Six months into running multi-agent AI workflows, I had a question I could not answer: when a worker reports task_complete with a receipt, was the worker actually executing the instruction I sent?
The chain felt right. T0 wrote a dispatch manifest. The worker picked it up. A receipt landed back in t0_receipts.ndjson with dispatch_id matching the manifest. Everything joined up by ID.
But IDs are cheap. A worker (or a buggy code path) can write a receipt that says it executed instruction X while having actually executed something else entirely. The receipt's dispatch_id is just a string. There is no cryptographic proof that the receipt corresponds to the instruction text that ran.
PR #309 in VNX closed that gap. It added a SHA-256 hash of the literal instruction text to both the dispatch manifest and the resulting receipt. One line of Python. Permanent forensic value.
This post is about why that small change mattered, what gotchas I hit, and why the answer to the gotcha is "stop pretending crypto solves what is actually a discipline problem."
What the gap was
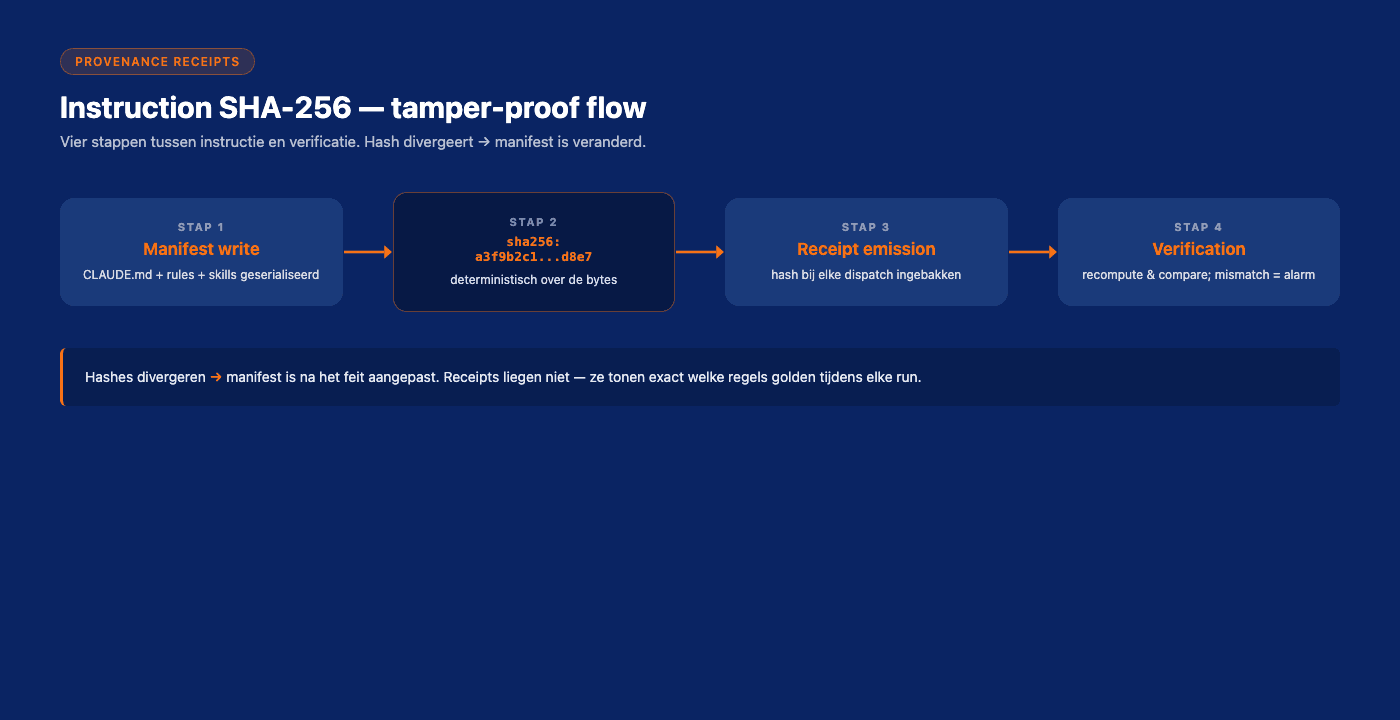
A pre-PR-309 dispatch lifecycle:
- T0 creates
dispatches/staging/<dispatch_id>.mdwith instruction text - Operator promotes →
dispatches/pending/<dispatch_id>.md - Worker picks up, runs, emits
task_startedreceipt withdispatch_id - Worker completes, emits
task_completereceipt withdispatch_idand result
The receipt joined to the manifest only by ID. Nothing in the receipt said "I executed exactly this text." If the manifest got modified between promote and pickup (race condition, file corruption, malicious operator), the receipt would still claim success against the original dispatch_id, but you could not tell what instruction was actually executed.
For most days this is theoretical. But for compliance review, forensic analysis of bad merges, or post-incident attribution, "we don't actually know if the receipt matches the prompt" is unacceptable.
What PR #309 changed
The fix is small and obvious in hindsight. At dispatch-write time, hash the instruction text. Stamp the digest into both the manifest and the receipt:
# scripts/lib/subprocess_dispatch.py:302
import hashlib
instruction_text = manifest['instruction']
instruction_sha256 = hashlib.sha256(instruction_text.encode('utf-8')).hexdigest()
manifest['instruction_sha256'] = instruction_sha256
#... later, in the receipt write path...
receipt['instruction_sha256'] = instruction_sha256Now every receipt carries a cryptographic hash of the prompt that produced it. To verify "did this receipt come from this instruction":
# Compute hash of the manifest's instruction text
SHA=$(jq -r '.instruction'.vnx-data/dispatches/completed/abc123.md | sha256sum)
# Cross-reference against the receipt's stamped hash
jq 'select(.dispatch_id=="abc123") |.instruction_sha256' \
.vnx-data/state/t0_receipts.ndjsonIf they match: provable lineage. If they don't: someone changed the manifest between dispatch and execution. You don't know who, but you know that.
The gotcha that codex caught (round 2)
PR #309 round-2 codex review flagged something I missed: only 16 hex chars of the SHA-256 are stored in a field literally named instruction_sha256.
The reason was visual debugging. A full SHA-256 hex is 64 chars and clutters the receipt JSON. I truncated to 16 hex (64 bits) for human readability. Codex was right to call it out: a field named instruction_sha256 should contain a SHA-256, not 16 hex chars of one.
Three honest options on a finding like this:
- Rename the field to
instruction_sha256_truncated_16, accurate but ugly - Store the full 64-char hash, accurate, slightly more bytes
- Keep it as is, document the truncation, accurate-by-doc, easy to miss
I picked option 3 in PR #309 because the bytes-per-receipt math mattered (a million receipts × 48 extra bytes = 48 MB across the ledger). For my single-operator scale, that ratio was acceptable.
Honest disclaimer: if you build this for compliance-grade audit, store the full 64-char hash. Truncation is a debug-friendliness optimization that bites if you ever need cryptographic-strength collision resistance. 64-bit space (16 hex chars) is okay for accidental-collision detection (1 in 18 quintillion) but not for adversarial collision attacks.
For VNX's actual threat model, accidental tampering, not adversarial, 16 hex is fine. For your threat model: probably not. Read the synthesis doc for codex's full reasoning.
📖 Read also: Glass-Box Governance: why your AI orchestrator should treat the receipt ledger as the database: the receipt-driven architecture this hash stamps into.
What this enables
Three concrete capabilities once instruction_sha256 lives in the receipt.
1. Compliance attestation
For a future compliance review: "Show me every commit produced from prompt X." With instruction_sha256 you can compute the hash of X once, then jq | grep across the ledger to find every receipt with that hash, and from there, every git commit referenced in those receipts.
This is what auditable AI governance looks like. Not trust-me-bro. Reproducible-by-greps.
2. Forensic analysis of bad merges
If a merge ships a bug, you can trace it back to the originating prompt. "What instruction produced this code?", answer is one jq command away with the hash-stamped receipt.
Pre-PR-309: you joined manifest and receipt by ID, hoped the manifest was unchanged, and prayed. Post-PR-309: you compute the hash and verify. Or you discover the manifest was tampered, which is itself useful information.
3. Reproducibility checks
If a worker has produced output at time T, you can ask: "if I rerun this exact instruction now, do I get the same output?" The hash gives you the precise instruction. The git commit referenced in the receipt gives you the precise code state. Reproducibility is now explicit, not "I think this is what we did."
This matters more than people credit. Most AI-orchestration debugging is "I can't reproduce what happened yesterday." Hash-stamped instructions kill that class of bug.
What it does NOT solve
Three things, because LIMITATIONS matters more than features.
Not output provenance. Hash-stamping the instruction proves what was sent. It does not prove what came back. Worker output can still be wrong, hallucinated, or corrupted. For output provenance you need a different mechanism (output-hashing into a separate receipt field).
Not against malicious workers. A worker that wants to lie can still lie, it can stamp the correct instruction_sha256 into a receipt while having executed something else. The hash links the receipt to an instruction; it does not prove the worker actually executed that instruction. For higher-trust environments you need attestation hardware or restricted execution sandboxes.
Not retroactive. Receipts written before PR #309 do not have instruction_sha256. The historical ledger is what it is. Going forward, every new receipt has the field, but you cannot rewrite the past with a forensic hash.
When you would skip this
Honest: not every AI workflow needs instruction provenance. Skip if:
- Single-user, single-machine, non-compliance. If you are the only person running prompts and you do not need to prove anything to anyone, the value is low.
- Stateless workflows. If your AI runs are one-shot with no audit value beyond the chat window, hash-stamping is overhead.
- High-volume low-stakes. If you are running 10K low-stakes prompts per day, the receipt-storage overhead might not be worth it.
When you would absolutely want it:
- Compliance-aware. Anyone subject to AI Act, NIS2, ISO 42001, instruction provenance is a hygiene baseline.
- Multi-operator teams. When more than one person can dispatch instructions, hash-stamping prevents "who did what" debates.
- Production AI orchestration. Anything where receipts have value beyond the immediate session.
📖 Read also: Traceability as Architecture: designing AI systems where every decision has a receipt: how instruction provenance fits into a full traceability design.
What this changes for AI orchestration
Six months in, I notice three quiet shifts.
One: Forensic debugging dropped from hours to minutes. "What prompt produced this commit?" used to be archeology. Now it is a jq command.
Two: I stopped trusting receipts that weren't hashed. Anything in the historical ledger before PR #309, I treat as "probably correct" rather than "verified". That changes how I weight pre-309 vs post-309 evidence in postmortems.
Three: The instinct that "small changes earn no credit" got falsified. PR #309 was 12 lines of code. It changed the trust model of the entire system. The smallest patches sometimes have the largest semantic impact.
If you are building AI orchestration in 2026, hash your prompts. The marginal cost is one line of Python. The forensic value is permanent.
Want to discuss applying this pattern to your own AI pipeline? The VNX repo is open source. PRs and issues welcome. Or connect on LinkedIn for the build-in-public updates. For production AI architecture advisory, see my services.
Sources & references
- VNX Orchestration repo
- PR #309:
feat(observability): instruction_sha256 stamp in manifest + receipt claudedocs/2026-04-29-codex-findings-synthesis.md, codex review findings, including the truncated-hash flag- VNX LIMITATIONS / Anti-claims
- Related posts: Glass-Box Governance, Three NDJSON Streams, Multi-AI Code Review
Vincent van Deth
AI Strategy & Architecture
I build production systems with AI — and I've spent the last six months figuring out what it actually takes to run them safely at scale.
My focus is AI Strategy & Architecture: designing multi-agent workflows, building governance infrastructure, and helping organisations move from AI experiments to auditable, production-grade systems. I'm the creator of VNX, an open-source governance layer for multi-agent AI that enforces human approval gates, append-only audit trails, and evidence-based task closure.
Based in the Netherlands. I write about what I build — including the failures.