blijft buiten zijn context. Resultaat: 50-70% reductie in geladen context, hetzelfde takenresultaat.
Patroon 2, Memory tier, niet memory dump
In mijn post over de drie configuratielagen die Claude Code een geheugen geven schreef ik over memory directories. Wat ik daar niet uitlegde: niet alle memory hoort bij elke sessie geladen.
Slecht patroon: SessionStart-hook laadt alle 8 memory-bestanden bij iedere sessie. Resulteert in 5K-15K tokens gevuld met info die voor 90% niet bij deze taak past.
Beter patroon: memory-tier-systeem.
.claude/memory/
├── always/ ← geladen bij iedere sessie
│ └── MEMORY.md (50 regels) ← centrale index, project-status
├── on-demand/ ← geladen op aanvraag
│ ├── decisions.md ← architectuur-beslissingen (lang)
│ ├── lessons_learned.md ← lessons learned
│ └── preferences.md ← persoonlijke voorkeuren
└── per-task/ ← per taak afzonderlijk
└── [task-folders]/De SessionStart-hook laadt alleen always/. De rest blijft beschikbaar als file maar niet geladen. Wanneer Claude denkt dat hij decisions.md nodig heeft, leest hij het op dat moment.
In mijn ervaring: 80% van sessies heeft alleen always/MEMORY.md nodig. De andere 20% pakt selectief de relevante files. Geen memory-bloat meer.
Patroon 3, Skills laten alleen relevante context inladen
Skills (zoals Claude Code skills) hebben een eigen mechanisme om context schoon te houden: ze worden alleen geactiveerd bij specifieke triggers.
Mijn 38 skills laden gemiddeld 50-200 regels context elk, alleen als de skill wordt aangeroepen. In plaats van 38 × 200 = 7.600 regels alle context bij iedere sessie, heb ik typisch 1-2 skills actief, dus 100-400 regels.
Als je dezelfde 5 instructies bij elke sessie inlaadt via SessionStart, en die instructies maar bij 1 op de 10 sessies relevant zijn, verplaats ze naar een skill. Drastische reductie van baseline-context.
Patroon 4, Ruis-detectie in je eigen werkproces
Eerlijk over jezelf: in welke vorm voeg jij ruis toe?
Drie vormen die ik bij mezelf heb herkend:
Ruisvorm 1, Te lange prompts met irrelevante achtergrond
Beginners schrijven prompts van 500 woorden waarin 50 woorden de eigenlijke taak zijn. De rest is "context" die niet helpt.
Fix: prompt schrijven, dan terug-editen tot het kortste mogelijke geheel-met-relevante-info. Vaak halveert dit de prompt-lengte.
Ruisvorm 2, Plakken van complete logs
"Hier is een error log, los het op." En je plakt 500 regels console output. 95% is buisluid.
Fix: plak alleen de relevante 10-20 regels rond de eigenlijke error. Of geef Claude een tool om het logfile zelf te zoeken.
Ruisvorm 3, Niet meer relevante eerdere context
Een lange chat-sessie waarin je 2 uur geleden iets bediscussieerde dat allang opgelost is. Die discussie zit nog steeds in context. Helpt nu niet meer.
Fix: start een nieuwe sessie als je wisselt van taak. Ook als de oude sessie nog open kan blijven. Schoon = sneller.
📖 Lees ook: Mijn AI-manager werd slechter naarmate ik langer met hem praatte: het concrete context-rot probleem dat auto-rotation oplost.
Patroon 5, Auto-rotation als laatste redmiddel
Als alle bovenstaande patronen toch niet voorkomen dat je context vol raakt: auto-rotation.
In mijn VNX systeem heb ik een hook die op 65% context-vulling automatisch een handover-document schrijft en een nieuwe sessie start. Geen handmatige actie nodig. Geen kennis-verlies, de handover bevat alle relevante voortgang.
De volledige uitleg staat in mijn #1-Google blog over context rot. Dit is het mechanisme dat me dagelijks 30-60 minuten bespaart aan handmatig sessie-management.
Dit is geen patroon voor beginners, dit is voor wie de eerste vier patronen al gebruikt en nog steeds tegen context-limieten loopt. Bij die schaal is auto-rotation noodzaak, niet luxe.
Een concreet voorbeeld
Hoe ik vandaag deze blog schrijf:
Slechte aanpak (2024-stijl):
- Open Claude Code
- Plak de hele content kalender (5K tokens)
- Plak de hele tone-of-voice gids (3K tokens)
- Plak alle bestaande blogs in deze serie (15K tokens)
- Plak de research-bronnen (4K tokens)
- Schrijf de prompt: "Schrijf een blog over context engineering, gebruik bovenstaande als referentie"
Resultaat: 27K tokens context vóór het schrijven begint. Ruis dominant.
Goede aanpak (2026-stijl):
- Open Claude Code in mijn blog-project
- SessionStart laadt alleen MEMORY.md (50 regels) en.claude/rules/tone-of-voice.md (90 regels)
- CLAUDE.md geeft project-context (40 regels)
- Schrijf prompt: "Schrijf de blog van 22 mei: context engineering. Lees indien nodig 2026-05-18 en 2026-03-09 als referentie."
Resultaat: 200 regels baseline context, plus selectieve referenties die Claude pas leest als hij ze nodig heeft. ~5K tokens vs 27K. Vijf keer zo schoon, hetzelfde resultaat, vaak beter, omdat Claude minder afgeleid wordt door irrelevante info.
Wat doe je deze week?
Drie acties:
- Audit je SessionStart-hook. Hoeveel tokens laadt hij? Lees het uit, log het, kijk wat erin zit. Vaak halveert je context-budget direct als je hem schoonmaakt.
- Schrijf één skill voor een taak die je dagelijks doet. Verplaats de instructies uit je generieke memory naar de skill. Skills laden on-demand.
- Probeer één sessie waarbij je bewust niets vooraf laadt. Begin schoon, laat Claude files lezen als hij ze nodig heeft. Vergelijk de output-kwaliteit.
Volgende week ga ik dieper op self-learning loops, hoe je AI-systeem zelf leert wat goede context is en wat ruis.
Veelgestelde vragen
Vijf patronen, één inzicht
Prompt engineering is achterhaald. Context engineering heeft het overgenomen. De grootste hefboom is niet welke woorden je gebruikt, maar wat de AI weet voordat je iets vraagt, en cruciaal: wat hij niet weet, omdat het ruis zou zijn.
Vijf patronen: selectief laden ipv alles laden, memory-tier-systeem, skills voor terugkerende context, ruisdetectie in je eigen werk, auto-rotation bij grote schaal.
In 2027 is dit standaard kennis. Wie nu begint heeft dit jaar voorsprong, vooral bij langlopende taken waar context-discipline echt het verschil maakt tussen werkbaar en frustrerend.
Heb je een specifieke context-uitdaging? Stel je vraag op LinkedIn, als ze veel voorkomen, beantwoord ik ze graag in een vervolgpost. Meer weten over hoe ik dit toepas bij MKB-klanten? Zie AI-architectuur.
Bronnen & referenties
- Prompt engineering is dood. Lang leve context engineering.
- Mijn AI-manager werd slechter naarmate ik langer met hem praatte: context rot in de praktijk
- CLAUDE.md is pas het begin: de drie configuratielagen die Claude Code een geheugen geven
- Top 10 Claude Code features
- Context Rotation at Scale, VNX implementation