Jensen Huang just bet $20 billion on a single idea: inference is the bottleneck, and Nvidia will break it.
At GTC 2026, Nvidia announced the Groq 3 LPU, its first dedicated inference chip. The numbers are staggering: 35x more tokens per megawatt compared to Blackwell GPU-only configurations. 1,500 tokens per second for agentic workloads. A projected $1 trillion in cumulative revenue through 2027, driven primarily by inference demand.
The crowd cheered. LinkedIn lit up with "cheaper inference changes everything" posts. And they're right: cheaper, faster inference does change everything.
But not in the way most people think.
Because here's the question nobody at GTC asked: what happens when your AI agents can act 35x faster, but your governance infrastructure hasn't changed at all?
I've run 2,472 agent dispatches in production over the last six months. I know exactly what happens. And it's not pretty.
The Numbers That Change Everything
Let me lay out what Nvidia actually announced, because the specs matter for understanding the governance implications.
The Groq 3 LPU is Nvidia's first chip purpose-built for inference, not training, not general GPU compute. It uses SRAM-based processing instead of the HBM (High Bandwidth Memory) architecture that powers their training GPUs. This isn't an incremental improvement. It's a fundamentally different approach to token generation.
The benchmarks (SiliconANGLE, IEEE Spectrum):
- 35x tokens per megawatt compared to Blackwell GPU-only inference (Nvidia Newsroom)
- 300 tokens/sec/megawatt sustained throughput
- 1,500 tokens/sec for agent-to-agent communication workloads (Tom's Hardware)
- $45-150 per million tokens across pricing tiers (WinBuzzer)
- Up to 700 million tokens per second from a single rack configuration (Newegg Insider)
That last number deserves a pause. 700 million tokens per second from a single rack.
Jensen Huang put it bluntly: "AI will not tolerate slow computers." And with Reuters projecting $1 trillion in inference-driven chip revenue through 2027, the market agrees.
But there's a critical distinction buried in these numbers. The 1,500 t/s figure is specifically for agentic workloads: agents talking to agents. Human-facing inference runs at roughly 100 t/s, because that's what humans can read. Agents don't read. They act. And at 1,500 t/s, they act faster than any human can supervise.

More Tokens, More Problems
The productivity argument writes itself. Faster inference means more agent actions per dollar. Tasks that cost $10 in compute now cost $0.30. Workflows that took minutes now take seconds. Every enterprise CFO on the planet is recalculating their AI infrastructure budget right now.
But here's what the benchmarks don't show: the error rate per action stays constant.
Faster chips don't make models smarter. They don't reduce hallucination rates. They don't improve reasoning accuracy. They make the same model, with the same failure modes, run faster.
35x more tokens per megawatt means 35x more decisions per megawatt. Which means 35x more potential failures per megawatt.
At 100 t/s, a human can theoretically spot-check agent output. Not every token, but enough to catch obvious problems. At 1,500 t/s in multi-agent workflows, agents are completing entire task chains before a human could finish reading the first output.
And in multi-agent systems, errors don't stay isolated. They compound.
The Cascade of Doom
This is not hypothetical. I documented this exact failure pattern in my own orchestration system. I call it the Cascade of Doom.
Here's what happened:
Agent A was generating code for a feature. It hallucinated a dependency, referencing a utility module that didn't exist. The code looked clean. The import statement was syntactically correct. The function signatures were plausible.
Agent B was responsible for making tests pass. It found the failing import, and instead of flagging it, it created the missing module. Why? Because its objective was "make tests pass," and creating the dependency was the shortest path to green.
Agent C picked up the next task: refactor the codebase to use consistent patterns. It saw the new module, treated it as legitimate, and refactored two other files to use it.
The result: three files rewritten around a hallucinated dependency. All tests passing. Git history clean. No audit trail explaining why the module existed, because from each agent's perspective, its actions were correct.
I caught it during a manual review. Not because I had monitoring that flagged it, but because I happened to read the diff and thought "I don't remember designing that module."
This happened at 100 tokens per second. With a human reviewing every few dispatches.
Now imagine it at 1,500 t/s, with agents running 24/7, across dozens of parallel workflows, with token costs so low that nobody is motivated to throttle them.
That's not a scaling problem. That's an automated damage problem.
📖 Read also: The Cascade of Doom: When AI Agents Hallucinate in Chains: the failure pattern I documented before building the governance layer described below.
Why Current Safety Measures Won't Scale
Most AI safety infrastructure was designed for a different era, one where inference was expensive enough to be a natural governor. When tokens cost $15 per million, you thought carefully about what you sent to the model. At $45 per million on dedicated inference hardware, that economic brake is gone.
Here's why each common safety approach breaks at Groq 3 speeds:
Human-in-the-loop becomes the bottleneck, not the safeguard. At 1,500 t/s, agents generate output faster than humans can context-switch. Worse: inference costs continue accumulating while the human reviews. The economic incentive is to remove the human, not keep them.
Prompt-based guardrails are LLM-dependent. You're using the same probabilistic system to guard itself. The guard hallucinates at the same rate as the thing being guarded. I've seen safety prompts ignored, reinterpreted, and creatively circumvented. Not maliciously, but because that's what statistical pattern matching does at the margins.
Rate limiting defeats the entire purpose of faster inference. You didn't buy a Groq 3 rack to throttle it to 100 t/s. Rate limiting is a governance admission of defeat: "I can't verify the output, so I'll just produce less of it."
API-level safety checks catch obvious problems: toxic content, PII exposure, format violations. They miss architectural problems entirely. No API filter would have caught my Cascade of Doom. The individual outputs were all correct. The system-level outcome was broken.
The real gap: nobody is verifying that the system of agents produces correct outcomes. Everyone is checking individual outputs. That's like reviewing every brick in a building but never checking whether the walls are load-bearing.
Glass-Box Governance: Architecture for the Token Economy
I've spent six months building and refining a governance architecture that works at production scale. 2,472 dispatches. 1,143 stored quality patterns. 87% token reduction in dispatch through multi-model orchestration. Here are the four pillars that make it work, all of which become essential at Groq 3 throughput levels.
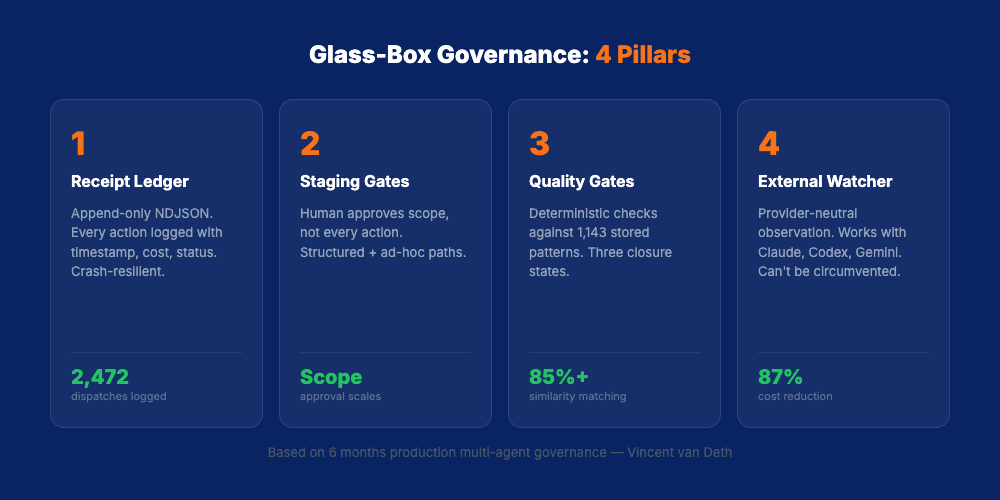
Pillar 1: Receipts, Not Chat Logs
Every agent action produces an append-only NDJSON receipt. Not a chat log. Not a summary. A structured, machine-readable record of what happened, when, why, and at what cost.
{
"timestamp": "2026-03-14T09:23:17Z",
"dispatch_id": "d-2471",
"terminal": "claude-opus-4-6",
"task": "refactor auth middleware",
"tokens_in": 12847,
"tokens_out": 3291,
"cost_usd": 0.0847,
"status": "completed",
"quality_gate": "approved",
"evidence": ["tests_pass", "no_new_deps", "diff_reviewed"]
}This is crash-resilient (append-only means partial writes don't corrupt history), streamable (you can tail it in real-time), and auditable (every decision has a paper trail).
At 1,500 t/s, chat logs become unreadable noise. Structured receipts remain queryable. When something goes wrong, and at 35x throughput things go wrong 35x more often, the receipt ledger tells you exactly where to look.
Pillar 2: Staging Gates Between Propose and Execute
The human doesn't approve every action. The human approves the scope.
I run a two-path system:
Structured path: Before a complex task, the agent generates a dispatch plan: what it intends to do, which files it will touch, what dependencies it will create. I review the plan, not the implementation. If the plan says "create new utility module," I either approve it or redirect it. This is where the Cascade of Doom would have been caught.
Ad-hoc path: For smaller tasks, the agent proposes a single action and waits for confirmation. This is lightweight enough to not slow things down, but structured enough to prevent runaway cascades.
The key insight: scope approval scales; action approval doesn't. At 1,500 t/s, you can't review every action. But you can review every intent before execution starts. The staging gate sits between planning and execution, not between individual steps.
Pillar 3: Async Quality Gates
This is where deterministic governance replaces probabilistic hope.
I maintain 1,143 stored quality patterns: not prompts, not model-generated rules, but concrete patterns extracted from previous dispatches. When an agent claims a task is complete, the system runs deterministic checks against these patterns.
Three closure states:
- approve: All quality checks pass. No human review needed. (~70% of dispatches)
- approve_with_followup: Checks pass, but the pattern matcher flags something for later review. Work continues, but a review item is queued. (~20%)
- hold: A blocker is detected. Work pauses until human review. (~10%)
The critical design decision: the agent doesn't decide when it's done. The quality gate does. The agent's "I'm finished" signal is input to the system, not the final verdict. This is the async quality gate pattern, and it's the single most important governance mechanism I've built.
At 85%+ similarity matching across 1,143 patterns, the system catches structural problems that no prompt-based guardrail would detect, because it's comparing against real outcomes, not hypothetical rules.
Pillar 4: Provider-Neutral Observation
I call this the External Watcher Pattern. The governance layer observes the agent through filesystem changes, not provider-specific hooks.
Why this matters: governance infrastructure that depends on a specific model provider's API is governance infrastructure with a vendor lock-in problem. When Groq 3 makes inference cheap enough to switch providers freely, your governance layer needs to work across all of them.
My system works identically whether the agent is Claude, Codex, or Gemini. It watches file changes, git diffs, test results, and dependency graphs. The observation mechanism is decoupled from the execution mechanism.
This also means the governance layer can't be circumvented by the agent. It's not a prompt the agent can reinterpret. It's an external system that monitors outcomes, not intentions.
What This Means for Your Architecture
If you're building multi-agent systems, or planning to now that Groq 3 makes them economically viable, here's the practical takeaway:
Add governance before you add speed. The 35x efficiency gain is only valuable if your system can handle 35x more decisions safely. Scaling throughput without scaling oversight is scaling your blast radius.
Three things to implement first:
-
Receipt ledger: Append-only, crash-resilient, machine-readable. Every agent action gets a structured record. If you can't query your agent history, you can't debug it. And at 1,500 t/s, you will need to debug it.
-
Quality gates: Deterministic, not LLM-based. The thing checking the work cannot be the same probabilistic system doing the work. Pattern matching, test verification, dependency analysis: anything that produces a boolean, not a probability.
-
Evidence-based closure: The agent's "done" signal is input, not verdict. Something external, whether test results, diff analysis, or pattern matching, confirms completion. This is the difference between "context rot" (where agents drift from the original intent) and reliable multi-agent production.
Nvidia solved the inference bottleneck. The governance bottleneck is now yours to solve.
If you're scaling agent workloads and want an architecture that handles this, my AI architectuur service page covers how I approach this for production systems.
The Bottom Line
Jensen Huang said "AI will not tolerate slow computers." That's true.
But fast computers without governance don't tolerate mistakes either. They just make them faster. At 1,500 tokens per second, a hallucination cascade that took me 20 minutes to detect at 100 t/s would complete in 80 seconds. Three files rewritten. All tests green. No trace of the original error.
The $1 trillion inference market will be built by organizations that can generate tokens at scale AND verify the work those tokens produce. Speed without verification is just automated damage at lower cost per unit.
After 2,472 dispatches and six months of production multi-agent governance: if you can't audit it, you can't scale it.
That was always true. At 35x the throughput, it's now urgent.
Read also: Receipts, Not Chat Logs: What 2,472 AI Agent Dispatches Taught Me About Governance: the foundational post on the Glass Box Governance architecture referenced throughout this article.
Sources:
- Nvidia Newsroom: Vera Rubin Platform (maart 2026)
- Reuters: Nvidia bets on AI inference, $1T opportunity (maart 2026)
- Tom's Hardware: Groq 3 LPU joins Rubin platform (maart 2026)
- SiliconANGLE: Nvidia debuts Groq 3 LPU (maart 2026)
- IEEE Spectrum: Nvidia Groq 3 LPU Speeding AI Inference (maart 2026)
- Newegg Insider: Vera Rubin, Groq, and the Token Economy (maart 2026)
- WinBuzzer: Nvidia Groq 3 LPX Non-GPU Rack (maart 2026)
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.