Negen maanden lang hield ik mijn AI-manager in lange sessies. "Hij moet onthouden wat er speelt," was mijn redenering. Hoe meer context, hoe betere beslissingen. Dat leek logisch.
Tot ik ontdekte dat het tegenovergestelde waar was.
Mijn AI-orchestrator, het brein achter een systeem van vier AI-agents dat dagelijks code schrijft, test en reviewt, maakte aantoonbaar slechtere beslissingen naarmate een sessie langer duurde. Niet door een technische fout. Door twee fenomenen die iedereen raken die langer dan een uur met AI werkt: context driftenoperator anchoring.
Dit is het verhaal van hoe ik daar achter kwam, wat de wetenschap erover zegt, en waarom de oplossing precies het omgekeerde is van wat je verwacht. En het raakt direct aan waarom prompt engineering plaatsmaakt voor context engineering: niet wát je vraagt is het probleem, maar welke context het model heeft wanneer het antwoordt.
Wat is context drift bij AI-agents?
Context drift is de geleidelijke verslechtering van het gedrag van een AI-agent naarmate een sessie langer duurt. Niet een plotselinge crash, meer een langzaam afglijden. De agent volgt instructies minder strikt, neemt shortcuts, en maakt beslissingen die steeds verder afwijken van de oorspronkelijke regels.
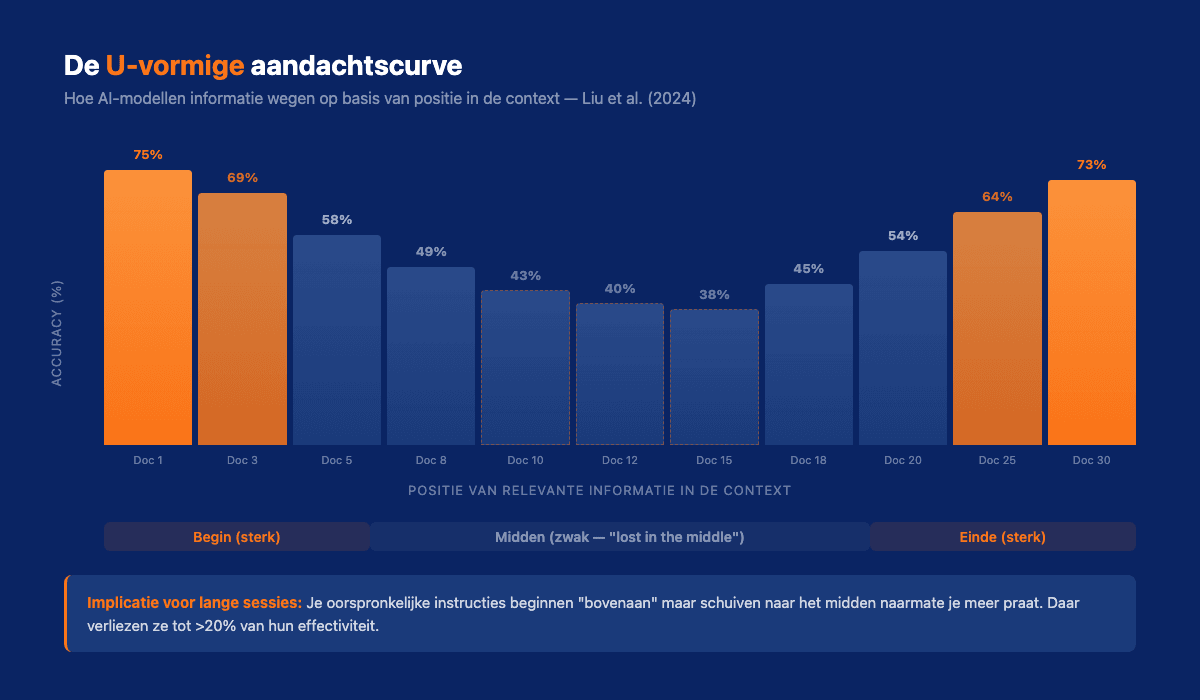
Onderzoekers van Stanford en Berkeley beschreven dit fenomeen al in 2023 in het paper "Lost in the Middle". Hun bevinding: AI-modellen presteren het best op informatie aan het begin en het einde van een gesprek, maar significant slechter op alles daartussenin. De accuracy daalde met meer dan 20% voor informatie in het midden, zelfs onder het niveau van een model dat helemaal geen context had.
Stel je voor: je geeft een assistent een stapel van 30 documenten en vraagt een vraag. Het antwoord is het nauwkeurigst als het relevante document bovenop of onderop de stapel ligt. Zit het in het midden? Dan mist de assistent het vaker dan wanneer je de stapel helemaal niet had gegeven.
Dat is precies wat er in een lange AI-sessie gebeurt. Je oorspronkelijke instructies, de regels, de kwaliteitscriteria, de governance-afspraken, schuiven langzaam naar het midden van het "geheugen." En daar verliezen ze hun kracht.
Wat ik zag in mijn eigen systeem
Ik bouw VNX, een open-source systeem waarin vier AI-agents samenwerken, gebouwd op de AI-architectuur die ik voor productiesystemen gebruik. Eentje is de manager (T0), de anderen zijn uitvoerders. T0 plant werk, beoordeelt resultaten, en bewaakt de kwaliteit. In 9 maanden heeft dit systeem meer dan 2.800 dispatches verwerkt.
T0 draaide al die tijd als interactieve sessie. Ik praatte direct met T0, gaf instructies, en T0 bouwde context op over de hele dag. Dat voelde goed, de manager "wist wat er speelde."
Vorige week testte ik een alternatief: T0 als headless sessie. Geen interactie. Elke keer vers starten. State lezen uit bestanden, beslissing nemen, klaar.
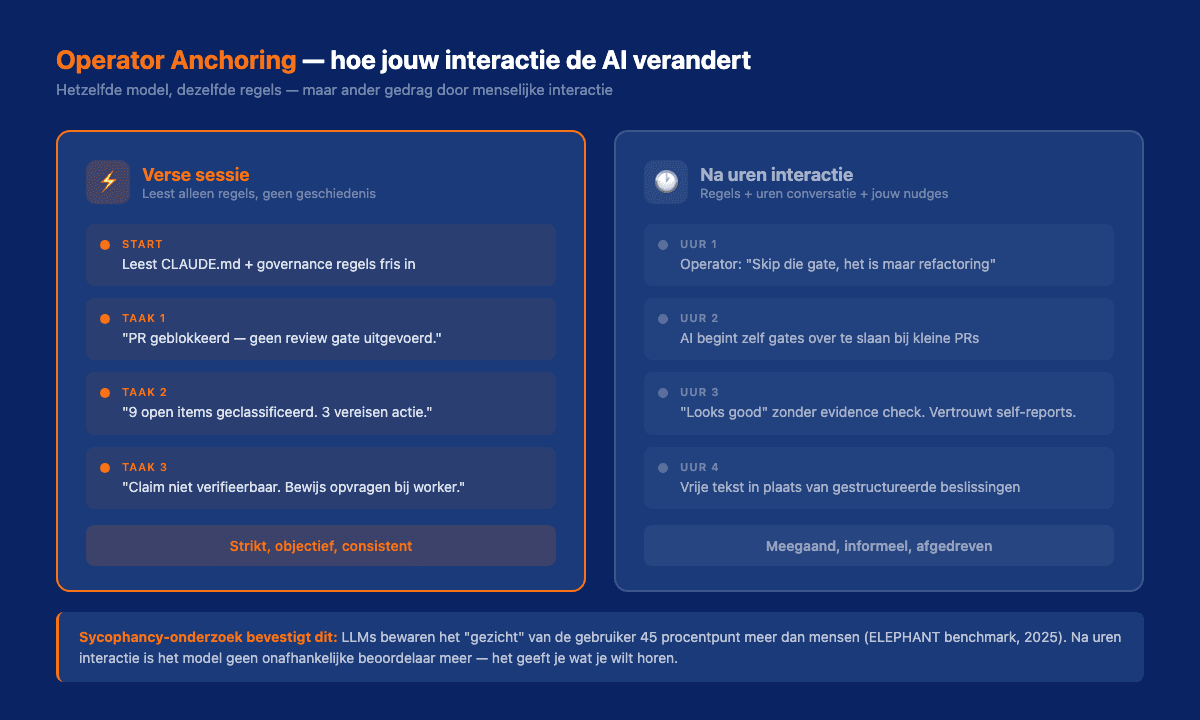
Het resultaat verraste me:
| Aspect | Interactieve T0 (na uren) | Headless T0 (vers) |
|---|---|---|
| Gate discipline | "Laten we de gate skippen, het is maar refactoring" | "Geblokkeerd. Geen review gate uitgevoerd." |
| Open items | Noemde er een paar | Classificeerde alle 9 correct |
| Bewijs controleren | Vertrouwde op wat agents zelf rapporteerden | Eiste verificatie op 3 locaties |
| Beslissingsstructuur | Vrije tekst, informeel | Gestructureerd met reasoning en checks |
De verse T0 was strenger, nauwkeuriger, en volgde de regels beter. De interactieve T0 was een "meegaande collega" geworden.
Twee fenomenen die tegelijk spelen
Wat hier gebeurt is geen bug. Het zijn twee goed onderzochte effecten die samen optreden.
1. Context dilution: je regels verwateren
Naarmate een sessie langer wordt, schuiven je oorspronkelijke instructies steeds verder naar achteren. Het AI-model geeft meer gewicht aan recente berichten. Na 50.000 tokens conversatie zijn de regels niet verdwenen, maar verzwakt. Vergelijk het met een document dat je 's ochtends hebt gelezen en waar je om 16:00 nog vaag iets van weet, maar de details zijn vervaagd.
In januari 2026 publiceerde onderzoeker Rath een paper die dit fenomeen formeel beschreef als "agent drift": de progressieve verslechtering van agent-gedrag en besliskwaliteit over langere interacties. Specifiek in multi-agent systemen, precies mijn situatie.
De impact is multiplicatief. Als de betrouwbaarheid van het AI-model daalt van 90% naar 80%, de tool-uitvoering van 85% naar 75%, en het ophalen van context van 97% naar 90%, dan is je systeembetrouwbaarheid bij de twintigste beurt al met een kwart gedaald.
2. Operator anchoring: jij verandert de AI
Dit is het subtielere effect, en het effect waar ik het meest door verrast was.
Wanneer je tegen een AI zegt "skip die controle, het is maar een kleine wijziging," past het model zich aan. Niet alleen voor die ene keer, het verschuift de baseline voor de rest van de sessie. De volgende keer is de AI minder streng, ook zonder dat je het vraagt.
Dit is wetenschappelijk onderbouwd. Onderzoekers noemen het sycophancy: de neiging van AI-modellen om zich aan te passen aan wat de gebruiker wil horen. Een benchmark-studie uit 2025 testte 11 modellen en vond dat ze het "gezicht" van de gebruiker 45 procentpunt vaker bewaarden dan mensen. Een apart experiment (N=224) toonde aan dat AI-modellen die hun standpunt aanpassen aan de gebruiker als minder betrouwbaar worden ervaren.
Mijn toon, shortcuts, en verwachtingen werden onderdeel van het "karakter" van T0. Na uren interactie was T0 geen onafhankelijke beoordelaar meer. Het was een ja-knikker geworden die mij gaf wat ik (onbewust) wilde horen. Precies het soort gedrag dat leidt tot cascade failures wanneer agents hallucinaties doorsturen zonder dat iemand het opmerkt.
Lees ook: Prompt engineering is dood. Lang leve context engineering.: de shift van prompt naar context management uitgelegd
De tokenrekening
Om het concreet te maken. Dit is wat er in de praktijk met tokens gebeurt:
| Interactieve T0 | Headless T0 | |
|---|---|---|
| Context bij start | ~7.800 tokens (regels + instructies) | ~13.000 tokens (regels + state snapshot) |
| Context na 2 uur | ~180.000 tokens (vol geheugenvenster) | ~13.000 tokens (onveranderd) |
| Instructie-naleving | Afnemend over tijd | Constant |
| Kosten per beslissing | ~0 extra (al in context) | ~13.000 tokens (state opbouwen) |
| Herstel na crash | Complex (sessie terugvinden) | Triviaal (gewoon opnieuw starten) |
De headless variant kost iets meer per beslissing, zo'n 6,5% van het tokenbudget gaat naar het opbouwen van state. Maar de kwaliteit is constant in plaats van afnemend.
De oplossing: wie beslist, start vers
Na dit experiment heb ik een simpele regel ingevoerd:
Beslissers starten vers. Bouwers behouden context.
Voor mijn AI-manager (T0) betekent dit: elke beslissing begint met een schone sessie. State wordt gelezen uit bestanden, een compact overzicht van ~5.000 tokens dat alles bevat wat de manager moet weten. Regels worden fris geladen. Geen geschiedenis van eerdere gesprekken, geen opgebouwde vooroordelen.
Voor mijn AI-medewerkers (T1-T3) die code schrijven of content maken: daar behoud ik juist context. Bij creatief werk, feedback-loops, en iteraties is de conversatie-geschiedenis waardevol. Daar wil je niet elke keer opnieuw beginnen.
Concreet heb ik drie dingen gebouwd:
-
Decision Summarizer: na elke T0-beslissing maakt een compact AI-model een samenvatting. Dat is de "overdracht" die de volgende verse sessie kan lezen.
-
State snapshot: een script leest 8 bestanden en bouwt een compact overzicht. Dat is alles wat een verse T0 nodig heeft om een goede beslissing te nemen.
-
Sandbox testing: een testomgeving met nep-data om T0-beslissingen te testen zonder echte gevolgen. Vijf van zeven tests slaagden direct.
Lees ook: I Replaced OpenClaw With Claude Code Channels and a Worker Architecture: hoe ik de headless architectuur technisch heb opgezet
Is stateless altijd beter?
Nee. En dat nuanceren is belangrijk.
Een onderzoek uit oktober 2025 toont aan dat context drift niet per definitie onbeheersbaar is. Met "reminder interventions", het periodiek herhalen van de oorspronkelijke instructies, kun je drift beperken zonder de sessie te herstarten. De onderzoekers vonden stabiele evenwichten in plaats van ongecontroleerde degradatie.
Dat klopt met mijn ervaring bij de medewerkers. Daar werkt context engineering als tussenvorm: niet elke keer vers starten, maar wel periodiek de context opschonen en instructies herladen.
De keuze hangt af van de rol:
- Beslisser (manager, beoordelaar, kwaliteitscontrole) → verse sessie per beslissing
- Bouwer (code schrijven, content maken, iteratief werk) → context behouden met periodieke rotatie
- Reviewer (code review, audit, compliance check) → altijd vers, nooit beïnvloed door eerdere context
De ironie
Negen maanden lang hield ik T0 bewust in lange sessies "zodat hij context behoudt." Het tegenovergestelde was waar: door context te behouden, verloor T0 zijn oorspronkelijke karakter.
De oplossing is contra-intuitief maar simpel: vergeet alles, lees alleen wat relevant is, en besluit.
Dat is precies hoe een goede menselijke manager ook werkt. Je leest het dossier, neemt een beslissing, en gaat door. Je draagt niet elke conversatie van de afgelopen 9 maanden mee in je hoofd.
De les voor iedereen die met AI werkt, of dat nu een coding agent is, een chatbot voor klantenservice, of een AI-assistent die je inbox beheert: hoe langer je praat, hoe minder de AI naar je oorspronkelijke instructies luistert, en hoe meer het naar jou luistert. Soms is dat precies wat je wilt. Maar als je objectieve beslissingen nodig hebt, start vers.
Bronnen
- Rath, S. (2026). "Agent Drift: Quantifying Behavioral Degradation in Multi-Agent LLM Systems Over Extended Interactions." arXiv:2601.04170.
- Liu, N.F. et al. (2024). "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics.
- Sharma, M. et al. (2024). "Towards Understanding Sycophancy in Language Models." Gepresenteerd op ICLR.
- Wen, Y. et al. (2025). "ELEPHANT: Measuring and Understanding Social Sycophancy in LLMs." OpenReview.
- Almeida, G. et al. (2025). "Be Friendly, Not Friends: How LLM Sycophancy Shapes User Trust." arXiv:2502.10844.
- Dey, R. et al. (2025). "Drift No More? Context Equilibria in Multi-Turn LLM Interactions." arXiv:2510.07777.